며칠 전 공개된 Temporally Efficient Vision Transformer(TeViT)


Abstract
비디오 클립 내의 중요한 시간 정보를 효과적이고 효율적으로 모델링하기 위해 video instance segmentation(VIS)을 위한 Temporally Efficient Vision Transformer(TeViT)를 제안한다. 이전의 transformer-based VIS 방법과 달리, transformer backbone과 query-based video instance segmentation head를 포함하여 거의 convolution-free에 가깝다.
백본 단계에서 초기 시간 맥락 융합을 위한 거의 피라미터가 없는 messenger shift 매커니즘을 제안한다. 헤드 단계에서는 비디오 인스턴스와 쿼리 간의 일대일 대응성을 구축하기 위한 parameter-shared spatiotemporal query interaction 메커니즘을 제안한다.
따라서 TeViT는 프레임 수준과 인스턴스 수준 시간 맥락 정보를 모두 활용하고 무시할 수 있는 추가 계산 비용으로 강력한 시간 모델링 capacity을 얻는다. YouTube-VIS-2019, YouTube-VIS-2021 및 OVIS와 같이 널리 채택된 세 가지 VIS 벤치마크에서 TeViT는 최첨단 결과를 얻고 YouTube-VIS-2019에서 68.9 FPS로 46.6 AP와 같은 높은 추론 속도를 유지한다.
Introduction
VIS(Video Instance Segmentation)는 프레임 간에 비디오 인스턴스를 동시에 감지, 분할 및 추적해야 하는 대표적인 도전적인 비디오 이해 작업이다. 다른 인스턴스 수준 비디오 인식 작업과 마찬가지로, 고성능 VIS 시스템을 구축하려면 시간 맥락 정보를 최대한 활용하는 것이 중요하다. 기존의 transformer와 달리 VIS를 위한 transformer는 시간적 맥락 모델링을 추가로 수행해야 한다. 그래서 VisTR, IFC 등이 제안되었다.
모든 비디오 패치에서 self attention을 계산하는 것은 시간과 공간 복잡성이 높기 때문에 매우 중요한 문제이다. 시간적 모델링을 위한 multi-head self attention(이하 MHSA) 레이어는 추가 매개 변수를 가지고 있으며, 단일 프레임 기능 추출만 지원하고 백본 단계에서 시간 정보를 캡처하지 못한다. 위의 문제를 해결하기 위해 효율적이고 효과적인 TeViT(Temporally Efficient ViT)를 제시한다.
TeViT는 transformer 백본과 일련의 쿼리 기반 VIS 헤드를 포함한다. 백본 단계에서, 메신저 토큰을 사용하여 self attention을 통해 프레임 내 정보를 추출하고 프레임 수준 맥락 모델링을 위한 메신저 시프트 메커니즘을 제안하는데, 메신저 토큰을 여러 그룹으로 나누어 다양한 시간 단계로 시간적 시프트를 수행한다.
이전의 VIS 방법과 달리 메신저 시프트 transformer는 초기 시간적 feature 융합을 가능하게 한다. 헤드 단계에서는 인스턴스 수준 시간 정보 상호 작용을 위해 MHSA 매개 변수를 재사용하여 QueryInst 인스턴스 분할 헤드를 VIS 헤드로 변환한다.
실험은 세가지 VIS 데이터세트(YouTube-VIS-2019, 2021, OVIS)에 대해 수행되며 SoTA 성능을 얻었다. 논문의 주요 공헌을 요약하자면
1. TeViT는 프레임 수준과 인스턴스 수준에서 시간적 맥락 정보를 효율적으로 캡처할 수 있는 최초의 비디오 인스턴스 분할 transformer이다.
2. self attention의 유연성을 활용하여 제안된 시간 모델링 모듈, 즉 메신저 토큰 이동 및 시공간 쿼리 상호 작용은 모두 이미지 수준의 사전 훈련된 모델에 친숙하며, 비용이 적은 계산 오버헤드 및 매개 변수가 있다.
3. TeViT는 거의 convolution-free이며 SoTA VIS 결과를 얻는다. 초기 시간적 feature 융합과 쿼리로서의 비디오 인스턴스의 개념은 인스턴스 수준 인식 작업을 위한 효과적인 비디오 transformer를 구축하는 방법을 조명한다.
Related Work
Video instance segmentation
VIS는 MOTS(다중 객체 추적 및 분할), VOS(비디오 객체 분할)와 비슷하지만 MOTS는 주로 도시 장면 이해에 초점을 맞추고 VOS는 주어진 마스크로 특정 물체를 추적하는 것을 목표로 한다. 대표적인 VIS작업은 다음과 같다.


STEMSeg : 비디오 클립을 3D 시공간 볼륨으로 처리


SeqMask R-CNN : Mask R-CNN에 시퀀스 전파 헤드를 추가하여 프레임 간의 시간 관계를 설정

IFC : 프레임 수준 정보를 교환하기 위한 프레임 간 통신을 제시
본 논문에서는 프레임 수준과 인스턴스 수준 모두에서 시간적 맥락을 모델링하는 시간적으로 효율적인 프레임워크를 제시한다.
Temporal context modeling
시간적 맥락 모델링은 비디오 이해의 핵심 문제이다.



이러한 비디오 transformer가 비디오 분류에 초점을 맞추는 것과는 달리, TeViT는 인스턴스 수준의 비디오 이해를 위해 시간적으로 효율적인 transformer를 구축하는 것을 목표로 한다.
Method
Overall Architecture

TeViT에는 transformer 기반 백본 네트워크와 쿼리 기반 헤드 네트워크가 포함되어 있다.
일련의 비디오 프레임이 주어지면, transformer 백본은 feature 추출을 수행하고 다중 스케일 피라미드 feature를 생성한다. 쿼리 기반 헤드 네트워크는 비디오 인스턴스를 예측하기 위해 백본 feature map을 사용하여 무작위로 초기화된 인스턴스 쿼리를 취한다.
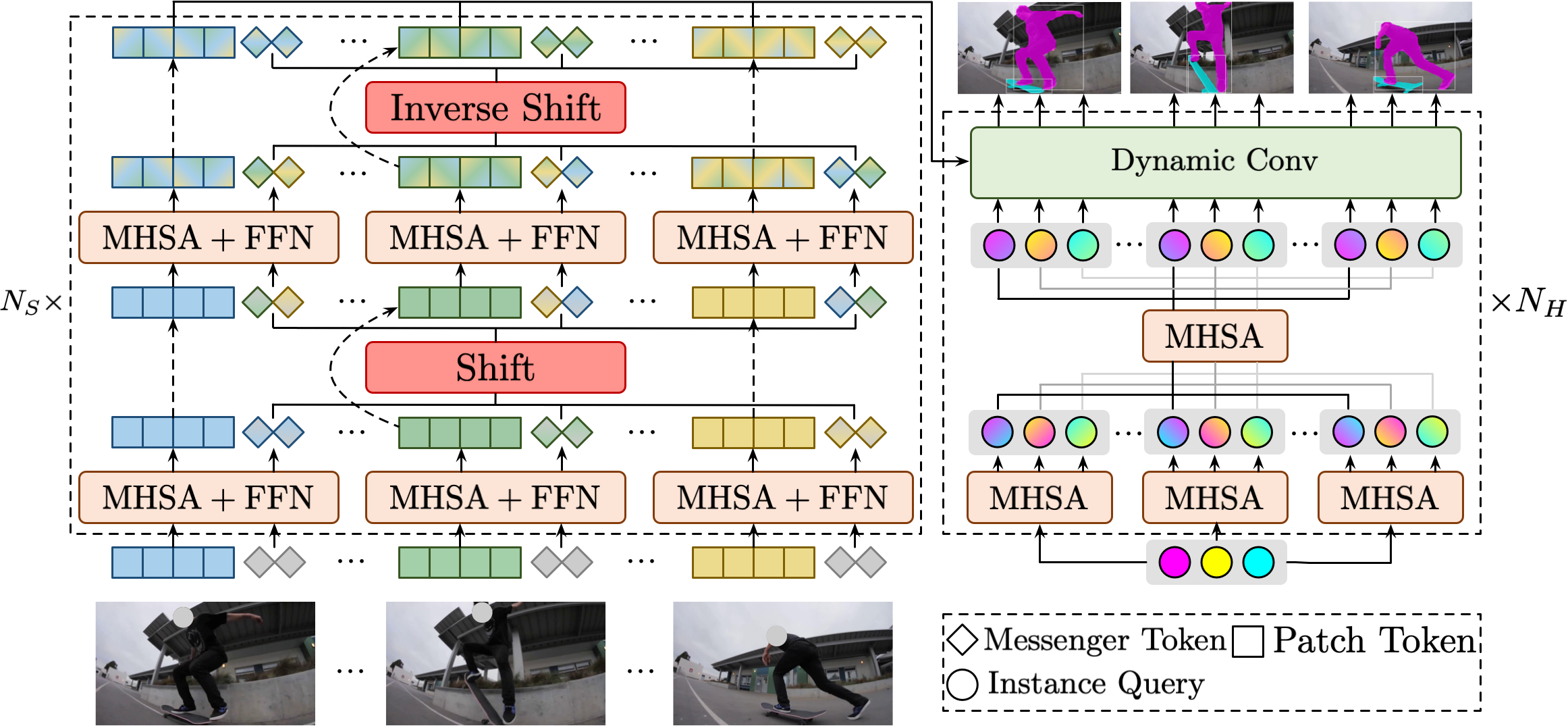
Messenger Shift Transformer Backbone
이전의 VIS 방법에서 백본 네트워크는 프레임별 방식으로 feature 추출만 수행하고 비디오 프레임에 내재된 풍부한 맥락 정보를 무시한다. 대조적으로, MSG-Transformer에서 영감을 받아, TeViT 그림의 왼쪽과 같이 상향식으로 매우 효율적인 시간 컨텍스트 모델링을 수행하는 messenger shift tansformer(MsgShifT)를 제안한다. 일반성을 잃지 않고 pyramid vision transformer(PVT)를 기반으로 MsgShifT를 구축한다.

구체적으로 T 프레임 HxW 크기의 비디오가 주어졌을 때,
{xi}Ti=1 ∈ RT x 3 x H x W,
각 프레임을 패치 크기 P로 HW/P2 개의 패치 토큰으로 나누고 선형 투영한 임베딩을 {f0i}Ti=1, (크기는 T x HW/P2 x C)
그리고 M(메신저 토큰의 갯수) x C(채널 수)개의 랜덤으로 초기화된 학습가능한 임베딩을 m0라 하자.
패치 토큰과 메신저 토큰 임베딩을 합쳐서 MsgShifT의 입력 joint 토큰으로 사용하며 다음과 같이 나타낼 수 있다.
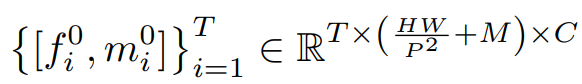
(m0i는 m0의 copycat)
TeViT 그림의 왼쪽 MsgShifT 계층을 Ns(= 4)개 만큼 거치며 MHSA과 FFN은 프레임 수 T에 대해 프레임당(per-frame) 방식으로 적용된다.

FFN 다음으로 프레임 간의 시간적 정보 교환을 수행한다. 메신저 시프트 메커니즘은 메신저 토큰을 입력으로 사용하고 시간 축을 따라 메신저 토큰을 이동시켜 시간 맥락 모델링을 구축한다.

메신저 토큰을 G개의 그룹으로 나누고 시간 단계(S)와 방향(D)을 따라 이동한다. 다양한 시간 단계와 방향을 통해 메신저 토큰은 과거 및 미래 프레임과 시간적 맥락 교환을 달성할 수 있다. 두번째 메신저 시프트는 역연산을 적용해 다시 원래대로 돌아가는데, 네트워크가 깊어지는 것에 대비해 안정적인 시간 수용 영역을 유지하기 위함이다.
MsgShifT 계층을 하나를 거치면, feature map 크기는 1/4이 된다. 그렇게 4번의 MsgShifT 계층을 거치면 입력 이미지에 대해 stride가 4,8,16,32인 feature map F1, F2, F3, F4 를 얻게 되며 헤드 네트워크에서 예측을 하는 데 사용된다.
이전의 transformer 기반 VIS 접근 방식은 이미지 수준 feature 추출 후에 transformer 인코더를 사용하여 시간적 특징 융합만 수행한다. 반면 MsgShifT는 백본 네트워크에서 초기 시간적 융합을 수행한다. 메신저 토큰이 무작위로 초기화되고 시프트 조작에 매개 변수가 없기 때문에 이 모듈은 이미지 수준 사전 훈련 모델에 친화적이다.
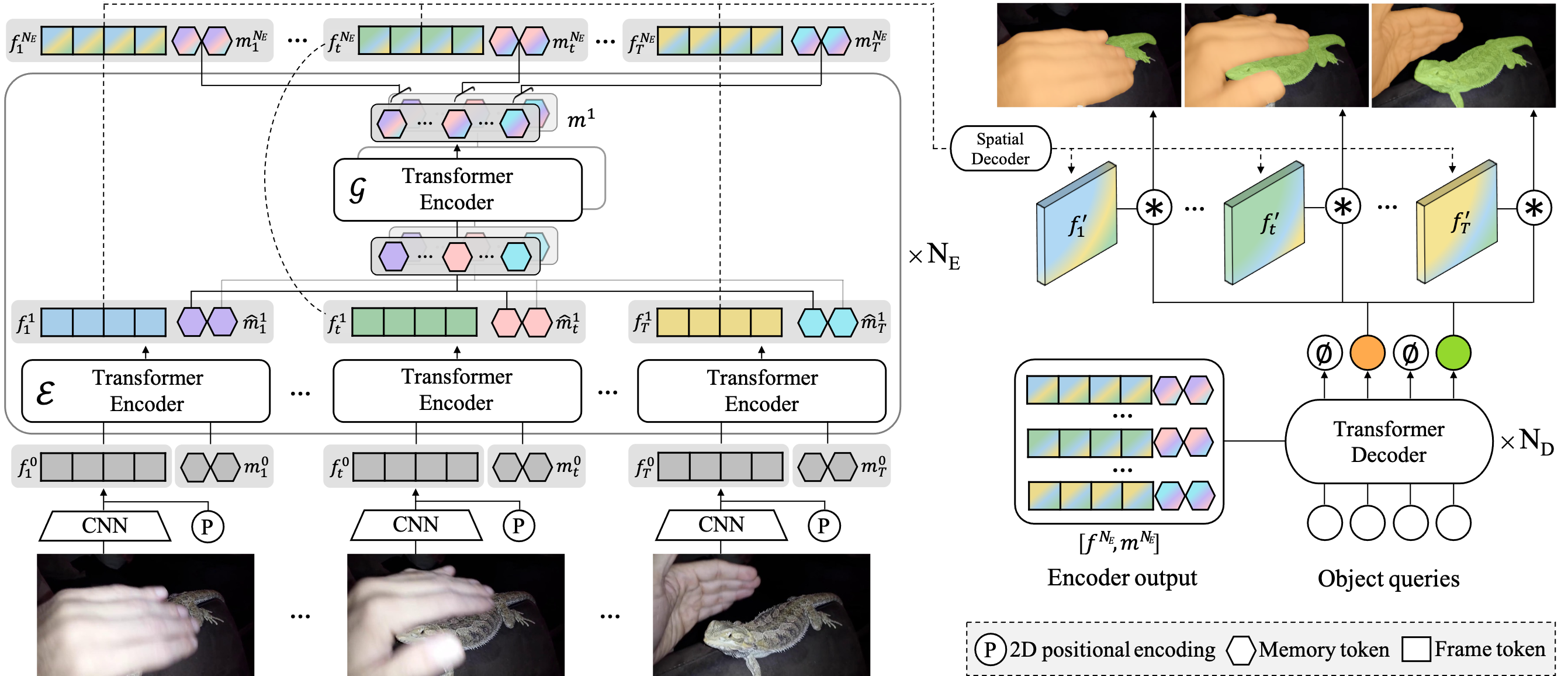
Spatiotemporal Query Interaction Head
VIS 헤드 네트워크에서도 인스턴스 수준에서 시간적으로 효율적인 시공간 맥락 모델링을 강조한다. 이를 위해 최근 SoTA 쿼리 기반 이미지 수준 인스턴스 분할 방법인 QueryInst를 기반으로 한 시공간 쿼리 상호 작용(STQI) 헤드 네트워크를 제안한다.
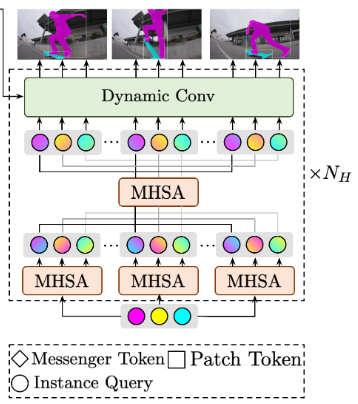
헤드 네트워크는 NH개의 STQI 헤드를 포함하며
Feature map F1, F2, F3, F4와 함께 고정 길이 인스턴스 쿼리 Q ∈ RNq x T를 입력으로 사용해 Nq x T 인스턴스 예측을 생성한다. Nq는 인스턴스 쿼리의 갯수이며 Q는 훈련 중에 무작위로 초기화 및 최적화 된다.
또한 네트워크에는 이전 제안으로 제안 상자 B ∈ RNq x 4 세트가 포함되어 있다. 이에 대한 자세한 내용은 QueryInst 참조. (QueryInst 부분만 읽으셔도 됩니다. 짧은 글이니 읽어보세요. Q와 B를 지속적으로 업데이트하는 아이디어입니다.)
인스턴스 쿼리는 먼저 각 프레임 T만큼 복사되고 두 개의 연속적인 parameter-shared MHSA 모듈은 시간 및 공간 차원을 따라 순서대로 인스턴스 쿼리에 대해 작동한다.

1:T는 1에서 T까지의 범위를 나타낸다.
그 후 Q는 동적 컨볼루션 모듈에 공급되고 백본 네트워크로부터 입력된 feature map과 상호작용한다.
동적 컨볼루션 모듈의 출력은 다음 헤드의 입력 쿼리 역할을 한다.
마지막으로 작업별로 특정한 헤드(i.e., classification head, box head and mask head)는 비디오 인스턴스의 시퀀스를 예측한다.

p, b, m은 순서대로 confidence scores, bounding boxes and instance foreground masks.
STQI의 장점은 주로 still-image 인스턴스 예측 헤드에 대한 최소 수정에서 비롯된다. STQI는 parameter-shared MHSA에 의해 인스턴스 수준에서 매우 효율적인 시간 맥락 모델링을 달성하지만 추가 매개변수를 포함하지 않는다. (매개변수 효율적이라는 뜻)
Matching and Loss Function
실제 주석(ground truth) y

헝가리안 알고리즘에 의해 예측과 실제 주석 사이의 이분 매칭을 수행한다.
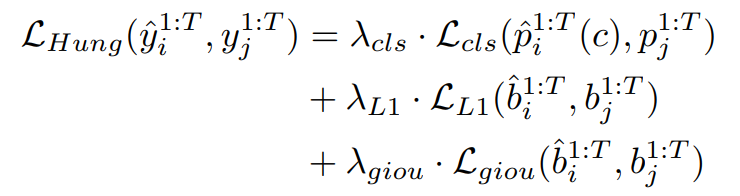
위 부터 순서대로 classification loss, L1 loss, GIoU loss이다. λ는 하이퍼 피라미터.
공식에는 나와있지 않은데, 연구진은 추가로 dice coefficient를 사용했다고 함.
Experiments
Datasets and Evaluation Metrics
데이터셋은 YouTube-VIS-2019, YouTube-VIS-2021, OVIS
평가지표는 Video Instance Segmentation에서 정의한 기준을 따른다.
Implementation Details
하이퍼 파라미터는 QueryInst의 설정을 따른다. TeViT의 시간 효율적인 설계로 인해 시간 모델링 매개 변수를 훈련하기 위해 의사 비디오 데이터를 생성할 필요가 없으며, 대신 먼저 COCO 데이터 세트에서 이미지 수준 인스턴스 분할을 위한 transformer 기반 QueryInst를 훈련한 다음 그 가중치로 TeViT를 초기화한다.
optimizer로 AdamW를 사용한다.
YouTube-VIS-2019에서 8개의 Tesla V100 GPU로 약 4시간 만에 훈련할 수 있으며, 이는 이전의 transformer 기반 방법보다 훨씬 빠르다.
추론 시, 모든 프레임은 훈련 설정에 관계없이 360 × 640으로 크기가 조정된다.
주요 결과를 위해 PVT-B1 기반 MsgShifT를 백본으로 사용한다.
Main Results
YouTube-VIS-2019 데이터셋에 대한 비교.

~SeqMask R-CNN까지의 앞의 두 그룹은 CNN 기반, 뒤의 두 그룹은 transformer 기반 모델을 의미한다.
MST의 체크표시는 다중 스케일 전략을 사용했을 때 이다. VisTR보다 약 10AP 더 높은데도 추론 속도는 더 빠르다.
YouTube-VIS-2021 데이터셋에 대한 비교.
† 표시는 https://arxiv.org/abs/2104.05970 에서 제안한 학습 방식 사용.

OVIS 데이터셋에 대한 비교.
‡ 표시는 https://arxiv.org/abs/2102.01558 에서 제안한 학습 방식 사용.
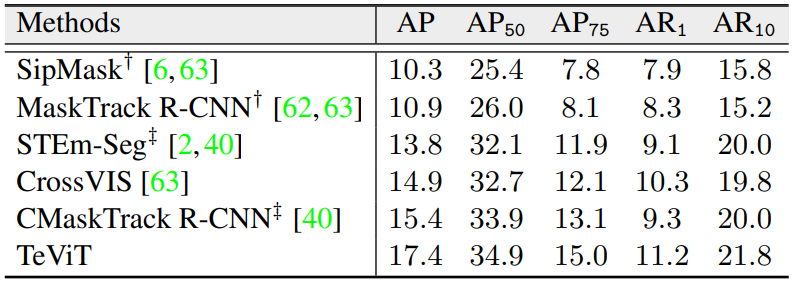
세 데이터세트에서 모두 가장 좋은 성능을 보여주었다.
Ablation Study
본 논문의 핵심인 MsgShift Mechanism과 Spatiotemporal Query Interaction의 ablation study.
성능이 좋아졌는데도 계산 비용인 GFLOPs는 거의 늘지 않았다.
이는 두 메커니즘의 설계가 매우 효율적이라는 것을 보여준다.

시공간 쿼리 상호작용의 변형들과 비교한다.
Spatial Only 는 QueryInst에서의 방법,
Fused Space-Time 시간과 공간 쿼리를 따로 적용하지 않고 한번에 적용하는 방법이다.
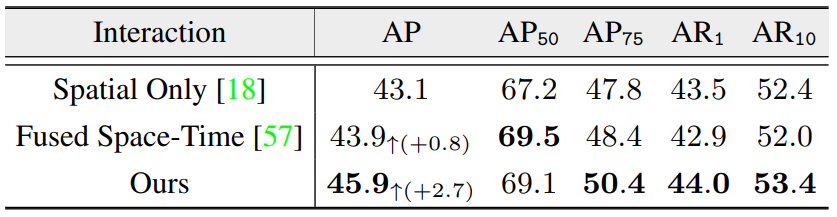
저자는 Fused space-time에서 인스턴스 쿼리 간의 일대일 쿼리가 공동 시공간 attention에서 잘못 정렬될 수 있기 때문에 성능이 저하되었을 것이라고 주장한다.
메신저 토큰에 적용된 추가 조작에 대한 비교

위와 비슷한데, 위는 shift block 에서 메신저 토큰에 적용되는 추가적인 연산을 의미하는 것 같고, 아래는 메신저 토큰 사용 유무에 대한, 예를 들어 conv는 컨볼루션 레이어를 사용하여 시간에 대응하는 feature를 만든다던가 하는 것 같다. 확실하진 않지만 펼쳐진 상태에서는 컨볼루션을 하지 못 하기 때문에 그렇게 추측함.

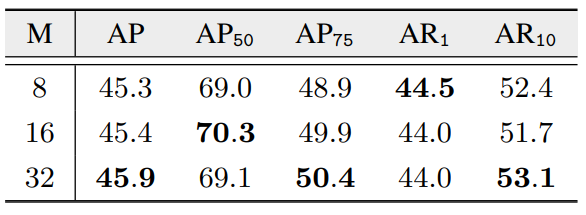
메신저 토큰의 갯수에 대한 비교.
뭔가 명확하지 않고 좀 들쑥날쑥 한데 연구진은 M=32를 사용했다고 함.
훈련 클립 길이가 미치는 영향에 대한 비교.
프레임 수 T가 커질수록 성능이 좋아지긴 하지만 커질수록 점점 성능 향상이 더뎌지고 계산 비용이 많이 듦으로 연구진은 T=5로 설정했다.

프레임 수 T와 메신저 시프트 단계 S의 각 값에 대한 비교.

transformer 기반 VIS 모델을 백본으로 ResNet-50을 사용했을 때의 성능 비교.
백본으로 ResNet을 사용하면 메신저 시프트를 사용할 수 없기 때문에 STQI만 사용했는데도 다른 모델들보다 좋은 성능이 나오는 것을 볼 수 있다.
3행이 STQI를 사용하지 않았을 때 인데 확실히 성능이 줄어들었다.

추론 단계에서 메신저 토큰의 값을 다시 초기화하여 진행했을 때의 결과이다. 생각보다 많은 성능저하가 일어나지 않았음을 볼 수 있다.

연구진은 이러한 현상이 메신저 토큰 자체는 특정 정보를 많이 갖고있지 않다는 것을 암시한다고 생각했다.
Conclusion
본 논문에서는 VIS를 위한 시간적 맥락을 충분히 활용할 수 있는 가볍고 효과적인 솔루션을 제공한다. 기존 ViT와 쿼리 기반 이미지 수준 인스턴스 분할 방법을 기반으로 메신저 시프트 및 시공간 쿼리 상호 작용 메커니즘을 포함하는 TeViT VIS 방법을 제안한다. TeViT는 몇 가지 매개 변수와 부수적인 추가 계산 비용만 가져오면서 프레임 수준 및 인스턴스 수준 시간 기능 상호 작용을 모두 수행한다. 실험은 TeViT가 이전의 SoTA 방법보다 훨씬 더 나은 결과를 얻을 수 있음을 보여준다.



