4월 26일 공개된 Understanding The Robustness in Vision Transformers (비전 트랜스포머의 견고성 이해)
Github
Paper (arixiv)

Abstract
최근의 연구는 Vision Transformer(ViT)가 다양한 손상(=corruption)에 강한 견고성을 보인다는 것을 보여준다. 이러한 특성은 부분적으로 self attention 메커니즘에 기인하지만, 여전히 체계적인 이해가 부족하다. 본 연구에서는 강력한 표현을 학습하는 데 있어 self attention의 역할을 살펴본다. 본 연구는 ViT에서의 흥미로운 특성에 의해 동기 부여되는데, 이는 self attention이 개선된 중간 수준의 표현을 통해 견고성을 촉진할 수 있음을 보여준다. 또한 attentional 채널 처리 설계를 통합하여 이 기능을 강화하는 Fully Attentional Network(FAN) 제품군을 제안한다. 다양한 계층적 백본에서 설계를 종합적으로 검증하며, semantic segmentation과 object detection 두 가지 다운스트림 작업에서 최첨단 정확성과 견고성을 보여준다.
Introduction
ConvNet과 달리 ViT는 self attention 설계 덕분에 다양한 손상에 대해 더 견고하다고 알려져 있다. 하지만 self attention 없이도 일반화와 견고성에서 ViT만큼이나 뛰어난 ConvNeXt 등의 모델이 나왔으며, 이것은 self attention의 실제 역할에 대한 흥미로운 질문을 제기한다.
본 연구에서는 위의 질문에 대한 답을 찾는 것을 목표로 한다. 이 여정은 이미지 분류 중 ViT에서 객체의 의미 있는 분할이 자연스럽게 나타난다는 흥미로운 관찰로 시작한다. 이것은 self attention이 시각적 그룹화를 통해 향상된 중간 수준의 표현과 견고성을 촉진하는지 궁금하도록 한다. 추가로, affinity matrix의 유의한 고유값이 주 클러스터 구성 요소에 해당하는 스펙트럼 클러스터링(본 논문의 이해를 위해 꼭 보세요!)을 사용하여 각 ViT 계층의 출력 토큰을 분석한다. 본 연구는 유의한 고유값의 수와 입력 손상으로 인한 섭동 사이의 흥미로운 상관관계를 보여준다. 둘 다 중간 수준 계층에 걸쳐 크게 감소하며, 이는 이러한 계층에 대한 그룹화 및 견고성의 공생을 나타낸다.
그룹화 현상의 근본적인 이유를 이해하기 위해, Information Bottleneck(IB)의 관점에서 self attention(SA)을 해석한다. 이는 잠재된 feature 표현과 대상 클래스 label 사이의 상호 정보를 최소화하여 중요하지 않은 정보를 짜내는 압축 프로세스이며, 잠재 feature와 원시 데이터 사이의 상호 정보를 최대화한다. 본 연구에서 self attention은 IB 목표의 반복 최적화 단계로 쓰일 수 있음을 보여준다.

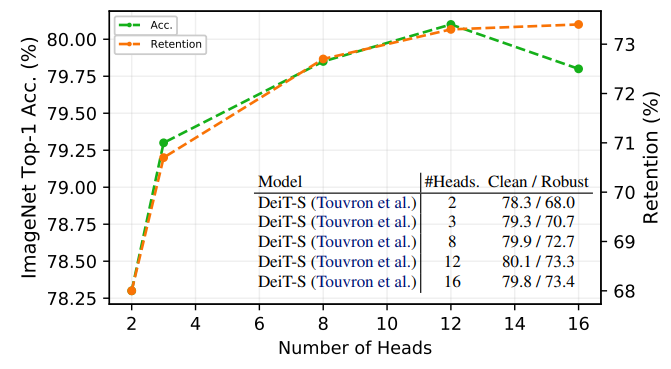
위 그림에서 a과 같이, 기존의 ViT는 multi-head self attention(MHSA), MLP block을 채택하여 여러 개의 분리된 헤드로부터 정보를 집계한다. 결과적으로 서로 다른 헤드의 정보를 어떻게 집계하는지가 중요하며 본 연구에서는 그룹화와 견고성의 공생을 강화하는 집계 설계를 고안하는 것을 목표로 한다.
왼쪽의 b와 같이, reweighting을 통해 채널 선택을 촉진하는 새로운 채널 처리 설계를 제안한다. MLP 블록의 정적 컨볼루션 작업과 달리 유동적이고 content에 의존하므로 보다 강력한 표현을 이끌어낸다. 제안된 모듈은 새로운 transformer 백본 제품군을 만들어내며, 설계 후에 FAN(Full Attentional Networks)을 만들었다.
본 연구의 기여는 다음과 같다.
- 그룹화와 information bottleneck, 강력한 일반화를 통합하는 framework 제안
- 제안된 FAN은 체계적으로 개선된 견고성을 제공한다. 비슷한 모델 크기에서 ResNet-50, Swin-T 및 최근 SOTA인 ConvNeXt-T보다 더 뛰어난 성능을 보여준다.
- 또한 의미론적 분할과 객체 감지에서 광범위한 실험을 수행한다. 제안된 설계에서 얻은 견고성의 상당한 이득이 이러한 다운스트림 작업으로 이전될 수 있음을 보여준다.
Fully Attentional Networks
Preliminaries on Vision Transformers
보통의 ViT는 먼저 입력을 n개의 패치로 나누고 X(=[x1,... , xn]) ∈ Rd x n로 임베딩한 다음 WK, WQ, WV 각 선형 변환을 적용하여 키 K(=WKX), 쿼리 Q(=WQX), 벨류 V(=WVX)를 얻는다. 그런 다음 attention matrix를 계산한다.

Z(=[z1,... , zn])는 결과 토큰, feature, WL는 선형 변환, d는 scaling factor.
그리고 정규화 후 MLP에 공급된다.
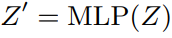
Intriguing Properties of Self-Attention
ViT의 토큰 feature z에서 의미 있는 클러스터가 출현한다는 관찰로부터 시작한다. 그리고 그러한 현상을 스펙트럼 클러스터링으로 조사한다. 여기서 토큰 affinity matrix는 Sij = zTi zj로 정의한다. S의 유의 eigenvalue의 다중성으로 주요 클러스터 수를 추정할 수 있기 때문에, 서로 다른 ViT-S , FAN-S블록에 걸쳐 eigenvalue의 수를 표시한다. 그리고 가우스 노이즈를 공급함으로써 노이즈에 의한 섭동이 eigenvalue와 함께 감소함을 관찰한다.
나도 선형대수에 대한 지식이 해박하지는 않지만 구글링으로 좀 찾아보고 생각해 본 것을 정리해보자면
일 단 이 글에서 zero-eigenvalue는 이미지가 뭉개져 있는 것을 의미한다고 알 수 있고 IB의 관점에서 중요하지 않은 정보를 최대한 제거하는 게 중요하기 때문에, zero-eigenvalue가 늘어난다 = 이미지의 주파수가 낮아진다 = 중요한 정보만 남는다라고 생각할 수 있다.
그래서 위 그래프는 모델이 깊어질수록 입력 노이즈의 비율은 점점 줄어들고 zero-eigenvalue는 증가하는 것을 보여주는 것이라고 할 수 있다. 연구진은 이것을 토큰의 그룹화 라고 했다. FAN에서의 그룹화 과정 시각화는 다음과 같다.


위 그래프는 모델 깊이에 따른 입력 노이즈의 감쇠를 나타낸 것이다. ResNet-50은 다른 두 모델에 비해 견고성이 부족하다는 것을 볼 수 있다.
An Information Bottleneck Perspective
X가 관측된 노이즈 입력이고 X'가 목표인 분포 X ∼ N (X' , ε)가 주어졌을 때, IB는 X'를 예측하기 위해 Z가 X에 있는 관련 정보를 포함하도록 하는 매핑 f(ZㅣX)를 찾는다. 이 목표는 다음과 같은 최적화 문제로 공식화할 수 있다.

X와 Z간의 정보량은 최소화 -> 정보 압축
Z와 X'간의 정보량은 최대화 -> 중요한 정보는 유지
SA 블록의 경우 정보를 최적화하기 다음과 같이 쓸 수 있다....

행렬 형태로 나타내면

위의 제안은 SA가 유사한 입력 xi를 클러스터 구조를 가진 표현 Z로 집계한다는 것을 보여줌으로써 vanlia self attention과 IB 사이의 흥미로운 연결을 확립한다.
더 자세한 증명은 부록에 있긴 있는데 봐도 도통 무슨 소린지 모르겠다...
아무튼 간단히 요약하자면 self attention이 불필요한 노이즈는 버리고 중요한 정보들을 그룹화 함으로써 자연스럽게 IB의 역할도 겸하고 있고, 결국 transformer는 그룹화 및 노이즈 필터링의 반복으로 간주할 수 있다는 말이다.
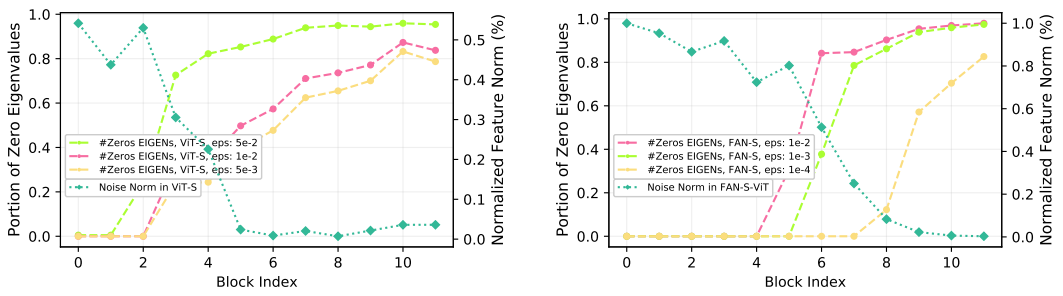
현재 많은 ViT 아키텍처들은 각 헤드가 서로 다른 객체 구성요소에 집중하는 MHSA를 채택하며, MHSA은 각각의 IB들의 혼합으로 해석될 수 있다. 다음 그림과 같이 고정된 채널에서 헤드 수가 많을수록 표현성과 견고성이 향상되지만 헤드당 채널 수가 너무 적어지면 정확도가 떨어진다.
Fully Attentional Networks
본 연구의 설계는 두 가지 중요한 측면에 의해 추진된다.
- 더 많은 구성 표현을 촉진하기 위해, 일부 헤드 또는 채널이 다른 헤드보다 더 중요한 정보를 캡처하기 때문에 채널 재가중 방식을 도입하는 것이 바람직하다.
- 재가중 메커니즘은 촉진된 그룹화 정보를 활용하기 위해 각 채널에 대한 보다 공간적으로 전체적인 고려를 포함해야 한다.
위 목표의 출발점은 다음 그림의 a와 같은 channel attention(CA)을 도입하는 것이다.
CA의 공식은 다음과 같다.

SA와 달리 CA는 feature 공분산을 활용하는 토큰 차원 n 대신 채널 차원을 따라 attention을 계산한다. 상관 값이 큰 채널은 집계되고 상관 값이 낮은 이상치 feature는 격리된다.
Efficient Channel Self-attention
기존의 CA에는 두 가지 한계점이 있다.
- 계산 복잡도가 D2에 비례하기 때문에 계산 오버헤드가 크다.
- 대부분의 채널이 작은 attention 가중치를 가지게 됨으로써 채널의 일부만이 학습에 기여하기 때문에 매개변수 효율성이 낮다.
문제점을 극복하기 위해 두 가지 수정을 제안한다.
- 토큰 feature의 행렬을 계산하는 대신 채널 차원에 걸쳐 평균을 내 토큰 프로토타입 Z̄ ∈ Rn x 1를 생성한다. 그리고 토큰 feature와 토큰 프로토타입의 상관행렬을 계산한다.
- softmax 대신 sigmoid를 사용하고, matmul을 사용한 채널 집계 대신 토큰 feature를 그냥 곱한다. 이 기능은 채널이 중요한 feature 중 몇 개만 선택하도록 강요하지 않으며 상관관계를 기반으로 각 채널의 가중치를 재조정한다. 가중치가 큰 채널이 다른 채널의 중요성을 제한해서는 안된다.
새로운 설계는 다음 식을 통해 계산된다.

σ는 토큰 차원을 따르는 softmax 연산이다. 아키텍쳐는 위 그림의 b에 나와있다.
새롭고 효율적인 CA는 계산 비용이 적게 드는 동시에 성능을 크게 향상한다.
Experiment Results & Analysis
Experiment details
Imagenet-C (IN-C), Cityscape-C, COCO-C 데이터셋으로 견고성 검증.
Out-of-distribution 상황에서 일반화 테스트를 위해 Imagenet-A, Imagenet-R에서 정확도 평가.
ImageNet-1K에서 깨끗한 데이터에서의 성능 평가.
T, S, B, L로 약칭되는 4가지 모델 크기(Tiny, small, base, large) 설계.
비교를 위해 ResNet-50과 ViT-S를 각각 CNN과 transformer의 대표 모델로 사용. (FAN-S와 비슷한 크기)

Analysis
견고성 향상을 위한 다양한 훈련 트릭 평가.
Knowledge distillation (KD) 및 대규모 데이터셋 사전 훈련과 같은 잘 알려진 트릭은 확실히 도움이 된다.
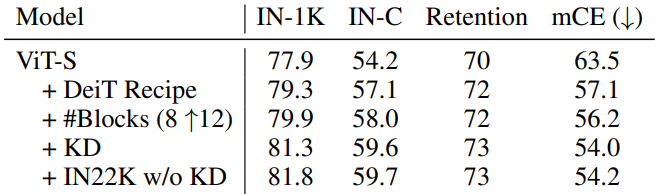
CNN 모델 또한 Squeeze-and-Excite attention(SE)을 추가하는 등의 다양한 트릭으로 견고성을 크게 향상할 수 있다. 앞으로 ViT 모델과 ResNet-50을 비교할 때는 공정성을 위해 모든 트릭을 동원한 가장 성능이 좋은 version으로 비교하며 트릭을 사용한 모델은 *표시를 한다.
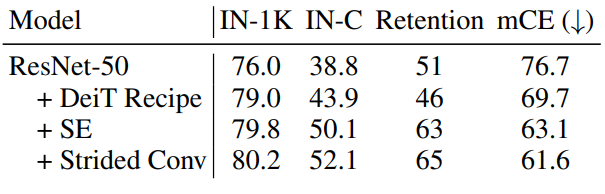
모든 트릭을 동원한 ResNet-50과 ViT-S의 비교. 견고성에서 ViT가 월등하며, self attention의 확실한 이점을 보여준다.

최신의 CNN 모델인 ConNeXt는 최신의 ViT 모델인 SWIN transformer보다 좋은 견고성을 보여주었다. IB의 관점에서 이것을 해석해보면 이전에 말한 바와 같이 SA는 필수 토큰을 선택하는 과정에서 IB의 역할을 자연스럽게 하고 있는데, SWIN에서는 미리 정해진 window 영역 내에서만 attention을 하도록 강제하기 때문에 때문이라고 본다.

Fully Attentional Networks
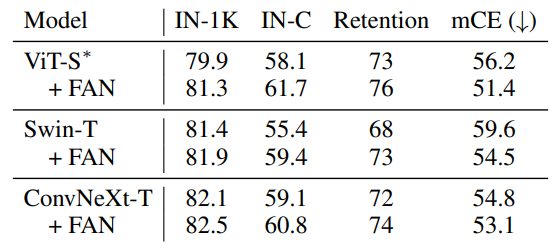
메모리 소비, 정확도 및 견고성의 측면에서 다양한 형태의 CA 비교. 본 논문에서 제안한 ECA가 제일 좋음.

기존 모델에 ECA를 추가한 뒤 비교. 모든 모델에서 성능이 개선되었다.
앞에서의 모델 깊이에 따른 클러스터링 그래프는 클러스터링이 주로 FAN 모델의 최상위 단계에서 나타나며, 하위 단계는 로컬 시각적 패턴을 추출하는 데 초점을 맞춘다는 것을 보여준다.

이에 영감 받아 하위 두 단계에 다운샘플링과 컨볼루션을 추가한 다음 컨볼루션 후에 ECA를 적용하는 FAN-Hybrid 모델을 제안한다. FAN-Hybrid의 초기 단계를 위해 ConvNeXt를 사용한다. FAN-ConvNeXt은 FAN-ViT보다는 덜 견고했지만 FAN-Hybrid는 FAN-ViT보다 뛰어난 정확도와 견고성을 보여준다. 자세한 아키텍처는 부록 참조.
Comparison to SOTAs on various tasks
이미지 분류(ImageNet-C), 의미 분할(Cityscapes-C) 및 객체 감지(COCO-C)를 포함한 다양한 다운스트림 작업에서 일반적인 손상과 비교하여 다른 SOTA 방법과 FAN의 견고성을 평가한다. 또한 ImageNet-A 및 ImageNet-R을 포함한 다양한 다른 견고성 벤치마크에서 FAN의 견고성을 평가하여 견고성 향상을 추가로 보여준다.
ImageNetC에서 견고성 비교. 공정한 비교를 위해 모든 모델을 크기에 따라 세 그룹으로 나눈다.
모든 모델 크기에서 FAN 모델은 다른 모든 모델을 크게 능가한다.
(†표시는 ImageNet-22K에서 미리 훈련한 모델)

분할 작업에 대해 Cityscapes-C에서 모델의 견고성 추가 평가

COCO-C에서 견고성 평가

ImageNet-1K 학습 모델을 테스트하여 out-of-distribution 샘플에 대한 견고성 평가.

Conclusion
본 연구에서는 SA이 토큰에서 자연스러운 클러스터 형성을 촉진한다는 것을 보여준다. 또한 SA의 속성에 대한 설명을 위해 IB의 관점에서 설명 프레임워크를 설정했다.
토큰 단계와 채널 처리단계 모두에서 attention을 활용하는 FAN을 도입했으며 FAN은 상당히 향상된 견고성을 보여준다.
ViT의 작동 메커니즘을 이해하는 데 새로운 관점을 제공하여 컨볼루션을 넘어서는 유도 편향의 가능성을 보여준다.



