5월 9일 공개된 Activating More Pixels in Image Super-Resolution Transformer
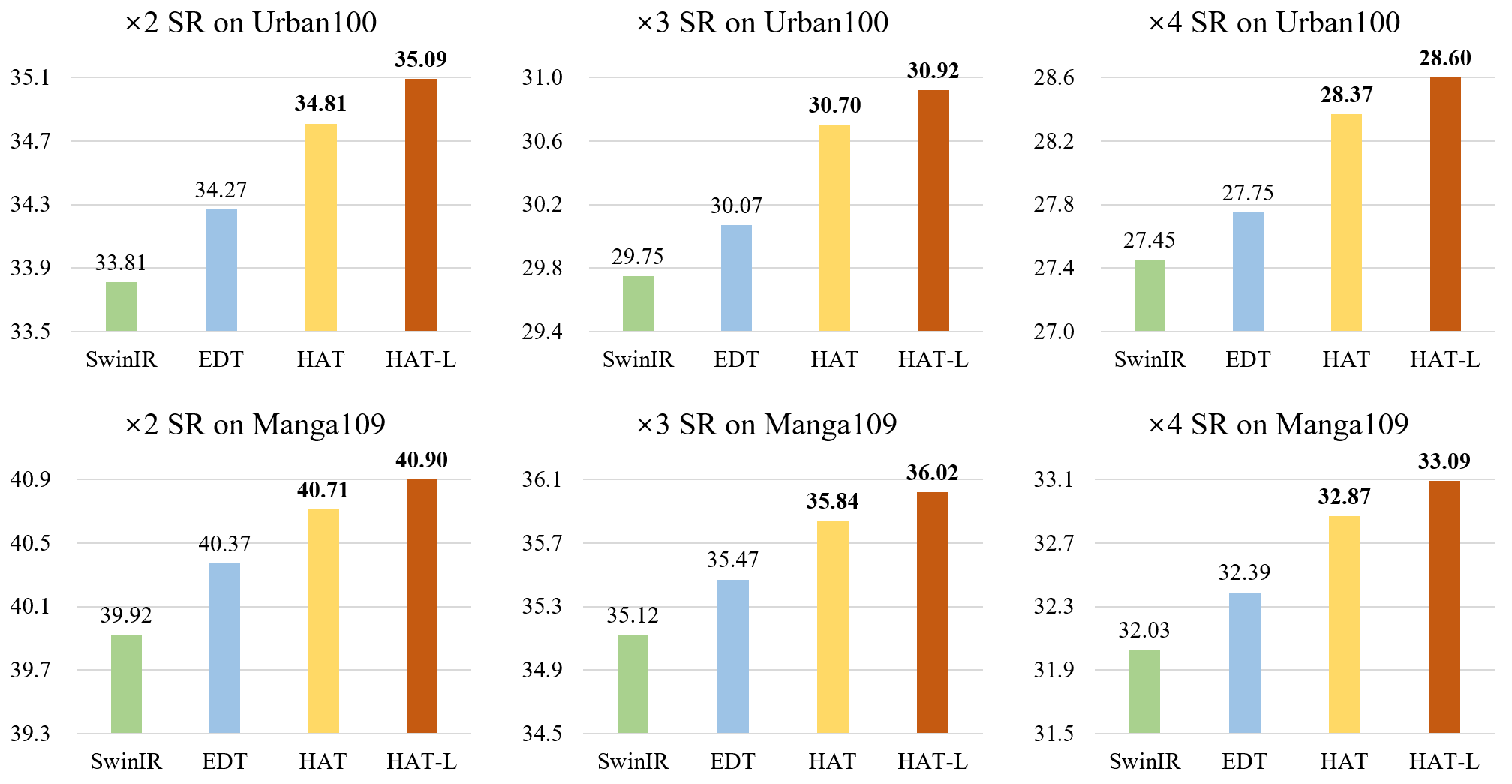
Abstract
트랜스포머 기반 방법은 이미지 초해상도와 같은 저수준의 비전 작업에서 인상적인 성능을 보여주었다. 그러나 이러한 네트워크는 속성 분석을 통해 제한된 공간 범위의 입력 정보만 활용할 수 있다는 것을 발견했다. 이는 트랜스포머의 잠재력이 기존 네트워크에서 여전히 충분히 활용되지 못하고 있음을 시사한다. 재구성을 위해 더 많은 입력 픽셀을 활성화하기 위해 새로운 Hybrid Attention Transformer(HAT)를 제안한다. 그것은 channel attention과 self attention을 결합하여 그들의 보완적 장점을 활용한다. 또한, cross window 정보를 더 잘 집계하고 이웃 window feature 간의 상호작용을 향상시키기 위해 overlapping cross-attention 모듈을 도입한다. 교육 단계에서는 추가 개선을 위해 same-task 사전 교육 전략을 추가로 제안한다. 광범위한 실험은 제안된 모듈의 효과를 보여주며, SOTA 방법을 1dB 이상 크게 능가한다.
Introduction
SwinIR은 트랜스포머 기반의 단일 이미지 초해상도(SR)에서 획기적인 개선을 얻었다. 그럼에도 불구하고 "트랜스포머가 CNN보다 나은 이유"는 여전히 미스터리로 남아 있다. 직관적인 설명은 이러한 종류의 네트워크가 self attention으로부터 이익을 얻을 수 있고 장거리 정보를 활용할 수 있다는 것이다. 연구진은 SwinIR에서 재구성을 위해 활용된 정보의 관련 범위를 조사하기 위해 속성 분석 방법인 LAM을 사용했다.
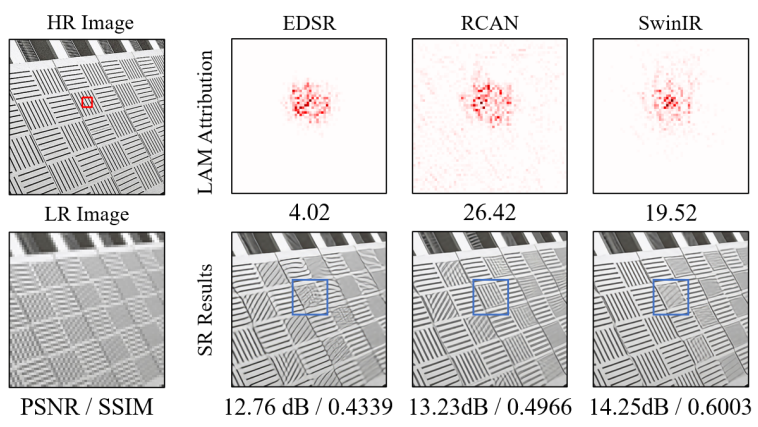
흥미롭게도, SwinIR은 초해상도에서 CNN 기반 방법(RCAN)보다 더 적은 입력 픽셀을 활용한다. SwinIR은 더 높은 정량적 성능을 얻지만, 활용되는 정보의 범위가 제한적이기 때문에 경우에 따라 RCAN보다 낮은 결과를 생성한다. 이러한 현상은 트랜스포머가 로컬 정보를 모델링하는 능력이 더 강하지만, 활용되는 정보의 범위가 확장되어야 한다는 것을 보여준다.
문제를 해결하고 SR 트랜스포머의 잠재력을 더욱 발전시키기 위해 Hybrid Attention Transformer(HAT)를 제안한다.
본 논문의 기여는 다음과 같다.
- 더 많은 정보를 활용하기 위해 Channel attention(CA) 도입 (요즘 channel attention 관련 논문이 많이 나오네요.)
- Cross window 정보를 더 잘 집계하기 위해 overlapping cross-attention 모듈 도입
- 사전 교육이 SR 작업에 미치는 영향을 탐색하고 same-task 사전 교육 전략을 제공
Related Work
SwinIR : Swin Transformer를 기반으로 한 SR 모델

LAM : 초해상도에서 어떤 입력 픽셀이 기여하는지 탐색
RCAN : 여기서 channel attention 가져옴

Method
Network Architecture
전체적인 구조는 다음과 같이 얕은 feature 추출, 깊은 featrure 추출, 이미지 재구성의 세 단계로 구성되어 있다.
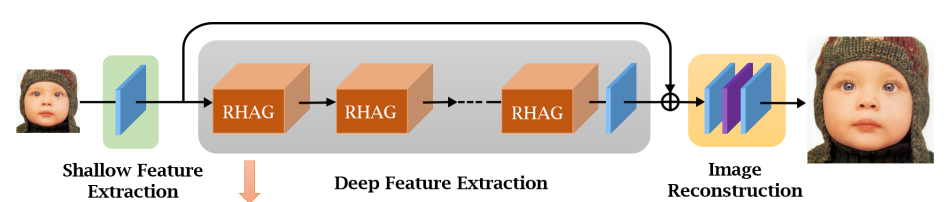
먼저 낮은 해상도의 입력 이미지 ILR에 대해 하나의 컨볼루션 레이어 HSF로 얕은 feature F0을 추출한다.
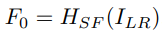
초기 컨볼루션 레이어는 더 나은 시각적 표현을 학습하는 데 도움이 될 수 있으며 안정적인 최적화로 이어질 수 있다.
그런 다음 깊은 feature를 추출한다.

HDF는 N개의 residual hybrid attention groups(RHAG) 와 3x3 컨볼루션 Hconv를 포함한다.

두 feature를 융합하기 위해 잔차 연결을 추가한다.
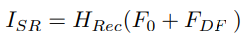
HRec는 재구성 모듈이다. Feature를 업샘플링 하기 위해 pixel-shuffle 방법을 채택했다.
매개변수를 최적화 하기 위해 L1 loss를 사용한다.
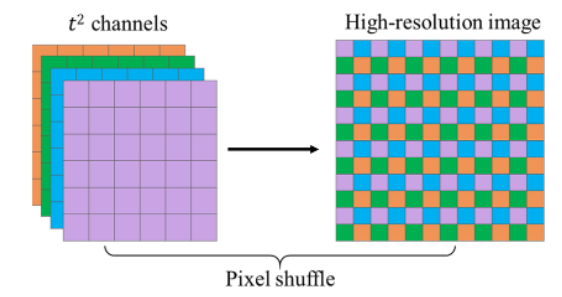
Residual Hybrid Attention Group (RHAG)

RHAG는 여러 개의 hybrid attention blocks (HAB), overlapping cross-attention block (OCAB), 3x3 컨볼루션 그리고 잔차 연결을 포함한다.
Hybrid Attention Block (HAB)

더 많은 픽셀들을 활성화하기 위해 channel attention을 채택한다. 게다가, 많은 연구들에서 컨볼루션이 트랜스포머가 더 나은 시각적 표현을 얻거나 더 쉬운 최적화를 달성하는 데 도움이 될 수 있다는 것을 보여주기 때문에, 네트워크의 표현 능력을 더욱 향상시키기 위해 channel attention 기반 컨볼루션 블록을 표준 트랜스포머 블록에 통합한다.
위 그림과 같이 channel attention block(CAB)과 window based multi-head self attention(W-MSA) 모듈은 병렬로 배치되고 shifted-window based self attention(SW-MSA) 모듈은 연속적인 HAB에서 간격을 두고 채택된다.
각 픽셀을 임베딩을 위한 토큰으로 취급한다.
Self attention 계산을 위해, M x M 크기의 local window로 분할한 후 각 window 안에서 self attention을 계산한다.Local window feature XW ∈ RM2 x C 를 선형 투영하여 Q, K, V를 구하고 window-based self-attention을 수행한다.
(B는 위치 편향, W-MSA, SW-MSA에 더 자세히 알고 싶다면 Swin Transformer 리뷰 참조)

또한 window 간의 연결을 구축하기 위해 시프트 크기를 window 크기의 절반으로 설정한다.
Channel Attention Block (CAB)
CAB는 다음 그림과 같이 구성되어 있다.

트랜스포머 기반 구조는 토큰 임베딩을 위해 많은 채널을 필요로 하기 때문에 컨볼루션을 직접 사용하면 큰 계산 비용이 발생한다. 그래서 첫 컨볼루션에서 채널 수를 C/β 로 압착하고 두번째 컨볼루션에서 다시 채널 수를 복원한다. 그 다음 CA 모듈에 공급한다.
CA 모듈의 경우 RCAN에서 그대로 가져왔는데, 각 채널에 대한 가중치를 구한 다음에 원래의 feature에 곱해준다.

식으로 정리하면 다음과 같다.

Overlapping Cross-Attention Block (OCAB)
Cross-window 연결을 직접 설정하고 window self attention의 표현 능력을 향상시키기 위한 OCAB를 소개한다.

OCAB는 overlapping cross-attention (OCA) 계층과 MLP 계층으로 구성된다.
OCA는 투영된 feature를 분할하기 위해 다음과 같이 서로 다른 window 크기를 사용한다.
(Q와 K, V의 출처가 다르면 cross attention이라고 한다.)
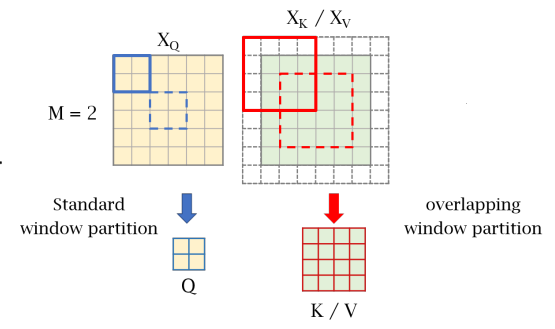
K, V의 window 크기 Mo는 상수 γ에 따라 결정되며, 크기 일관성을 위해 zero 패딩을 사용한다.

Attention은 W-MSA와 동일하게 계산된다.
전체 아키텍쳐 :

Pre-training on ImageNet
IPT, EDT 등의 연구들은 사전 훈련이 저수준 작업에서 중요한 역할을 한다는 것을 보여준다. 기존의 연구들과 대조적으로, 본 연구에서는 동일한 작업을 더 큰 규모의 데이터 세트에 대해 사전 교육을 직접 수행한다. 예를 들어, ×4 SR에 대한 모델을 교육하려면 먼저 ImageNet에서 ×4 SR 모델을 교육한 다음 DF2K와 같은 특정 데이터 세트에서 미세 조정한다. (IPT, EDT는 다양한 작업에 사용하기 위해 사전 훈련을 했으나, 이 연구에서는 오직 SR 작업을 위해서만 사전 훈련 하기 때문에 same-task 방법이라고 하는 것 같은데 굳이 있어보이게 이름을 붙였어야 했나....음...)
Conclusion
본 논문에서는 이미지 초해상도를 위한 새로운 Hybrid Attention Transformer(HAT)를 제안한다. HAT는 self attention과 channel attention을 결합하여 더 많은 픽셀을 활성화한다. 또한 cross window 정보를 더 잘 집계하기 위해 서로 다른 window 크기를 가진 feature 간의 attention를 계산하는 overlapping cross-attention 모듈을 제안한다. 광범위한 실험은 제안된 모듈의 효과를 보여주며, HAT는 SOTA 방법을 크게 능가한다.
Experiments
(다른 SOTA 방법들과의 비교는 맨 아래에)
Experimental Setup
DF2K(DIV2K + Flicker2K) 데이터셋 사용. 사전 교육으로는 ImageNet 채택.
RHAG와 HAB 수는 6으로 설정.
성능평가 메트릭은 PSNR 및 SSIM 사용.
Effects of different window sizes
앞서 논의한 바와 같이, SR을 위해 더 많은 입력 픽셀을 활성화하면 더 나은 성능을 달성하는 경향이 있다. Self attention 계산을 위해 window 크기를 확대하는 것은 직관적인 방법이다. Self attention의 window 크기가 표현 능력에 어떤 영향을 미치는지 추가로 탐구한다. 새로 도입된 블록의 영향을 제거하기 위해 SwinIR에서 실험을 수행한다.

특히 window 크기가 클 때 더 많은 픽셀이 활성화됨을 볼 수 있다.

따라서 window 크기 16을 기본 설정으로 사용한다.
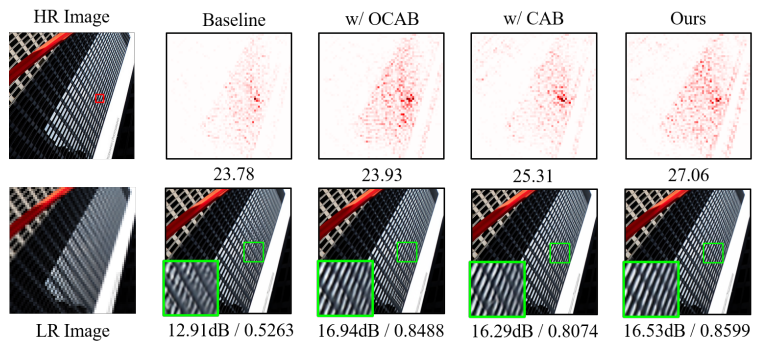
Ablation Study
CAB 및 OCAB의 효과를 입증하기 위한 실험을 수행한다.

또한 질적 비교도 수행
OCAB의 중첩 크기를 제어하기 위한 상수 γ 설정 비교
따라서 0.5를 기본 설정으로 사용

CAB의 다양한 설계의 효과를 탐구하기 위한 실험을 수행한다.
먼저, 컨볼루션 설계의 영향과 CA를 조사한다.
(DWCAB = depth-wise convolution is adopted in CAB)
깊이별 컨볼루션은 성능저하를 유발함.

CAB 가중치 α에 대한 비교.
α는 그냥 단순 가중치라 위에서 언급하지 않았는데 α가 클수록 CAB의 영향이 커지고 작을수록 W-MSA의 영향이 커짐.
0.01에서 가장 성능이 좋다. 별로 도움은 안되지만 없는 것 보다는 낫다 이런건가..?

Comparison with State-of-the-Art Methods
(† 표시는 ImageNet에서 사전 훈련, -L은 대형 모델, 빨강, 파랑, 초록 순으로 1,2,3 등)








