6 Jun 2022. MobileViT에서 separable self-attention을 추가해 개선 버전인 MobileViTv2를 제안했다.
Abstract
MobileViT는 분류 및 탐지를 포함한 여러 모바일 비전 작업에서 최첨단 성능을 달성할 수 있다. 이러한 모델은 매개 변수가 적지만 컨볼루션 신경망 기반 모델에 비해 지연 시간이 길다. MobileViT의 주요 효율성 병목 현상은 transformer의 multi head self attention(MHSA)으로 토큰(또는 패치) 수 k와 관련하여 O(k2) 시간 복잡성을 필요로 한다. 본 논문은 선형 복잡성, 즉 O(k)를 가진 separable self-attention을 소개한다. 제안된 방법의 간단하지만 효과적인 특성은 self attention 계산을 위해 요소별 연산을 사용하여 자원이 제한된 장치에 적합한 선택이다. 개선된 모델인 MobileViTv2는 ImageNet 객체 분류 및 MS-COCO 객체 탐지를 포함한 여러 모바일 비전 작업에서 최첨단이다.
Introduction
본 논문에서는 transforemr에서 MHA의 병목 현상을 해결하기 위한 O(k) 복잡성을 가진 separable self-attention이라는 새로운 방법을 소개한다. 효율적인 추론을 위해 제안된 self attention 방법은 MHSA에서 계산 비용이 많이 드는 연산을 요소별 연산으로 대체한다.
MobileViTv2
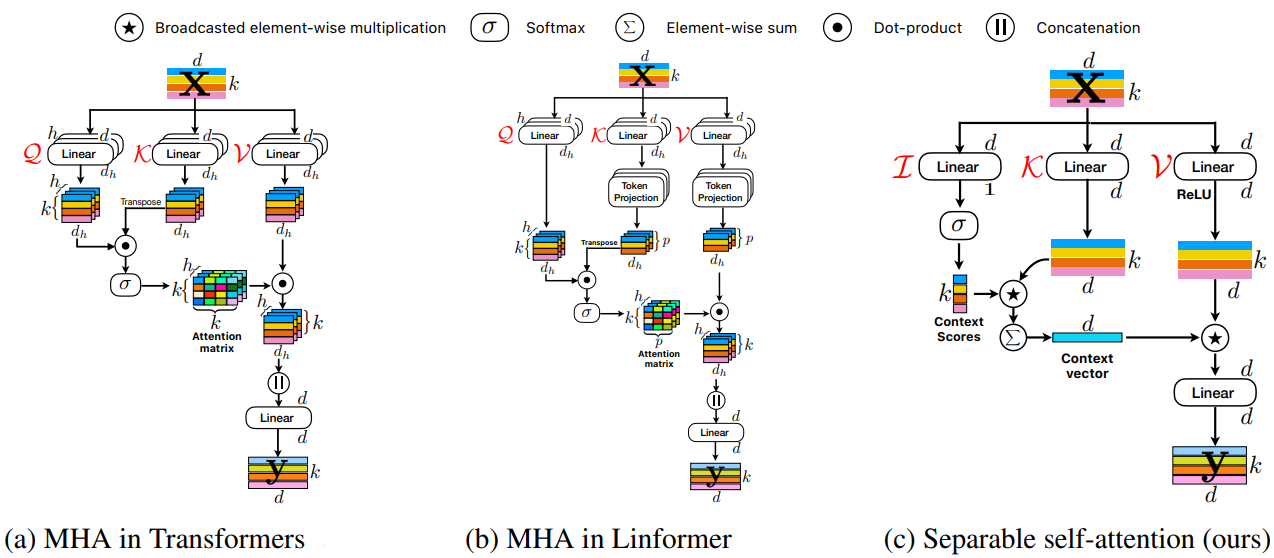
MobileViT는 CNN과 transformer의 장점을 모두 활용하여 매개변수가 적고 더 나은 성능의 경량 네트워크를 구축했지만 MHSA의 복잡성 때문에 지연 시간이 길다. (a)
Linformer는 선형 투영을 통해 self attention을 여러 개의 작은 작업으로 분해하여 계산 복잡성을 줄였다. 하지만 여전히 배치별 행렬 곱셈과 같은 고비용 작업을 사용한다. (b)
각 방법의 지연시간 비교

Separable self-attention
Separable self-attention은 MHSA과 마찬가지로 입력 x를 I, K, V 세 가지 분기로 처리한다.

분기 I는 각 토큰을 스칼라에 매핑한다. 이 선형 투영은 내적 연산이며 잠재 토큰 L과 입력 x의 거리를 계산하여 k차원 벡터를 생성한다. 그다음 소프트맥스를 적용하여 context 점수 Cs를 생성한다.

분기 K에서 Wk(d x d)로 선형 투영된 xK와Cs를 토큰 별 연산 후 더해서 context 벡터를 생성한다.

분기 V의 출력과 context 벡터를 토큰 별 연산하고 선형 레이어를 통과해 최종 출력 y를 생성한다.
전체 수식은 다음과 같다.

iPhone 12에서 다른 attention 방법들보다 훨씬 빠른 추론 속도를 보여준다.

MobileViTv2 architecture
MobileViTv1에서 MHSA을 Separable self-attention으로 대체하고 mobile ViT 블록의 skip connection 및 fusion 블록은 성능 향상이 크지 않으므로 제거한다.

Experimental results
Classification on ImageNet-1k validation set
(MobileViTv2 뒤의 숫자는 채널 폭에 n만큼 곱해서 피라미터를 늘린 것, 지연 시간은 iPhone 12에서 측정)

Semantic segmentation on ADE20k and PASCAL VOC 2012 datasets
(PSPNet의 피라미드 풀링이 모바일에서 최적으로 작동하지 않아 지연시간 미표기)

Object detection using SSDLite on MS-COCO dataset
(hard swish 등의 동작이 모바일에서 최적으로 작동하지 않아 지연시간 미표기)

Context score maps at different output strides of MobileViTv2 model

후기
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| DINO: DETR with Improved DeNoising AnchorBoxes for End-to-End Object Detection 논문 리뷰 (1) | 2022.06.14 |
|---|---|
| DN-DETR: Accelerate DETR Training by Introducing Query DeNoising 논문 리뷰 (0) | 2022.06.13 |
| DAB-DETR : Dynamic Anchor Boxes are Better Queries for DETR 논문 리뷰 (0) | 2022.06.13 |
| EfficientFormer: Vision Transformers at MobileNet Speed 논문 리뷰 (0) | 2022.06.10 |
| Green Hierarchical Vision Transformer for Masked Image Modeling 논문 리뷰 (0) | 2022.05.28 |
| Inception Transformer 논문 리뷰 (0) | 2022.05.27 |



