5월 25일 공개된, 고주파수를 잘 포착하는 ViT와 저주파수를 잘 포착하는 CNN을 잘 혼합한 논문이다. 요즘 비슷한 주제의 논문을 너무 많이 봐서 솔직히 엄청 대충 읽고 있었는데 읽다 보니 나름 간단하고 괜찮은 아이디어라는 생각이 들었다.
GitHub - sail-sg/iFormer: iFormer: Inception Transformer
iFormer: Inception Transformer. Contribute to sail-sg/iFormer development by creating an account on GitHub.
github.com
Abstract
(요약: 넓은 범위의 주파수 캡처를 위해 inception mixer 설계, 고주파수와 저주파수 간의 상충을 위해 램프 구조 도입.)
(고주파수 = 세부적인 표현, 저주파수 = coarse한 표현)
최근 연구에 따르면 Transformer는 장거리 종속성을 구축할 수 있는 강력한 능력을 가지고 있지만 주로 local 정보를 전달하는 고주파를 캡처하는 데는 무능하다. 이 문제를 해결하기 위해, 시각적 데이터의 고주파 및 저주파 정보로 포괄적인 feature를 효과적으로 학습하는 새롭고 범용적인 Inception Transformer(iFormer)를 제안한다. 특히, 고주파 정보를 캡처하기 위한 컨볼루션과 최대 풀링의 장점을 transformer에 명시적으로 접목하기 위해 inception mixer를 설계한다. 최근의 하이브리드 프레임워크와 달리, Inception mixer는 채널 분할 메커니즘을 통해 높은 주파수 및 낮은 주파수 mixer로 병렬 convolution/max pooling path 및 self attention path를 채택하는 동시에 넓은 주파수 범위 내에 분산된 식별 정보를 모델링할 수 있는 유연성을 갖는다. 하위 계층이 고주파 세부 정보를 캡처하는 데 더 많은 역할을 하는 반면, 상위 계층은 저주파 글로벌 정보를 모델링하는 데 더 많은 역할을 한다는 것을 고려하여, 주파수 램프 구조를 추가로 도입한다. 즉, 고주파 mixer에 공급되는 치수를 점차 감소시키고 저주파 mixer에 공급되는 치수를 증가시켜 서로 다른 층에 걸쳐 고주파 및 저주파 성분을 효과적으로 상충할 수 있다.
Introduction
ViT는 global한 낮은 주파수를 포착하는 능력이 높지만, 높은 주파수의 local 정보를 학습하는 데는 강력하지 않다. (요즘 진짜 100번 넘게 본 레퍼토리다.)
아래의 그림과 같이, ViT는 고주파 신호를 잘 포착하지 못한다. 이는 ViT가 low pass filter(LPF)의 역할을 한다는 것을 보여준다.

반면에 CNN은 local 컨볼루션을 통해 고주파수를 효과적으로 추출한다. CNN과 ViT의 상호보완적 이점을 통합 다양한 연구가 진행되었지만 현재의 병렬 구조들은 각 분기의 모든 채널을 처리할 경우 정보 중복성을 갖는다.
본 논문에서는 CNN과 ViT를 통합하는 간단하고 효율적인 Inception Transformer(iFormer)를 제안한다. iFormer의 핵심 구성 요소인 inception mixer는 max pooling과 컨볼루션으로 구성된 고주파 mixer와 self attention을 하는 저주파 mixer로 구성되어 있다. 이러한 방식으로 iFormer는 넓은 주파수 범위 내에서 보다 포괄적인 feature를 학습할 수 있다.
또한 연구진은, 낮은 계층은 종종 더 많은 local 정보를 필요로 하는 반면, 높은 계층은 더 많은 global 정보를 원한다는 것을 발견한다. 이에 영감을 받아 주파수 램프 구조를 설계한다. 특히, 더 낮은 층에서 더 높은 층으로, 점점 더 많은 채널 치수를 저주파 mixer에 공급하고 더 적은 채널 치수를 고주파 mixer에 공급한다. 이 구조는 모든 레이어에 걸쳐 고주파 및 저주파 요소를 상충할 수 있다.
실험 결과는 iFormer가 이미지 분류, 객체 탐지 및 분할을 포함한 여러 비전 작업에서 SOTA ViTs 및 CNN을 능가한다는 것을 보여준다.
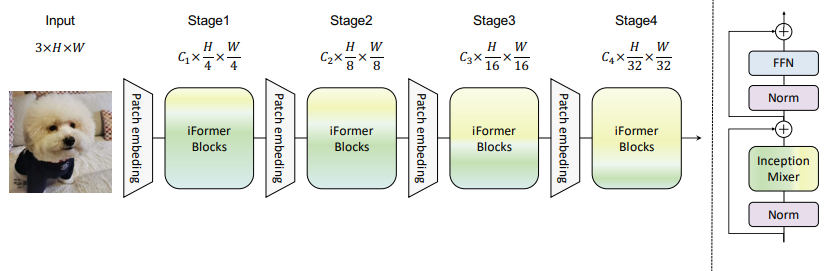
Method
Revisit Vision Transformer
ViT는 먼저 입력 이미지를 패치 수 N x 채널 수 C개의 패치 토큰 xi로 나누고 선형 투영, 위치 임베딩 후 transformer 계층에 공급된다. Transformer 계층의 multi-head attention은 global 정보가 과도하게 전파되어 저주파 표현이 강화되며 이는 고주파 정보를 약화시키고 모델의 성능을 저하시킬 수 있다. 이 문제를 해결하기 위해 iFormer를 제안하며, 아키텍처는 다음과 같다.

Inception token mixer
여러 개의 분기가 있는 Inception 모듈에서 영감을 받았기 때문에 'Inception'이라는 이름을 붙였다.
Inception mixer는 먼저 채널 차원을 따라 입력 feature를 분할한 다음 각각을 고주파 mixer와 저주파 mixer에 공급한다. 고주파 mixer는 maxpooling/convolution의 병렬 구조로 구성되고 저주파 mixer는 self attention을 담당한다.

채널 차원을 고주파수 feature Xh1, Xh2, 저주파수 feature Xl로 나눈다.
(같은 feature를 3번 계산하는 것이 아니라 정보 중복성을 피하기 위해 채널을 나누어서 따로 계산하는 것이 중요한 듯하다.)
저주파 mixer에서 self attention의 높은 계산 비용을 피하기 위해 풀링 후 저해상도에서 계산한 뒤 업샘플링한다.

저주파 믹서에도 각각 연산한 뒤 전부 합친다. (Dw = depth-wise)

저주파 mixer의 인접 픽셀을 선택하는 업샘플링 연산으로 인해 과도한 평활성이 발생한다. 채널 간의 선형 계층을 유지하면서 이 문제를 해결하기 위한 융합 모듈을 설계한다. 최종 산출은 다음과 같다.
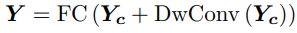
Frequency ramp structure
하위 계층은 더 많은 고주파수를 캡처하고, 상위 계층은 더 많은 저주파수를 캡처하기 때문에 초반 레이어일수록 Ch를 크게, 후반 레이어일수록 Cl을 크게 조정한다.
Experiments
ImageNet-1K classification

Fine-tuning Results with larger resolution on ImageNet-1K

Object detection and instance segmentation on COCO

Semantic segmentation with semantic FPN on ADE20K

Ablation Study

Fourier spectrum
상위 레이어로 갈수록 더 많은 고주파수를 포착한다.

Grad-CAM




