계층적 ViT 모델에 Masked Image Modeling을 도입한 논문이다. 5월 26일 공개되었다. 요즘 이런 비슷한 주제의 논문이 많이 나오는 것 같다.
GitHub - LayneH/GreenMIM: Official implementation of the paper 'Green Hierarchical Vision Transformer for Masked Image Modeling'
Official implementation of the paper 'Green Hierarchical Vision Transformer for Masked Image Modeling'. - GitHub - LayneH/GreenMIM: Official implementation of the paper 'Green Hierarchi...
github.com

Abstract
계층적 ViT를 사용한 MIM(Masked Image Modeling)을 위한 효율적인 접근 방식을 제시한다. 본 논문의 접근 방식은 두 가지 핵심 요소로 구성된다. 첫째, window attention을 위해 Divide-and-Conquer 전략에 따라 group window attention 체계를 설계한다. 둘째, 동적 프로그래밍 알고리즘을 통해 그룹화 전략을 더욱 개선하여 그룹화된 패치에 대한 attention의 전체 계산 비용을 최소화한다. 그 결과, MIM은 이제 친환경적이고(?) 효율적인 방식으로 계층적 ViT에서 작업할 수 있다. 본 논문에서 제안하는 모델은 계층적 ViT를 약 2.7배 더 빨리 훈련하고 GPU 메모리 사용을 70% 줄이는 동시에 경쟁력 있는 성능과 다운스트림 작업에서 우월성을 누릴 수 있다.
Introduction
Masked Auto-encoder(MAE)로 대표되는 MIM(Masked Image Modeling)은 유망한 자체 감독 사전 훈련 패러다임으로 떠올랐다. 하지만 Swin transformer와 같은 계층적 구조를 가진 현대 비전 모델들은 MIM을 하기가 쉽지 않다. (요즘 100번 넘게 본 레퍼토리, 그 다음은 대충 계층적 transformer에 MIM을 적용해서 메모리와 시간 효율성을 끌어올리겠다는 내용. 적은 에너지 소모로 친환경적이라는 걸 엄청 강조함.)
먼저 가시(unmasking) 패치의 수가 고르지 않은 local window를 여러 개의 동일한 크기의 그룹으로 분할한 다음 각 그룹 내에서 masked attention을 적용한다. 다음으로, 그룹화된 토큰에 대한 attention 계산 비용을 최소화하는 그룹 파티션을 찾는다. 이를 위해 동적 프로그래밍의 개념과 greedy 알고리즘에서 영감을 받아 최적의 그룹 크기를 적응적으로 선택하고 local window를 최소 그룹 수로 분할하는 최적 그룹화 알고리즘을 제안한다. 본 논문의 방법론은 일반적이며 백본 모델의 아키텍처를 수정하지 않는다. 실험 평가에서, 본 논문의 방법이 훈련 시간을 상당히 적게 요구하고 GPU 메모리를 훨씬 적게 소비한다는 것을 관찰한다.
본 논문의 기여는 다음과 같다.
- MIM을 위한 효율성이 획기적으로 향상된 녹색 계층적 ViT를 설계
- Group window attention 체계 제안
- 동적 프로그래밍과 greedy 알고리즘에서 영감을 받아 최적 그룹화 알고리즘을 제안
- 광범위한 실험 및 평가
Related Work
Masked Auto-Encoders : MAE에서는 마스크된 패치를 없애고 가시 패치에 대해서만 연산하므로 메모리 효율성이 매우 높다.
[논문공부] (자세한 리뷰) Masked Autoencoders are Scalable Vision Learners
들어가며: Masked Autoencoders Are Scalable Vision Learners(링크)는 Facebook AI Research(아직은 Facebook으로 되어있는데 meta로 바뀌겠죠?)에서 나온 논문으로, 현재 CVPR 2022에 submit되어 review중인 듯..
developers-shack.tistory.com
UM-MAE : 며칠 전 리뷰했던 논문인데 이 논문이랑 똑같은 주제를 다루었다. (이 논문에서 언급된 건 아님)
계층적 Transformers : Swin Transformer, PVT
Approach
Preliminary
입력 feature X ∈ RC×H×W, 마스크 M
mask(X, M) -> X̂
Green Hierarchical Vision Transformer for Masked Image Modeling
백본으로 swin transformer를 선택한다. Local window 내에서만 attention을 하기 때문에 무작위 마스킹으로 인해 window 간 패치 수가 고르지 않을 때는 attention을 수행할 수가 없다. 이를 위해 group window attention 체계를 제안한다.
먼저 window {wi} 내의 가시 토큰만을 포함하는 local window featrue {Xi}를 수집한다.
그리고 다음 그림과 같이 불균일한 window를 여러 개의 동일한 크기의 그룹으로 분할한 다음 각 그룹 내에서 masked attention을 수행한다.

Optimal Grouping with Dynamic Programming
각각의 window를 그룹화하는 문제는 일종의 0-1 다중 배낭 문제로 취급할 수 있다.
Window를 상자, window 내의 패치 갯수를 해당 상자의 무게와 가치, window 그룹을 배낭으로 생각하면 된다.
원래 다중 배낭 문제는 풀 수 없는 NP-complete 이지만 이 문제에서는 무게와 가치가 동일하기 때문에 동적 프로그래밍(DP) 알고리즘으로 풀 수 있다.
다음 공식은 그룹화된 토큰에 대한 multi-head attention 계산 복잡성이다. (C = 채널 수)

계산 복잡성은 그룹 크기 gs에 대해 2차이다. 하지만 계산 복잡성을 위해 gs를 낮추면 더 많은 그룹을 생성해 최적 알고리즘에 악영향을 끼칠 수 있다.
최적의 그룹 크기를 찾기 위해 단일 window의 최대 패치 수 ~ 모든 패치 수 사이의 값을 스윕하며 각 그룹 크기에 대해 DP 알고리즘을 사용해 계산 비용이 최소인 그룹 크기를 선택한다.
(실험 섹션에서 설명하겠지만, 사실 모든 그룹 크기를 계산할 필요는 없다.)
(알고리즘의 세부사항이 궁금하다면, 논문의 부록에 알고리즘의 코드 구현이 있다.)
Masked Attention
비인접 local window는 동일한 그룹으로 분할되기 때문에 다음 그림과 같이 이러한 local window 간의 정보 교환을 방지하기 위해 attention 가중치를 마스킹해야 한다. (이 논문의 목적은 local window에서 MIM 하는 것이라는 걸 기억해라.)

그룹화 전 각 토큰의 원래 위치가 저장되며 위치 편향 연산에도 위의 체계가 적용된다.
Batch-wise Random Masking
샘플당 무작위 마스킹 전략은 본 논문에서 제안한 방법의 효율성을 저하시킨다.
- 각 샘플에 대해 서로 다른 local window 그룹이 생긴다.
- 마스크 패치 크기가 계층 모델의 최대 패치 크기보다 작을 경우 일부 패치에서 마스킹되거나 되지 않은 feature가 모두 포함될 수 있다.
따라서 마스크 패치 크기를 최대 패치 크기와 같게 설정하고 같은 batch에 같은 랜덤 마스크를 적용한다.
Experiments
Classification : ImageNet-1K
Object detection/Instance segmentation : MS-COCO
BackBone : Swin-Base, Swin-Large
메모리, 시간 효율성

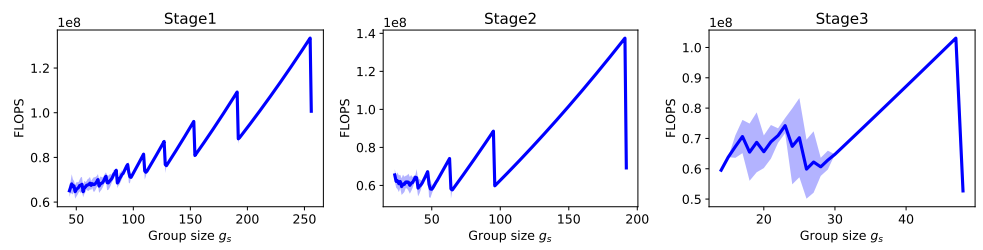
그룹 크기에 대한 실험 결과.
연구진은 그룹 크기가 window 크기와 동일한 지점 근처에서 최소라는 것을 발견했다.
따라서 그룹 크기는 window 크기 p x p로 설정하면 된다.
Ablation Study
의외로 디코더가 단순할 때 성능이 더 좋다.

Window 크기 비교.
큰 window는 계산 비용에 비해 실용적이지 않다.

Classification
본 논문의 모델을 포함한 MAE를 이용한 모델들은 시간, 메모리 효율성을 높이는 것이 목표이기 때문에 성능이 엄청 개선되지는 않는다.

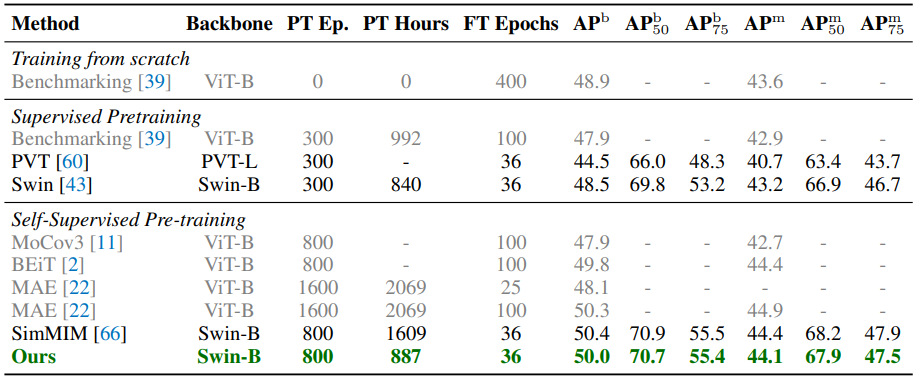
Object detection and instance segmentation
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| DAB-DETR : Dynamic Anchor Boxes are Better Queries for DETR 논문 리뷰 (0) | 2022.06.13 |
|---|---|
| Separable Self-attention for Mobile Vision Transformers 논문 리뷰 (0) | 2022.06.10 |
| EfficientFormer: Vision Transformers at MobileNet Speed 논문 리뷰 (0) | 2022.06.10 |
| Inception Transformer 논문 리뷰 (0) | 2022.05.27 |
| Vision Transformer Adapter for Dense Predictions 논문 리뷰 (1) | 2022.05.27 |
| ASSET : Autoregressive Semantic Scene Editing with Transformers at High Resolutions 논문 리뷰 (0) | 2022.05.26 |



