[Github]
[arXiv](2023/10/10 version v2)

Abstract
LLM이 layout을 생성하여 diffusion model을 안내하는 LLM-grounded Diffusion (LMD) 제안
LLM-grounded Diffusion
LLM-based Layout Generation

Layout representation
레이아웃 표현은 bounding box와 caption으로 구성된다.
Prompting

In-context learning
레이아웃 표현을 명확히 하기 위해 작업 설명 후 수동으로 선별한 예제를 제공한다.

2가지 원칙:
- 각 인스턴스는 단일 bbox로 표시된다. E.g. '사과 4개'의 경우 각 사과가 각기 다른 bbox를 가진다.
- Foreground object는 background caption에 포함되지 않는다.
Layout-grounded Stable Diffusion
LMD는 먼저 개별 bbox에 대해 masked latent를 생성한 다음 전체 이미지를 구성함으로써 인스턴스 수준의 grounding이 가능.
Per-box masked latents

Prompt “[background prompt] with [box caption]”으로 각 개체 i에 대한 이미지를 생성하며, 초기 잠재 xTi는 스타일 일관성을 위해 모든 개체에 공유된다. (잠재 공간이라 z인데 이미지에는 x라고 표기돼 있어서 대충 z = x라고 생각하셈)
개체와 bbox의 정렬을 위해 bbox 영역 u의 마스크 m, 개체의 prompt token index v, 영역 내의 Topk 평균에 대해 각 denoising step 전에 다음과 같은 에너지 함수로 cross-attention map 업데이트를 수행한다.
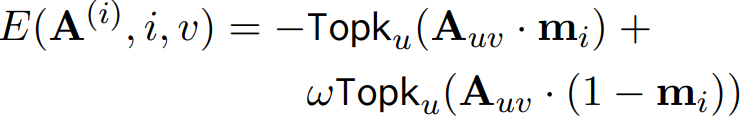

생성 후 Segment Anything Model을 통해 각 step에서 개체의 영역을 얻는다.
Composed image generation

Background 또한 같은 잠재 노이즈에서 시작하며 각 개체의 영역은 이전에 생성한 노이즈로 대체된다.
또한 cross-attention map 업데이트 수행:
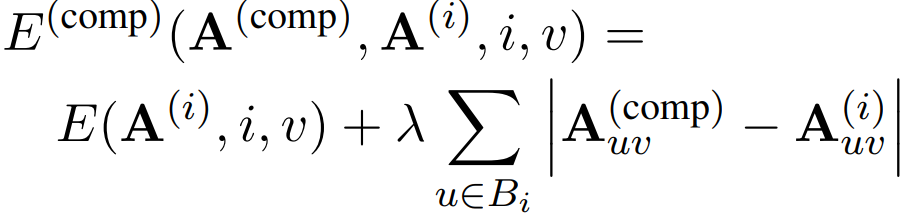
각 개체의 배치는 denoising step의 초기에 이루어지기 때문에 이 모든 과정은 rT step까지만 사용한다.





