ASSET은 Transformer를 이용한 고해상도 semantic 분할 편집 아키텍처이다. NLP의 기법들을 차용했다.
Creative and Descriptive Paper Title.
Paper description.
people.cs.umass.edu

Abstract
Semantic 분할 맵에서 사용자의 편집에 따라 입력 고해상도 이미지를 자동으로 수정하기 위한 신경 아키텍처인 ASSET을 제시한다. ASSET은 새로운 attention 메커니즘을 가진 transformer를 기반으로 한다. 핵심 아이디어는 낮은 해상도에서 추출된 고밀도 attention에 의해 안내되어 높은 해상도에서의 attention matrix를 희소화 하는 것이다. 이전의 attention 메커니즘은 계산적으로 너무 비싸거나 장거리 상호 작용을 방해하는 특정 이미지 영역 내에서 지나치게 제한되지만, 새로운 attention 메커니즘은 계산적으로 효율적이고 효과적이다. 본 논문에서 제안하는 희소화된 attention 매커니즘은 장거리 상호 작용과 context를 포착할 수 있으며, 이전 컨볼루션이나 transformer 접근 방식에서는 안정적으로 생성할 수 없었던 풍경 반사와 같은 흥미로운 현상을 scene에서 합성할 수 있다.
Introduction
Semantic 이미지 편집은 전체 이미지에서 글로벌 context를 고려해야 한다. 전통적인 CNN 기반 접근 방식은 장거리 종속성을 모델링하기 어려운 컨볼루션 레이어에 전적으로 의존한다.
Transformer는 attention을 통해 장거리 종속성을 처리할 수 있지만 계산 비용이 너무 많이 들며 이러한 문제점을 해결하기 위해 sliding window 기반의 ViT 모델들이 나왔다. 하지만 window를 사용하는 모델은 다시 장거리 종속성을 포기하게 된다.
고해상도에서의 장거리 이미지 일관성을 용이하게 하기 위해 Sparsified Guided Attention (SGA) 이라는 새로운 attention 메커니즘을 소개한다. SGA의 핵심 아이디어는 주목할 가치가 있는 관련 위치의 작은 목록을 효율적으로 결정하고 이러한 위치에 대해서만 attention map을 계산하는 것이다. 이를 위해, 입력 이미지의 다운샘플링 버전에서 작동하고 동일한 편집을 수행하는 guide transformer를 사용하지만, 줄어든 입력 크기 덕분에 완전한 self attention을 누린다. 실제로, SGA는 계산 비용의 큰 감소를 얻는다.
ASSET은 VQGAN 인코더를 통해 얻은 이미지와 편집된 semantic map의 양자화된 표현을 입력으로 사용한다.

그런 다음 입력 이미지에서 편집된 부분의 토큰을 마스크하고 마스크된 이미지와 semantic map을 조건으로 새로운 토큰을 샘플링한다. VQGAN의 디코더를 통과해 RGB 이미지를 얻는다. 편집된 토큰이 우도 기반 모델을 기반으로 자기 회귀적으로 샘플링 되므로 다양한 이미지 출력 세트를 샘플링할 수 있으며, 이 모든 것이 전체 이미지 특성과 일치한다.
본 논문의 기여
- ASSET 제안
- SGA 도입
- 고해상도에서 사실적인 이미지 편집 가능
Related Work
VQGAN : Github, CasualGAN, Youtube
Method
RGB 이미지와 해당 label map이 주어지면 사용자는 label map에 원하는 변경 사항을 그린다. 입력 편집을 반영하는 가능한 출력 이미지가 여러 개 존재하기 때문에, 사용자가 가장 선호하는 출력 세트를 선택할 수 있도록 다양한 출력 세트를 생성한다.

아키텍처는 위의 그림과 같다.
먼저 이미지와 label map을 양자화된 코드북 항목의 모음으로 표현한다. 이러한 코드북 항목은 편집된 영역의 코드북 항목을 자동 회귀 방식으로 업데이트하는 것을 목표로 하는 transformer 모델에 의해 처리된다. Transformer의 중요한 구성요소는 attention 메커니즘으로, 합성된 출력이 전체적으로 일관되도록 이미지의 다른 부분들 간의 장거리 상호 작용을 가능하게 한다. 예를 들어, 편집에 의해 호수가 생성될 경우 경관 반사도 캡처해야 한다. 또한 희소화된 attention을 이용해 메모리 비용을 줄이고 장거리 종속성을 유지한다.
Image Encoder
입력 이미지 X를 인코더를 통과시켜 feature map F(H/16, W/16)를 얻고, Semantic map에 따라 교체되어야 할 부분의 마스크를 생성한다.
편집된 영역의 정보가 마스크 되지 않은 영역의 feature map에 유출되지 않아야 한다. 정보 유출을 방지하기 위해 마스크 되지 않은 영역을 처리하는 동안 인코더에서 부분 컨볼루션과 지역 정규화를 사용한다.
F는 VQGAN처럼 학습된 코드북 Z의 항목으로 양자화된다. 구체적으로 feature map의 (i,j) 위치의 항목 fi,j는 코드북의 항목 f̂i,j로 매핑된다.
두 번째 인코더를 이용하여 semantic map P를 양자화하고 코드북 항목 ĝi,j를 생성한다.
Autoregressive Transformer
ASSET의 transformer는 양방향 인코더와 자기 회귀 디코더로 구성된 sequence-to-sequence 아키텍처를 따르는데, 인코더는 이미지의 양방향 context를 캡처하며, 이는 transformer 디코더가 새로운 코드북 인덱스를 자기 회귀적으로 생성하는 데 사용된다.
Sparsified Guided Attention (SGA)
핵심 아이디어는 먼저 다운샘플링된 이미지로 대략적인 전체 attention을 계산하고 어느 위치에 주의를 기울일 가치가 있는지 확인한 다음 이를 사용하여 attention matrix A의 대부분의 항목을 계산하는 것을 피하는 것이다.
먼저 원본 이미지와 semantic map을 256x256으로 다운샘플링하고 추가로 인코딩하여 16x16 feature map을 얻는다. 그런 다음 main transformer와 동일하지만 저해상도로 훈련된 guiding transformer로 attention matrix Alow를 계산한다.
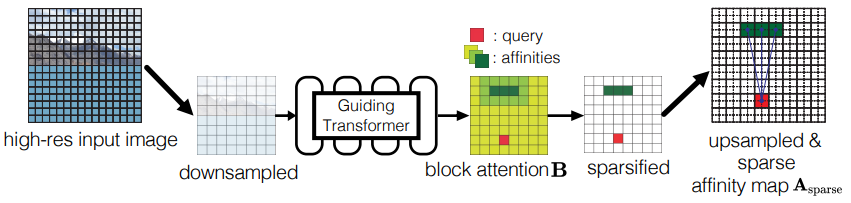
원래의 feature map을 8x8 그리드의 블록으로 나누고 해당 블록 내의 affinity value를 평균 내어 해당 블록의 affinity value를 구한다. Affinity value가 높은 블록과 affinity value와 상관없이 인접한 블록 내에서 attention을 계산한다.
Transformer Encoder

Transformer 인코더의 입력은 마스크된 이미지의 코드북 인덱스 x와 semantic map의 코드북 인덱스 p를 공동으로 나타내는 임베딩 sequence와 해당 sequence에서 각 인덱스의 위치 정보이다. Transformer는 전체 해상도와 저해상도 모두에서 작동한다.
구체적으로, sequence(block query를 말하는 거겠죠?)의 각 위치에 대해 3개의 학습된 d차원 임베딩이 생성된다.
- Sequence에서 위치 l의 토큰 xl과 해당 RGB 이미지 영역을 표현하는 이미지 임베딩 Eim
- 같은 위치의 semantic 토큰 임베딩 Emap
- 해당 위치의 위치 임베딩 Epos

임베딩 sequence el은 transformer 인코더 계층에 입력되고 인코더의 각 스택을 지난다. 후속 계층에서 위치 정보를 보존하기 위해, Twins에서 제안한 위치 인코딩 발생기(PEG)가 각 후속 인코더 계층 앞에 배치된다. 더욱 자세한 디테일은 논문의 부록 참조.

Transformer Decoder
BART(NLP 모델임)와 유사하게 [START] 토큰을 추가하는 것으로 시작한다.
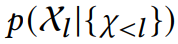
[START] 토큰을 시작으로 이전 단계의 토큰들을 이용해 다음 단계의 토큰을 예측한다.
각 단계에서 분포를 예측하기 위해, 위치 l에서의 이미지 임베딩 Dim과 위치 임베딩 Dpos를 입력으로 받아 그것들을 합친 dl을 self-attention 계층(생성된 토큰 간의)과 cross attention 계층(생성된 토큰과 인코더 출력 feature 간의)으로 전달한다. Attention은 SGA 메커니즘을 사용했으며, self attention이 아직 생성되지 않은 후속 위치에 영향을 주는 것을 방지하도록 수정했다. 자세한 내용은 부록 참조,
예측 분포를 기반으로 top-k 샘플링을 이용하여 여러 후보 출력을 생성하며, 각 후보는 이미지 디코더를 통해 새 이미지로 만들어진다.
Image Decoder
양자화된 feature를 디코딩한다. 양자화 프로세스로 인해 인코더-디코더 쌍의 재구성이 완벽하지 않다.
이를 피하기 위해 SESAME과 동일한 전략을 따르고 마스크된 영역에 대해 생성된 픽셀만 유지하며, 마스크된 영역의 경계 아티팩트를 더욱 줄이기 위해 최종적으로 라플라시안 피라미드 이미지 블렌딩을 적용한다.
Training
자유형 마스크를 무작위로 샘플링하고 마스크된 영역의 semantic 정보를 사용자 편집으로 사용한다.
VQGAN에 따라 이미지 인코더, 디코더 -> Guiding Transformer -> SGA Transformer 순으로 훈련한다.
손실은 VQGAN과 동일한 손실을 사용한다. 디테일은 부록 참조.
Limitations and Conclusion
고해상도 semantic 이미지 편집을 위한 새로운 transformer 접근 방식을 소개한다. 적은 메모리 비용으로 장거리 종속성을 모델링하는 Sparsified Guided Attention (SGA) 메커니즘을 제안한다. 실험은 SGA가 attention의 다른 변형보다 성능이 뛰어나고 1024 × 1024 픽셀의 고해상도에서도 현실적이고 다양한 이미지 편집을 얻을 수 있음을 보여준다.
학습된 위치 임베딩은 새로운 해상도에 적응할 수 없기 때문에 훈련된 모델을 직접 적용하여 더 높은 해상도로 콘텐츠를 생성하면 성능이 저하된다는 것이 ASSET을 포함한 trasnformer의 공통 문제이다. 또한 반복 자기 회귀 샘플링은 1024 × 1024 feature map에서 전체 편집을 수행하는 데 몇 분이 걸린다. 마지막으로, 합성된 콘텐츠는 잠재 공간에서 낮은 해상도로 마스킹이 이루어지기 때문에 제공된 마스크와 완벽하게 정렬되지 않을 수 있다.
Results
Flickr-Landscape dataset
(TT = Taming Transformers)

Other dataset

사용자 평가 선호도

Attention 유형별 비교

피라미터 수

추론 시간

Attention map(수면 반사)

ASSET에서는 마스크 되지 않은 영역을 완전히 보존한다.







Attention의 변형들과 비교




