[arXiv](2024/01/31 version v2)
Abstract
모션 예측과 비디오 생성을 분리하여 명시적인 모션 모델링이 가능한 Motion-I2V 제안
Keyword: Optical flow, Motion-augmented temporal layer, ControlNet
Method

Motion Prediction with Video Diffusion Models
Motion fields modeling
모션 필드로써 optical flow를 채택.
Training a motion field predictor
3단계 fine-tuning 전략:
- 사전 훈련된 LDM을 참조 이미지와 text prompt를 통해 모션 필드를 예측하도록 fine-tuning.
- LDM을 고정하고 시간 모듈을 추가하여 훈련.
- 전체 VLDM을 fine-tuning.
Encoding motion fields and conditonal image
모션 필드는 optical flow VAE encoder를 사용하여 인코딩되며 참조 이미지의 잠재 코드를 채널 차원에 추가한다.
또한 motion strength를 timestep embedding에 추가.
Video Rendering with Predicted Motion
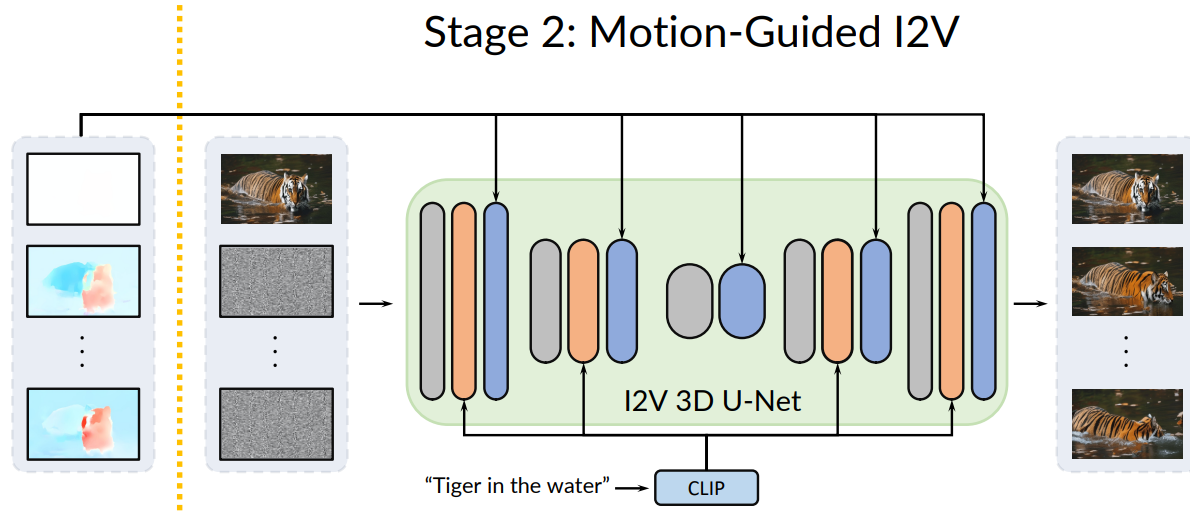
Motion-augmented temporal attention
입력 latent의 첫 번째 프레임을 z[0], 나머지 프레임을 z[i] 이라고 하자.
또한 이전 작업에서 얻은 모션 필드를 통해 z[0]를 warping 한 feature map은 z[i]' 이다.

또한 zaug = [z[0], z[1]′, z[1], …, z[N]′, z[N]].
차원을 재구성한 z': (1+N)×C×h×w → (h×w)×(1+N)×C, 또한 zaug → zaug'.
그리고 z, zaug에 위치 인코딩을 추가하여 시간적 순서를 인식할 수 있도록 한다.
1-D temporal attention:
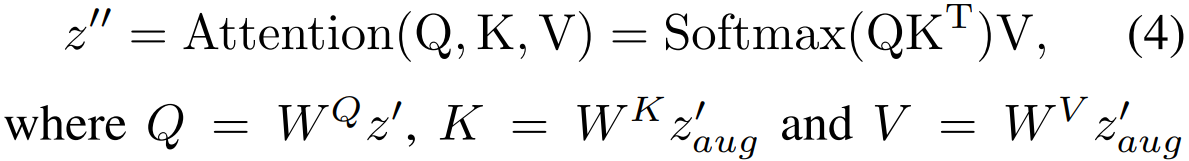
Selective noising
모든 timestep t에서 항상 참조 이미지의 잠재 코드를 시간 축을 따라 연결한다.
Fine-grained Control of Motion-I2V Generation
Sparse Trajectory Guided I2V
 |
 |

ControlNet을 사용하여 모션 필드를 조작.
3D Conv network를 사용하여 mask m과 fsparse의 연결을 인코딩하고 ControlNet에 입력한다. 자세한 사항은 supplementary를 참고하라는데 아직 안 나온 듯?
Region-Specific I2V
똑같이 ControlNet 활용.
 |
 |
Zero-Shot Video-to-Video Translation
두 번째 단계의 첫 번째 프레임을 원하는 style/content로 변경.
 |
 |
 |
Experiments
LDM은 Stable Diffusion v1.5, VLDM은 AnimateDiff v2 채택.
Motion-I2V
We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit
xiaoyushi97.github.io



