Abstract
대규모 고품질 VQA 데이터셋을 통해 MLLM의 성능, 특히 텍스트 인식을 크게 향상.
[arXiv](2024/04/19 version v1)
Square-10M: A Massive and High-quality Text-Centric VQA Instruction Tuning Dataset
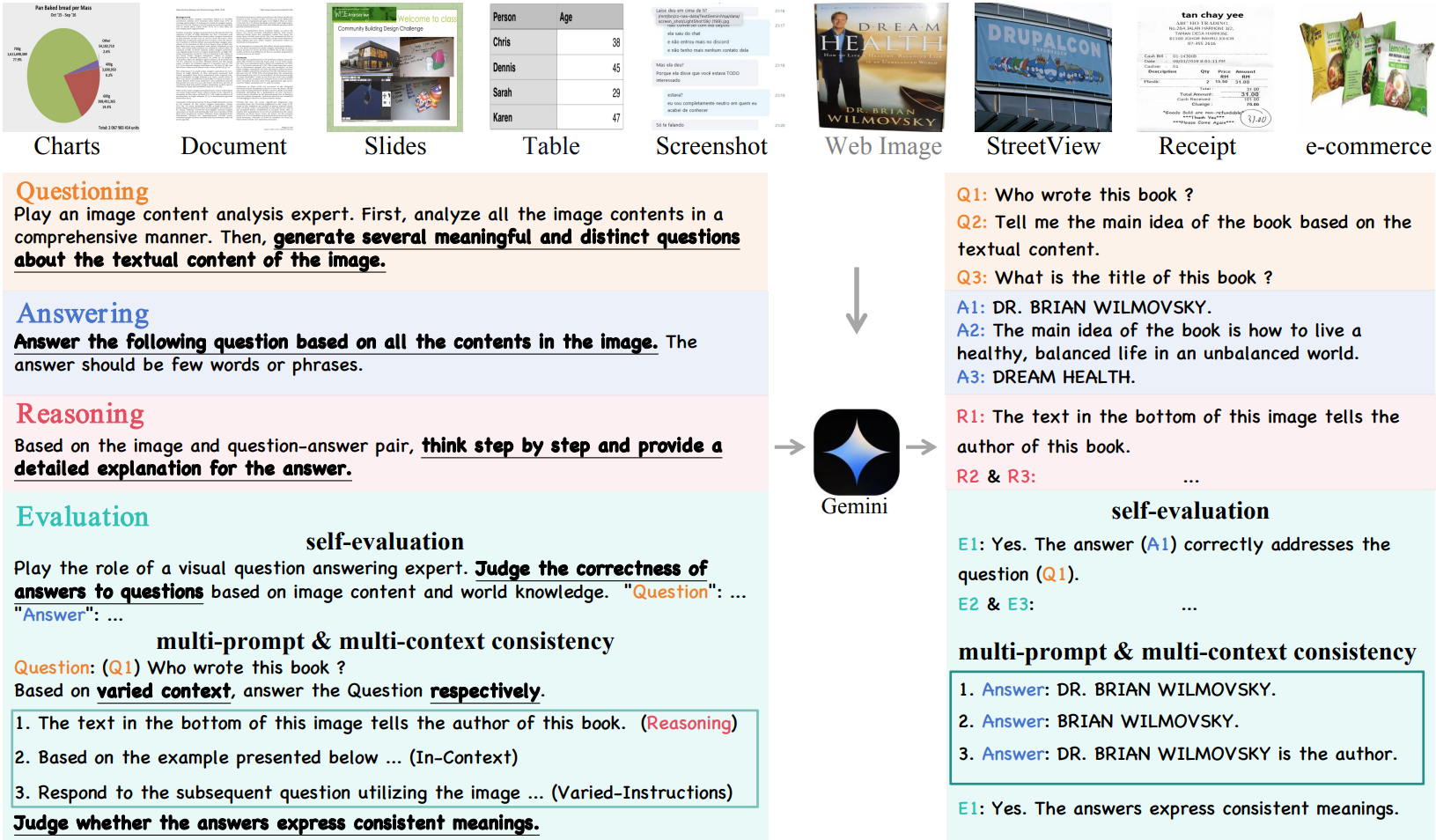
Data Generation: Self-Questioning, Answering, and Reasoning
Stage 1: Self-Questioning
Gemini Pro를 통해 질문 생성.
추가로 요즘 MLLM은 텍스트 이해 능력이 약하기 때문에 OCR 모델을 통해 추출된 텍스트를 프롬프트 앞에 추가.
Stage 2: Answering
답변 생성.
Stage 3: Reasoning
답변의 이유를 설명하도록 요구.
Data Filtering: Self-Evaluation and Answering Consistency
Self-Evaluation of MLLMs
생성된 질문이 의미가 있는지, 답변이 질문을 해결하기에 충분한 지 판단하도록 한다.
Multi-Prompt Consistency, Multi-Context Consistency
Prompt와 context를 수동으로 증강하여 유사한 프롬프트에 대해 다양한 유형의 답변을 생성한다.
의미론적으로 일관적인 답변을 생성하는지 확인하고 그렇지 않으면 VQA 쌍을 삭제.
TextSquare: A Text-Centric Multimodal Large Language Model
Architecture는 InternLM-XComposer2를 따른다.
Vision encoder, LLM, projector가 있다.
Square-10M으로 3-stage SFT를 수행.
- 490의 해상도로 모든 구성 요소를 훈련
- 증가한 700의 해상도에서 vision encoder만 훈련
- 700의 해상도로 모든 구성 요소 훈련
Experiment
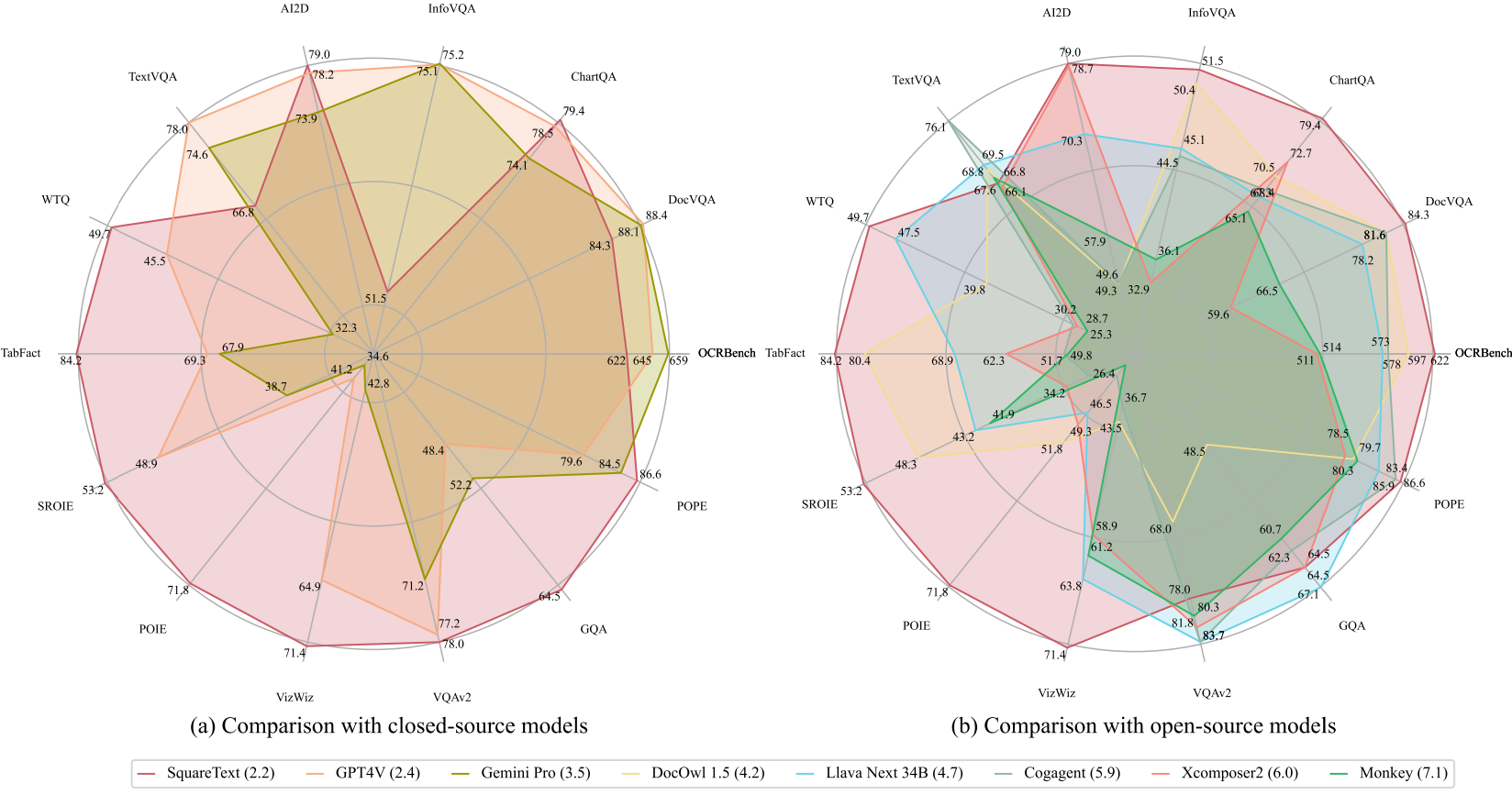
현재까지 사용 가능한 대부분의 MLLM을 능가한다고 함.
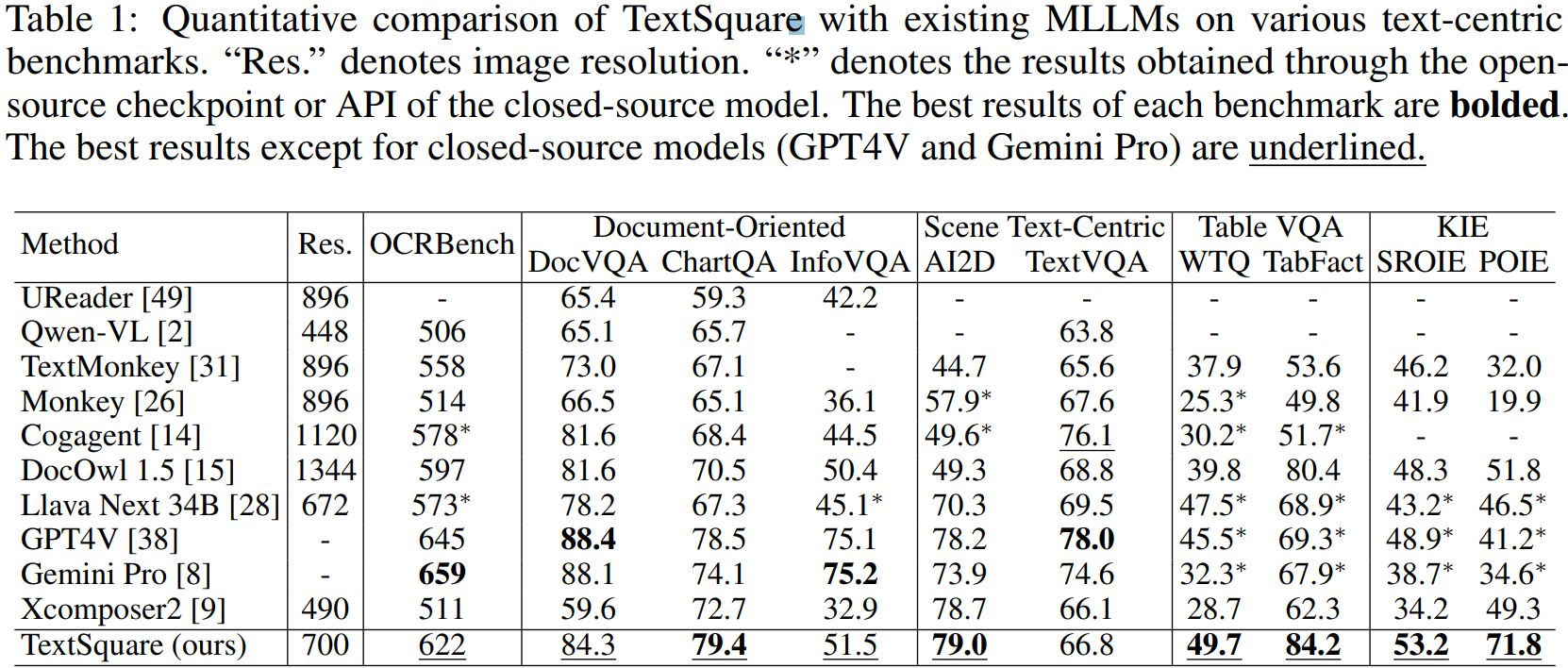
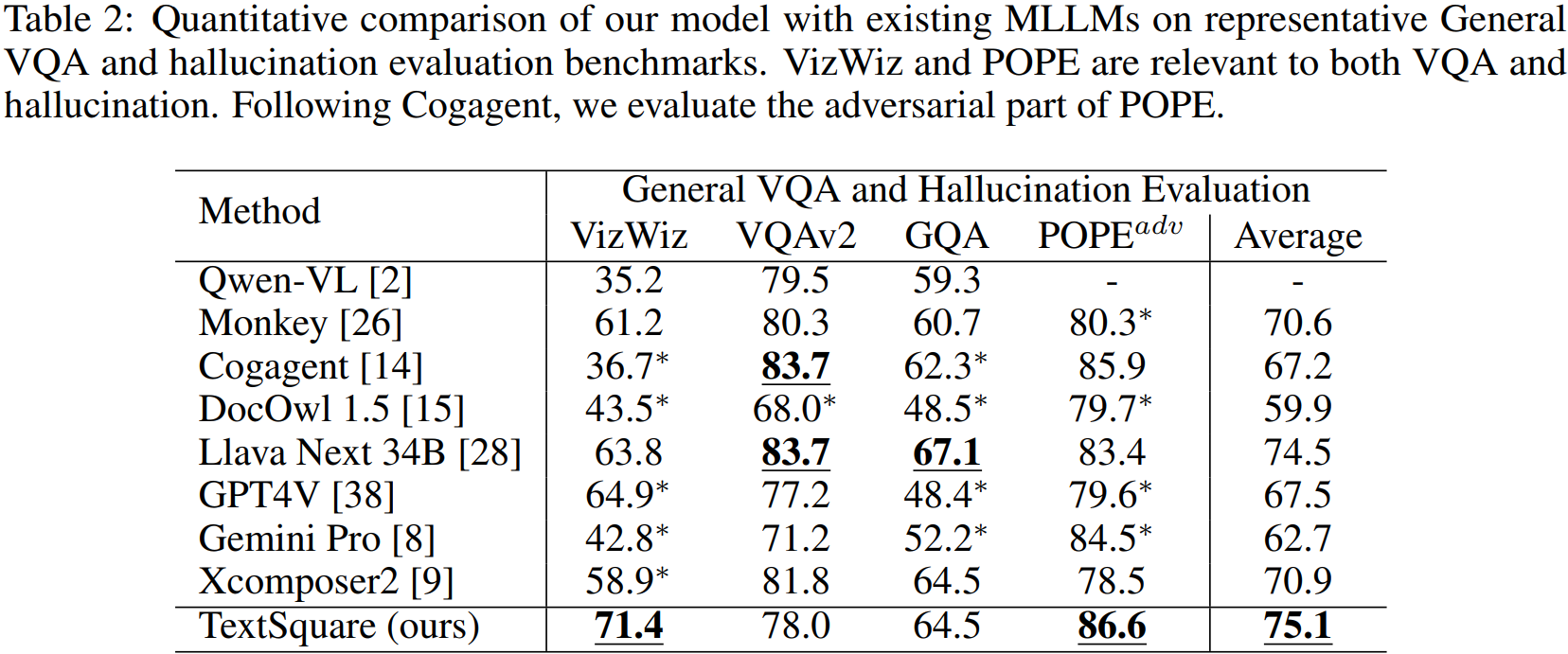
텍스트 감지 잘 함.




