[arXiv](2024/01/23 version v1)
Abstract
전체 프레임을 한 번에 생성하는 Space-Time U-Net을 통해 시간적으로 일관된 비디오 생성
Lumiere
STUNet을 통해 모든 프레임을 한 번에 생성하고 MultiDiffusion을 통해 super-resolution 한다.
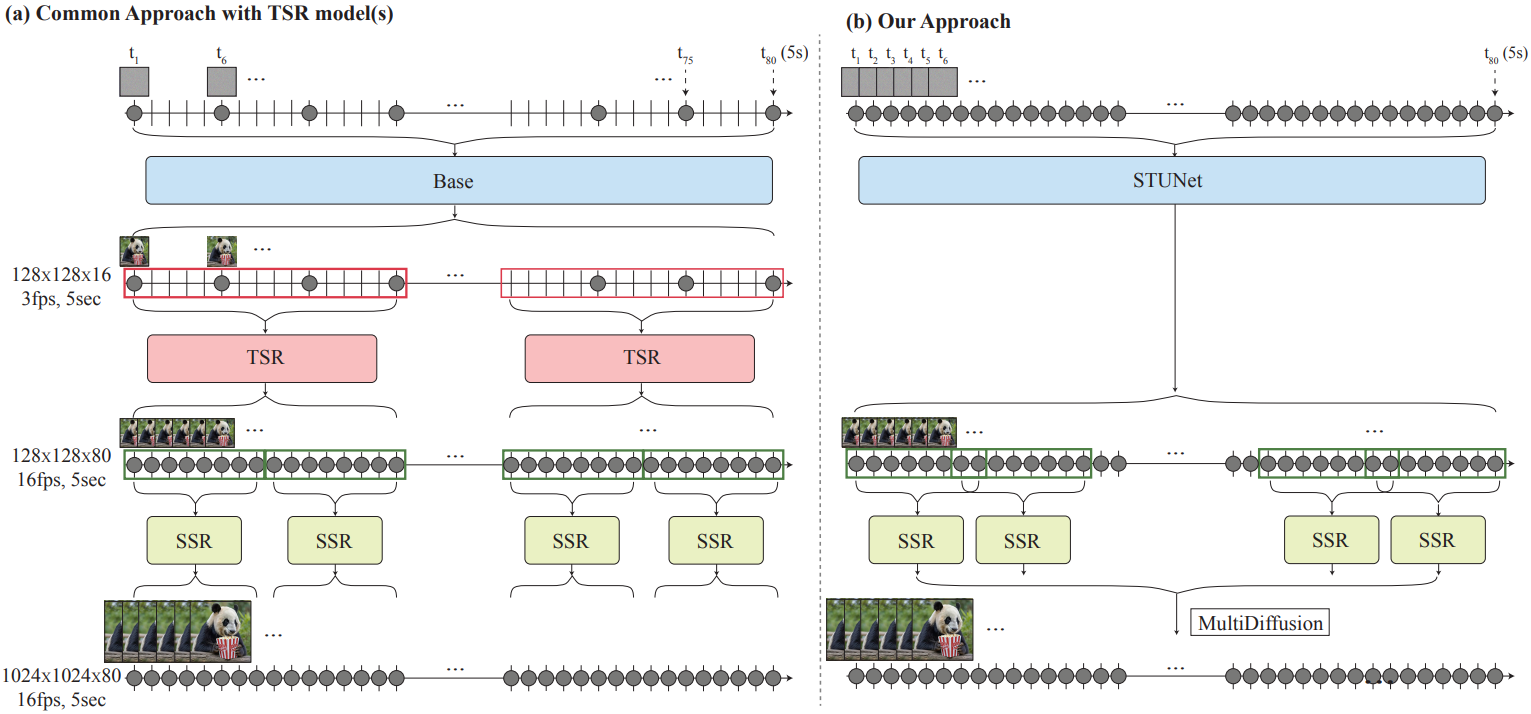
Space-Time U-Net (STUnet)

사전 훈련된 spatial layer 뒤에 factorized space-time convolution(2D + 1D)을 사용함으로써 3D conv에 비해 계산상의 이점을, 1D에 비해 표현력의 이점을 챙긴다.
Temporal attention은 계산 비용이 높으므로 가장 낮은 해상도에서만 사용한다.
일반적인 T2V 연구와 비슷하게 사전 훈련된 공간 모듈은 고정하고 새로 추가된 피라미터만 훈련한다.
Multidiffusion for Spatial-Super Resolution

생성된 비디오를 중첩된 i segments로 나누고 시간축을 따라 MultiDiffusion을 적용한다.
MultiDiffusion은 개별 denoising의 중첩된 결과를 최적화를 통해 근사하는 방법이다. 해당 논문에서는 복잡한 마스크를 반영하기 위해 이러한 방법을 사용했지만, 본문에서는 temporal boundary artifact를 줄이기 위해 사용했다고 한다.
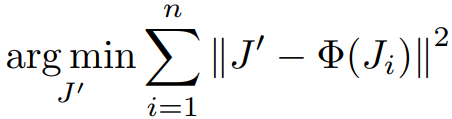
Applications
Stylized Generation
T2I 가중치를 고정했기 때문에 개인화된 T2I 가중치로 교체하면 원하는 스타일의 이미지를 생성할 수 있다. 하지만 이러한 "plug and play" 접근 방식이 정적인 비디오를 생성하거나 왜곡할 수 있으며, 이는 temporal layer의 입력 분포의 차이에서 발생한다.
따라서 fine-tuned T2I 모델과 original T2I 모델의 가중치를 선형 보간한다.


Conditional Generation
Masked conditioning video C와 binary mask M을 추가하여 T×H×W×3 → T×H×W×7로 확장(J, C, M)하고 첫 번째 conv layer의 채널 차원 또한 확장한다. 이렇게 하면 특정 부분에만 애니메이션을 적용하는 방법을 학습할 수 있다.
Image-to-Video
C의 첫 번째 프레임에 이미지를 제공하고 첫 번째 프레임만 1인 M을 제공한다.

Inpainting
사용자 제공 비디오 C, 인페인팅 마스크 M

Cinemagraphs
C는 모든 프레임에서 복제된 사용자 제공 이미지.
형태를 유지하기 위해 첫 번째 프레임의 마스크는 0으로 하고 이후 프레임에서는 특정 부분에만 1.

Evaluation
Lumiere - Google Research
Space-Time Text-to-Video diffusion model by Google Research.
lumiere-video.github.io



