5월 23일 공개된 본 논문은 local window를 사용하는 계층적 ViT에서도 MAE 사전 훈련 방법을 적용할 수 있게 한 논문이다.
GitHub - implus/UM-MAE: Official Codes for "Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers wit
Official Codes for "Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality" - GitHub - implus/UM-MAE: Official Codes for "Uniform Masking: Ena...
github.com

Abstract
마스크된 오토인코더(MAE)는 ViT의 'global' 속성에 의존하며 비대칭 인코더-디코더 설계로 자체 감독 영역의 추세를 주도하고 있다. 그러나 local window 기반 ViT(PVT, Swin)가 MAE 사전 훈련에서 어떻게 채택될 수 있는지는 여전히 불분명하여 부분 비전 토큰의 무작위 시퀀스를 취급하기가 어렵다. 본 논문에서는 locality를 가진 피라미드 기반 ViT에 대한 사전 훈련을 가능하게 하는 균일 마스킹(UM) 전략을 제안한다.
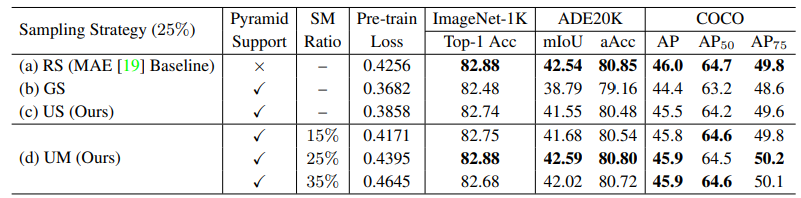
구체적으로, UM은 균일 샘플링(US)과 2차 마스킹(SM)을 포함한다. US는 여러 local window에서 동등한 요소를 보존하고 SM은 전송가능한 시각적 표현을 개선하도록 설계되었다. 연구진은 UM-MAE가 피라미드 기반 ViT의 사전 훈련 효율성을 크게 향상시키면서 다운스트림 작업 경쟁력은 유지한다는 것을 보여준다.
Introduction
자체 지도 학습(SSL)에서 MAE는 가장 대표적인 방법 중 하나가 되었으며, 전체 중 25%의 패치만 입력으로 받음에도 불구하고 우수한 성능을 얻었다.

MAE는 위 그림의 (a)처럼 ViT의 global 특성에 의존하는데, 이러한 방법은 global self attention의 영향으로 많은 메모리가 요구된다는 단점이 있다.
피라미드, local window 기반 ViT는 메모리 효율에서 이점이 있지만 local에서만 attention을 수행하기 때문에 MAE를 이용하여 효과적으로 사전훈련 할 수 있는지가 불분명하다.
본 논문에서는 피라미드 기반 ViT에 대한 MAE 사전훈련을 성공적으로 활성화하기 위해 균일 샘플링(US)과 2차 마스킹(SM)을 포함하는 균일 마스킹(UM) 전략을 제안한다. (d)와 같이, 우선 2x2 그리드에서 랜덤 패치 1개를 엄격하게 샘플링한다. US는 샘플링된 패치가 무작위 샘플링보다 더 균일하게 분포되어 픽셀 복구 작업의 어려움을 줄이고 표현 학습을 방해하기 때문에 의미론적 단서를 유출할 위험이 크다. 따라서 SM을 통해 추가 마스킹을 도입한다.
본 논문의 기여는 다음과 같다.
- 인기 있는 피라미드 기반 ViT에 대한 MAE 사전 훈련을 가능하게 하는 방법을 제안한다.
- UM-MAE가 경쟁적인 미세 조정 성능을 유지하면서 기존 SOTA 마스크 이미지 모델링(MIM) 프레임워크에 비해 사전훈련 효율성을 높이고 메모리 소비를 2배 이상 줄인다는 것을 보여준다.
- MIM에서 Vanilla ViT와 피라미드 기반 ViT 사이의 몇 가지 주목할 만한 다른 행동을 밝히고 논의한다.
Related Work
[논문공부] (자세한 리뷰) Masked Autoencoders are Scalable Vision Learners
들어가며: Masked Autoencoders Are Scalable Vision Learners(링크)는 Facebook AI Research(아직은 Facebook으로 되어있는데 meta로 바뀌겠죠?)에서 나온 논문으로, 현재 CVPR 2022에 submit되어 review중인 듯..
developers-shack.tistory.com
Method
Uniform Sampling
모든 2x2 그리드에서 패치를 샘플링한다. 모든 local window에서 균일한 양의 패치가 샘플링되기 때문에 피라미드 기반 ViT에도 적용될 수 있다. 또한 재구성된 이미지는 크기가 1/4로 줄어 계산상의 이점도 있다.
PVT와 Swin Transformer에서 다음 그림과 같이 적용된다.
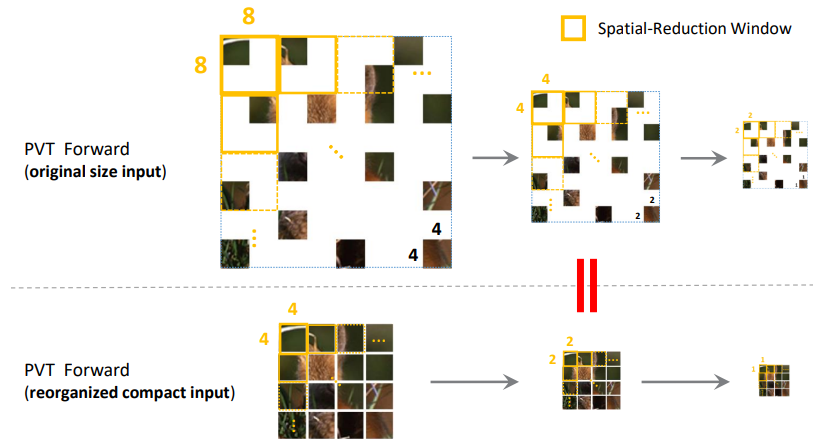

Secondary Masking
US는 인접한 이미지 통계를 이용해 픽셀 재구성을 위한 바로가기를 제공함으로써 잠재적으로 자체 감독을 덜 어렵게 만들 수 있다. 실제로도 US는 훈련 난이도를 낮춰 다른 작업에서의 성능을 떨어트렸다.
따라서 2차 마스킹(SM)을 추가로 제안한다. US와 달리 SM 단계에서는 피라미드, Swin과의 local 호환성을 위해 패치를 완전히 폐기하지 않고 마스크된 상태를 유지한다.

UM-MAE Pipeline with Pyramid-based ViT

UM 후 16x16 패치 크기의 MAE를 따른다. PVT와 Swin은 다양한 크기의 window에서 여러 번 attention을 수행하는 계층적 ViT이며 4개의 계층이 있다.
인코더의 출력을 디코더에 입력하기 전에 pixel shuffle을 이용해 MAE의 디코더 입력과 크기를 맞춰준다.
손실은 SM에서 마스킹된 패치를 제외하고 US에서 제거된 패치에 대해서만 MSE를 계산한다.
Experiment
MAE에서와 같이 다운스트림 작업에 대한 미세 조정 정확도에 중점을 둔다.
Vanilla ViT에서 US는 별로 좋지 않다. SM까지 더해도 성능이 개선되지는 않았다.

2차 마스킹 비율에 대한 비교.

SimMIM과 효율성 비교. 훨씬 적은 시간과 메모리로 거의 비슷한 성능을 달성한다.

이미지 복원 비교. UM-MAE는 2차 마스킹으로 인해 원본이미지의 18%의 정보만 가지고 있다는 것을 고려해야 한다.
SimMIM은 지나치게 매끄럽고, UM-MAE는 조금 더 세부적이지만 패치 경계가 너무 티가 난다.



Discussion
연구진들은 경험적으로 Vanilla ViT와 피라미드 기반 ViT 사이의 몇 가지 차이를 발견했다.
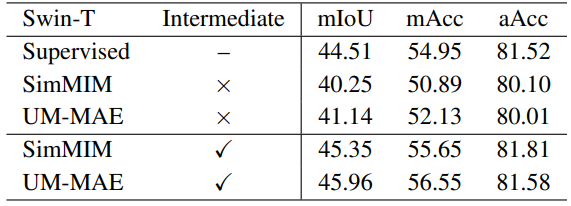
위의 표와 같이, MIM(Masked Image Modeling) 프레임워크의 자체 감독 피라미드 기반 ViT는 다운스트림 작업을 직접 미세조정 하는 데는 경쟁력이 없다. 오히려 성능이 떨어지기까지 한다. 대신 MIM 사전훈련 후 중간 데이터 세트(주로 ImageNet-1K)에서 추가로 훈련한 다음 대상 다운스트림 작업에서 미세조정 하는 중간 미세조정 프로세스를 사용하면 성능을 크게 향상시킬 수 있다. (NLP에서는 이미 유명한 방법이라고 한다.)
Vanilla ViT에서는 중간 미세조정이 효과적이지 않다고 한다.
Vanilla ViT에서 최적의 성능을 얻기 위해 계층별 학습 속도 감소가 중요하지만, 피라미드 기반 ViT에서는 그렇지 않다.
MIM에서, 특히 초기 계층에서 유도 편향을 가져올 수 있으므로 초기 단계에서 상대적으로 작은 학습률이 Vanilla ViT에서의 일반화 능력을 최대한 보존한다. 하지만 local window를 사용하는 피라미드 기반 ViT에서는 이미 유도 편향을 사용하기 때문에 필요가 없다.
Conclusion
본 논문에서는 균일 샘플링 및 2차 마스킹을 포함하는 새로운 균일 마스킹 전략을 가진 UM-MAE를 제안하여 피라미드 기반 ViT에 대한 MAE 사전 훈련을 가능하게 한다. UM-MAE는 메모리와 런타임 모두에서 효율성을 크게 향상시키면서 경쟁적인 미세조정 성능을 유지한다. 또한 MIM 프레임워크에서 Vanilla ViT와 피라미드 기반 ViT 사이의 다양한 행동에 대한 몇 가지 경험적 발견에 대해 논의한다.
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| Inception Transformer 논문 리뷰 (0) | 2022.05.27 |
|---|---|
| Vision Transformer Adapter for Dense Predictions 논문 리뷰 (1) | 2022.05.27 |
| ASSET : Autoregressive Semantic Scene Editing with Transformers at High Resolutions 논문 리뷰 (0) | 2022.05.26 |
| ConvMAE : Masked Convolution Meets Masked Autoencoders 논문 리뷰 (0) | 2022.05.12 |
| Activating More Pixels in Image Super-Resolution Transformer (HAT) 논문 리뷰 (0) | 2022.05.12 |
| Understanding The Robustness in Vision Transformers (FAN) 논문 리뷰 (0) | 2022.05.08 |



