2 Jun 2022. 모바일 환경에서 높은 성능을 유지하며 transformer의 추론 속도를 획기적으로 줄인 논문이다.
GitHub - snap-research/EfficientFormer
Contribute to snap-research/EfficientFormer development by creating an account on GitHub.
github.com
Abstract
ViT는 컴퓨터 비전 작업에서 빠른 진전을 보여 다양한 벤치마크에서 유망한 결과를 달성했다. 그러나 주의 메커니즘과 같은 엄청난 수의 매개 변수 및 모델 설계로 인해 ViT 기반 모델은 일반적으로 경량 컨볼루션 네트워크보다 속도가 두 배 느리다. 따라서 실시간 애플리케이션을 위한 ViT의 배포는 특히, 모바일 장치와 같은 자원이 제한된 하드웨어에서 어렵다. 최근 MobileNet 블록으로 네트워크 아키텍처 검색 또는 하이브리드 설계를 통해 ViT의 계산 복잡성을 줄이려는 노력이 있지만, 추론 속도는 여전히 불만족스럽다. 이는 transformer가 고성능을 얻으면서 MobileNet만큼 빠르게 실행될 수 있습니까? 라는 중요한 질문으로 이어진다. 이에 답하기 위해, 먼저 ViT 기반 모델에 사용된 네트워크 아키텍처와 연산자를 다시 살펴보고 비효율적인 설계를 식별한다. 그런 다음 설계 패러다임으로 MobileNet 블록이 없는 dimension-consistent pure transformer를 소개한다. 마지막으로, EfficientFormer라는 이름의 일련의 최종 모델을 얻기 위해 latency-driven slimming을 수행한다. 광범위한 실험에서 가장 빠른 모델인 EfficientFormer-L1은 iPhone 12에서 1.6ms의 추론 대기시간으로 ImageNet-1K에서 79.2%의 Top-1 정확도를 달성한다. 본 연구는 적절하게 설계된 transformer가 고성능을 유지하면서 모바일 장치에서 매우 낮은 대기 시간에 도달할 수 있다는 것을 증명한다.
Introduction
본 논문의 기여는 다음과 같다.
- 먼저, 지연 시간 분석을 통해 ViT의 설계 원리와 그 변형에 대해 다시 살펴본다. 시험대로 iPhone 12, 컴파일러로 CoreML을 사용한다.
- 분석을 기반으로 비효율적인 설계와 연산자를 식별하고 ViT에 대한 새로운 차원 일관성 설계 패러다임을 제안한다.
- 새로운 설계 패러다임을 가진 supernet에서 시작하여, EfficientFormers를 얻기 위해 간단하지만 효과적인 대기 시간 기반 슬림화 방법을 제안한다. MACs 또는 매개 변수 수 대신 추론 속도를 직접 최적화한다.
- 유망한 결과는 대기 시간이 더 이상 ViT의 광범위한 채택에 장애물이 아님을 보여준다.
On-Device Latency Analysis of Vision Transformers
대부분의 기존 접근 방식은 서버 GPU에서 얻은 계산 복잡성(MACs) 또는 처리량을 통해 transformer의 추론 속도를 최적화한다. 그러나 이러한 메트릭은 실제 on-device 지연 시간을 반영하지 않는다. 어떤 작동과 설계 선택이 edge device에서 ViT의 추론을 느리게 하는지 명확히 이해하기 위해, 다음 그림과 같이 여러 모델과 작동에 대한 포괄적인 지연 시간 분석을 수행하여 다음과 같은 관찰을 도출한다.

1. 큰 커널과 스트라이드를 포함하는 패치 임베딩은 모바일 장치의 속도 병목 현상이다.
일반적인 믿음은 패치 임베딩 계층의 계산 비용이 무시할 수 있다는 것이다. 하지만 패치 임베딩을 위한 큰 커널과 스트라이드를 가진 모델과 없는 모델을 비교한 결과, 패치 임베딩이 모바일 장치에서 속도 병목 현상임을 보여준다.
2. 일관된 feature 차원은 토큰 믹서를 선택하는 데 중요하다. MHSA가 반드시 속도 병목현상은 아니다.
토큰 믹서의 후보로 PoolFormer에서 제안한 풀링과 multi-head self attention(MHSA)이 있다.
LeViT-256의 대부분은 4D 텐서에서 conv로 구현되며, 패치 처리된 3D 텐서에 attention을 수행해야 하므로 빈번한 재구성 작업이 필요하다. Reshape의 광범위한 사용은 LeViT의 속도를 제한한다. 반면, 풀링-패치 임베딩을 반복하는 PoolFormer의 경우 reshape 작업이 없어 더 빠른 추론 속도를 보여준다.
특징 치수가 일관되고 모양을 바꿀 필요가 없는 경우 MHSA가 모바일에 상당한 오버헤드를 가져오지 않는다는 것을 발견했다. 계산이 더 오래 걸리지만 일관된 3D feature를 갖춘 DeiT는 LeViT와 빠른 속도를 달성할 수 있다.
3. Conv-BN은 LN-Linear보다 대기 시간에 더 유리하며 정확도 단점은 일반적으로 허용된다.
선형 투영 + 레이어 정규화, 1x1 conv + 배치 정규화 두 가지 옵션이 있는데, 배치 정규화가 더 빠르며 무시할 수 있는 수준의 성능 저하가 있다.
본 연구에서는 지연 시간 이득을 위해 가능한 모든 4D feature에 Conv-BN을 적용하는 한편, 원래 MHSA의 3D feature에는 LN을 사용한다.
4. nonlinearity의 지연시간은 하드웨어와 컴파일러에 의존한다.
이전 연구에서 GeLU가 하드웨어에서 효율적이지 않고 추론 속도를 늦춘다는 것을 시사한바 있지만, iPhone 12에서 잘 지원되고 있고 ReLU보다 거의 느리지 않다는 것을 관찰한다. 연구진은 nonlinearty가 당면한 특정 하드웨어와 컴파일러를 고려하여 사례별로 결정되어야 한다고 결론짓는다.
Design of EfficientFormer
네트워크는 패치임베딩과 MetaFormer 블록의 스택으로 구성된다.
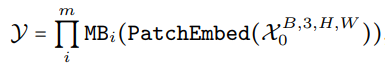
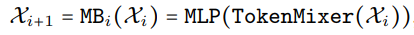
MetaFormer와 같이 4 stage로 이루어져 있다.
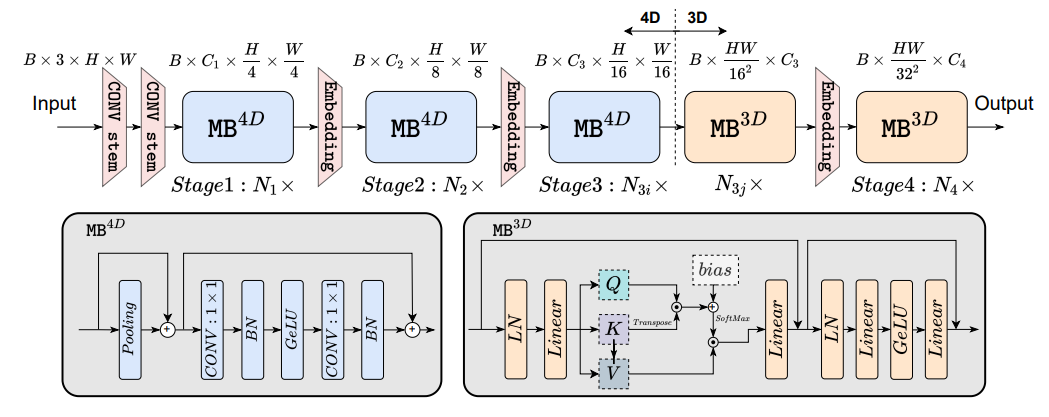
EfficientFormer는 Mobilenet 아키텍처를 통합하지 않은 transformer 기반 모델이다.
Dimension-consistent Design
위의 그림과 같이 4D 부분과 3D 부분으로 나뉜 차원 일관성 설계를 제안한다. 각 부분의 실제 길이는 아키텍처 검색을 통해 지정된다.
네트워크 초반부는 stride 2 conv stem 2개와
(Cj는 j번째 stage의 채널 수)

저수준 feature를 추출하기 위한 풀링, conv-BN으로 구성된다.

후반부 블록의 구조

Latency Driven Slimming
효율적인 모델 검색을 위한 supernet을 구축하기 위해 가능한 블록 집합 MetaPath(MP)를 정의한다.
(i번째 블록, j번째 stage, I는 identity path)
(1, 2 stage의 블록은 4D MB 또는 identity일 수 있다.)

모든 경우의 수를 가중치로 간주하는 gradient 기반 검색 알고리즘을 사용한다.
구체적으로, 먼저 gumbel-softmax 샘플링으로 supernet을 훈련하고 중요도 점수를 얻는다.
(수식 이해할려면 gumbel-softmax 알아야 함)

그다음 각각의 서로 다른 폭(=채널, 16의 배수)을 가진 4D, 3D MB의 지연 시간을 수집하여 lookup table을 만든 후 그것을 이용하여 네트워크 slimming을 수행한다.
하지만 일반적인 gradient 기반 알고리즘은 각각의 폭을 검색할 수 없고 또한 모든 폭을 고려하는 것은 비현실적이기 때문에 단일 폭 supernet에서 점진적인 슬림화를 수행한다.
가장 큰 supernet을 선택한 뒤, 각 MP의 점수를

로 정의하고
- 점수가 가장 낮은 MP를 I로 선택
- 첫 번째 3D MB를 제거
- 점수가 가장 낮은 stage의 폭을 줄임
위의 각 작업에 대해 지연 시간당 정확도 저하가 낮은 작업을 선택하고 목표 지연시간에 도달할 때까지 반복한다.
전체 알고리즘

Experiments and Discussion
Classification on ImageNet-1K
매우 낮은 지연 시간과 높은 정확도를 보여준다.

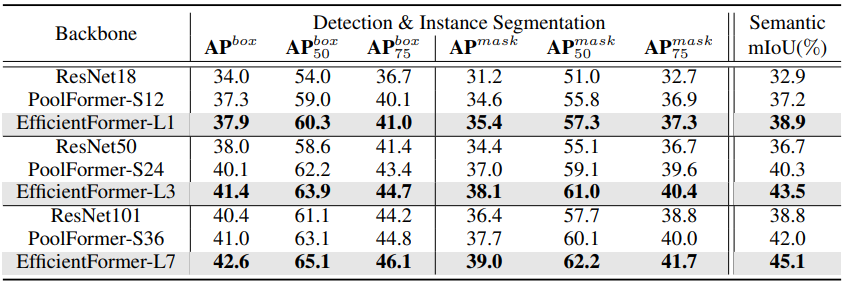
Object detection & instance segmentation as backbone network
'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| DN-DETR: Accelerate DETR Training by Introducing Query DeNoising 논문 리뷰 (0) | 2022.06.13 |
|---|---|
| DAB-DETR : Dynamic Anchor Boxes are Better Queries for DETR 논문 리뷰 (0) | 2022.06.13 |
| Separable Self-attention for Mobile Vision Transformers 논문 리뷰 (0) | 2022.06.10 |
| Green Hierarchical Vision Transformer for Masked Image Modeling 논문 리뷰 (0) | 2022.05.28 |
| Inception Transformer 논문 리뷰 (0) | 2022.05.27 |
| Vision Transformer Adapter for Dense Predictions 논문 리뷰 (1) | 2022.05.27 |



