4월 14일 공개된 Neighborhood Attention Transformer




Abstract
이미지 분류와 다운스트림 작업 모두에서 잘 작동하는 효율적이고 정확하며 확장 가능한 계층적 transformer인 NAT(Neighborhood Attention Transformer)를 제시한다. 각 쿼리에 대한 수신 필드를 가장 가까운 인접 픽셀로 현지화하는 간단하고 유연한 attention 메커니즘인 NA(Neighborhood Attention)를 기반으로 한다. 또한 FLOPs와 메모리 사용량은 swin transformer의 shifted window attention과 동일하지만 제약은 적으며 NA에는 국소 유도 편향이 포함되어 있어 픽셀 이동과 같은 추가 연산이 필요하지 않다.
NAT에 대한 실험 결과는 경쟁력이 있다. NAT-Tiny는 4.3 GFLOP와 28M의 매개 변수만으로 ImageNet에서 83.2%의 정확도(Top-1 accuracy), MS-COCO에서 51.4% mAP, ADE20k에서 48.4% mIoU에 도달한다.
(논문에서는 초반에 설명하지 않는데 이 논문의 핵심은 기존 ViT 개선 모델들처럼 패치를 사용하지 않고 컨볼루션을 이용한 다운샘플링 + 픽셀단위의 연산을 이용하여 패치를 사용하는 것 처럼 연산하고, attention을 마치 컨볼루션처럼 작동시키는 것에 있는 것 같다.)
Introduction
원래 transformer는 NLP에서 언어의 순차적 구조를 활용한 attention 기반 모델로 제안되었고, BERT와 GPT 등은 현재까지도 NLP에서 최첨단 아키텍쳐로 남아있다. 2020년 말, transformer를 비전 작업에 적용한 ViT가 제안되었다. 하지만 attention의 특성상 이미지의 해상도가 높을수록 계산 비용이 기하급수적으로 늘어나는 것이 주요 문제 중 하나였다. 또 다른 문제는 컨볼루션 연산에서는 locality, 변환 등분산, 2차원 구조와 같은 유도 편향으로부터 이익을 얻는 반면, transformer 연산은 이미지에 맞지 않는 1차원 연산이라는 것이다. 이 문제를 해결하기 위해 local attention을 활용한 swin transformer, blocked local attention을 활용한 HaloNet 등이 제안되었다.
본 논문에서는 NA(Neighborhood Attention)을 기반으로 한 NAT(Neighborhood Attention Transformer)를 제안한다. NA는 각 쿼리 토큰의 수신 필드를 키 값의 해당 토큰 주변의 고정 크기 이웃으로 제한한다. 이웃의 크기를 조정함으로써 변환 불변성과 등변성 사이의 균형을 유지하는 방식으로 수용 필드를 제어할 수 있게 한다. NAT의 각 계층에는 공간 크기를 절반으로 줄이는 다운 샘플링 작업이 뒤따른다. 이와 유사한 설계는 swin, focal transformer와 같은 다른 모델에서도 찾아볼 수 있지만 임베딩을 위한 컨볼루션 커널을 추가한 것이 차별점이다.
Related Works
Multi-Headed self attention
transformer에 대해 잘 모른다면 위 링크로 들어가서 attention ~ transformer 부분을 다 읽고 오는 것을 추천한다. 내가 본 것 중에서 가장 잘 설명되어 있는 곳이다.
Models using local attention
Swin Transformer : 다음 그림과 같이 이미지를 여러 개의 파티션으로 나누고 파티션 내의 토큰끼리만 attention을 수행하며 피라미드 형태의 계층적 구조를 사용한다.

Halo Net : 다음 그림과 같은 blocked local attention을 사용했다.

Focal Transformer : 다음 그림과 같이 가까운 토큰에는 fine attention, 먼 토큰에는 coarse attention은 적용하는 focus attention을 사용했다.

Recent Convolutional models
ConvNeXt : swin transformer의 영향을 받았지만 attention 기반이 아닌 ResNet-50을 개선한 모델이다. 컴퓨터 비전에서 transformer가 지금 핫하지만 attention을 사용하지 않고 swin transformer의 성능을 뛰어넘어 여전히 CNN 또한 강하다는 것을 보여주었다.
Method
이 섹션에서는 self attention의 국소화인 Neighborhood Attention를 소개한다. 이것은 self attention에 비해 계산 비용을 줄일 뿐만 아니라 컨볼루션과 유사한 국소 유도 편향을 도입한다. 이것은 이웃 크기 L에 대해서 작동한다. 또한 swin transformer의 계층적 구조에 overlapping 컨볼루션을 추가한 Neighborhood Attention Transformer를 소개한다.
Neighborhood Attention
컨볼루션의 locality에 영감을 받은 NA은 각 픽셀이 컨볼루션처럼 주변 픽셀에만 접근할 수 있도록 설계되었다.
좌표 (i,j)에 있는 픽셀의 이웃 공간을 인덱스의 집합인 ρ(i,j)로 표시한다. 이웃 크기가 L x L 일 경우 p(i,j)의 원소의 갯수는 L2개이다. 따라서 NA를 다음과 같이 정의할 수 있다.

그냥 attention의 수식과 같지만 기준픽셀에 대한 위치 편향 B가 추가되었다.
ρ(i,j)는 다음 그림처럼 주변 경계가 입력 크기를 초과할 때 가능한 모든 픽셀을 포함하므로 L x L이 피쳐맵 크기 이상일 경우 self attention과 같게 된다(위치 편향만 뺀다면).

모서리 픽셀에 대해 수용 필드 크기를 강제로 유지하는 것은 L의 크기가 커짐에 따라 NA가 self attention과 점점 유사해지도록 의도한 것이다.
NA는 계산 비용이 해상도에 대해 선형적이기 때문에 효율적이다.

Complexity analysis
NA는 창 크기가 같을 때, swin과 같은 window-based self attention과 동일한 수의 FLOP을 가지고 있다. 이 절에서는 복잡성을 분석하고 메모리 사용에 대해 논의한다. (단순화를 위해 single-headed attention의 경우로 함)
계산 비용을 구해보자.
H x W x C 크기의 피쳐맵이 주어지면 QKV 선형 투영에는 self attention, swin, NA 셋 다 3HWC2의 동일한 비용이 발생한다. (하나의 픽셀 좌표에 대해서 그 크기는 1xC, Q를 얻기 위해 1xC x HWC, QKV에 대해 모두 수행하면 3HWC2. - 논문에서는 각 계산 비용의 결과만 나와있고 도출과정은 자세히 설명하지 않기 때문에 제 추측이라는 것을 미리 알립니다.)
swin의 경우 창 크기를 L 이라고 할 때, 모든 창의 갯수 H/L x W/L,
L x L개의 쿼리에 대해서 L x L x C 크기의 키를 적용하니 H/L x W/L x L x L x L x L x C = HWCL2.
밸류를 반영할 때는 H/L x W/L개의 창에 L x L의 유사도를, L x L x C 의 밸류에 적용하니 똑같이 HWCL2.
합치면 2HWCL2.
NA의 경우는 swin과 같고,
self attention의 경우 HW개의 쿼리에 대해서 HWC 크기의 키를 적용하니 H2W2C. 밸류 반영 추가 2H2W2C.
NA의 작동 방식이 컨볼루션과 유사하니 컨볼루션과도 비교한다.
컨볼루션의 경우 HWC의 피쳐맵에 LLC의 커널을 적용하니 HWC2L2.

컨볼루션은 메모리 효율성이 높고 복잡성은 채널에 대해서는 2차, 창 크기(L x L)에 대해서는 선형이다.
NA의 계산 비용이 채널 수가 많아지더라도 컨볼루션보다는 덜 빠르게 증가한다는 것을 알 수 있다.
따라서, 2D NA는 실제 시나리오에서 2D 컨볼루션보다 계산적으로 덜 복잡하지만, QKV 투영으로 인한 추가 비용으로 인해 어려움을 겪는다고 결론 내릴 수 있다.
Implementation
NA를 정확하게 복제하거나 인접 픽셀을 추출하는 작업은 주요 딥러닝 라이브러리에 존재하지 않고, 있더라도 매우 비효율적이고 메모리 소모가 클 것이기 때문에 NA를 위한 custom CUDA 커널을 작성했다. 세부사항은 논문의 부록 A 참조.
Neighborhood Attention Transformer

2×2 stride의 3×3 컨볼루션을 사용하여 입력을 1/4로 만든다. 이것은 4x4패치와 임베딩 레이어를 사용하는 것과 유사하지만, 겹치지 않는 컨볼루션 대신에 겹치는(overlapping) 컨볼루션을 사용한다. 겹치는 컨볼루션은 비용이 증가하고 더 많은 매개변수를 발생시키지만, 모델을 재구성하여 이를 절충한다.
NAT는 4개의 level로 구성되며 4배 다운샘플링을 하는 첫 레이어의 tokenizer를 제외하면 모든 level에서 채널 2배 + 2배 다운샘플링된다. 패치를 사용하지 않고 이러한 방법을 사용한 이유는 다른 계층적 attention 모델들의 성공과 CNN 구조에 영감을 받았으며, 다운스트림 작업에도 더 쉽게 적용할 수 있다고 한다.
Experiments
항상 논문 리뷰하다 보면 앞에서 진이 다 빠져서 실험 부분은 대충하게 되는 것 같다... 어차피 별 내용 없기도 하고.
Classification
ImageNet-1k accuracy

Object Detection

Semantic Segmentation

Ablation study
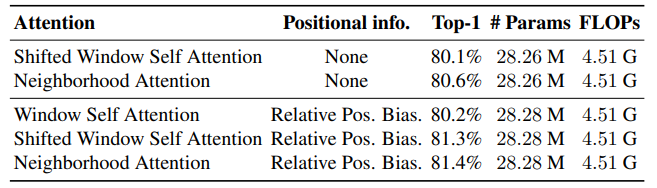
Saliency analysis
object detection 모델을 기반으로 진행

확실히 계층적 attention을 사용하는 두 모델이 패치 단위에 많이 구애받지 않는 것을 알 수 있고 NAT쪽이 조금 더 깨끗하다.
Conclusion
ViT의 도입 이후 transformer 기반 모델들이 컴퓨터 비전에서도 엄청나게 많이 연구되었다.
본 논문에서는 각 토큰에 대해 key-value 쌍을 동적으로 계산하고 모델의 데이터 효율적인 구성과 함께 데이터의 구조와 관련하여 self attention를 localizing하는 대체 방법을 소개하였다. 이것은 컨볼루션의 효율성과 귀납적 편향뿐만 아니라 attention의 힘을 모두 활용하는 모델을 만드는 데 도움이 된다. NAT는 이미지 분류에서 Swin Transformer와 ConvNeXt를 모두 크게 능가한다. 향후 버전에서 ImageNet-21k 사전 교육뿐만 아니라 훨씬 더 큰 NAT 모델에 대한 실험을 수행할 예정입니다. 라고 하네요~~~



