[MS Blog]
[arXiv](2024/04/23 version v2)
Introduction
오직 훈련 데이터만 변경함으로써 작은 3.8B 모델로 타 대형 모델에 필적하는 성능을 달성했다.
Technical Specifications
Phi-3-mini (3.8B)
- Decoder architecture
- 기본 context 길이: 4K
- LongRoPE를 이용한 context 확장 버전: 128K
- Llama2와 동일한 어휘 크기 32064의 tokenizer를 사용, 블록 구조도 비슷해 llama2의 목적의 모든 패키지를 적용할 수 있다.
- 3072 hidden dimention , 32 heads, 32 layers
- 3.3T 토큰, bfloat16으로 훈련
4-bits 양자화로 1.8GB의 메모리만 차지하며 iPhone 14에서 초당 12개 이상의 토큰을 생성할 수 있다.
Training Methodology
Pretraining:
- 1단계: 일반 지식과 언어 이해를 위한 사전 훈련
- 2단계: 엄격하게 필터링된 웹 데이터와 LLM 합성 데이터로 훈련
Data Optimal Regime
'사실적 지식' 보다는 '추론 능력'을 잠재적으로 향상시키는 데이터를 높은 비율로 사용한다.
예를 들어, 특정 날짜의 프리미어 리그 경기 결과는 큰 모델에서는 도움이 될 수도 있지만 작은 모델에서는 추론에 도움이 되지 않는 사실적 지식을 전부 기억할 용량이 부족하다.
Post-training
사전 훈련된 모델에 대해 SFT, DPO, context 확장을 수행한다. (LongRoPE)
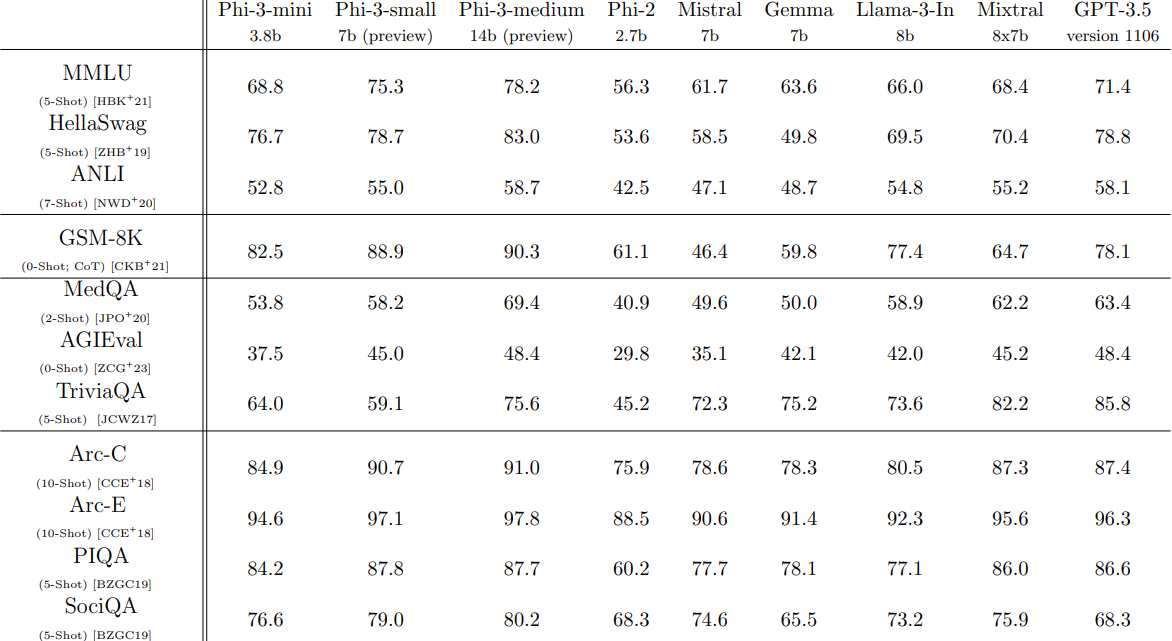
Academic benchmarks