[Github]
[arXiv](2024/01/29 version v1)
Abstract
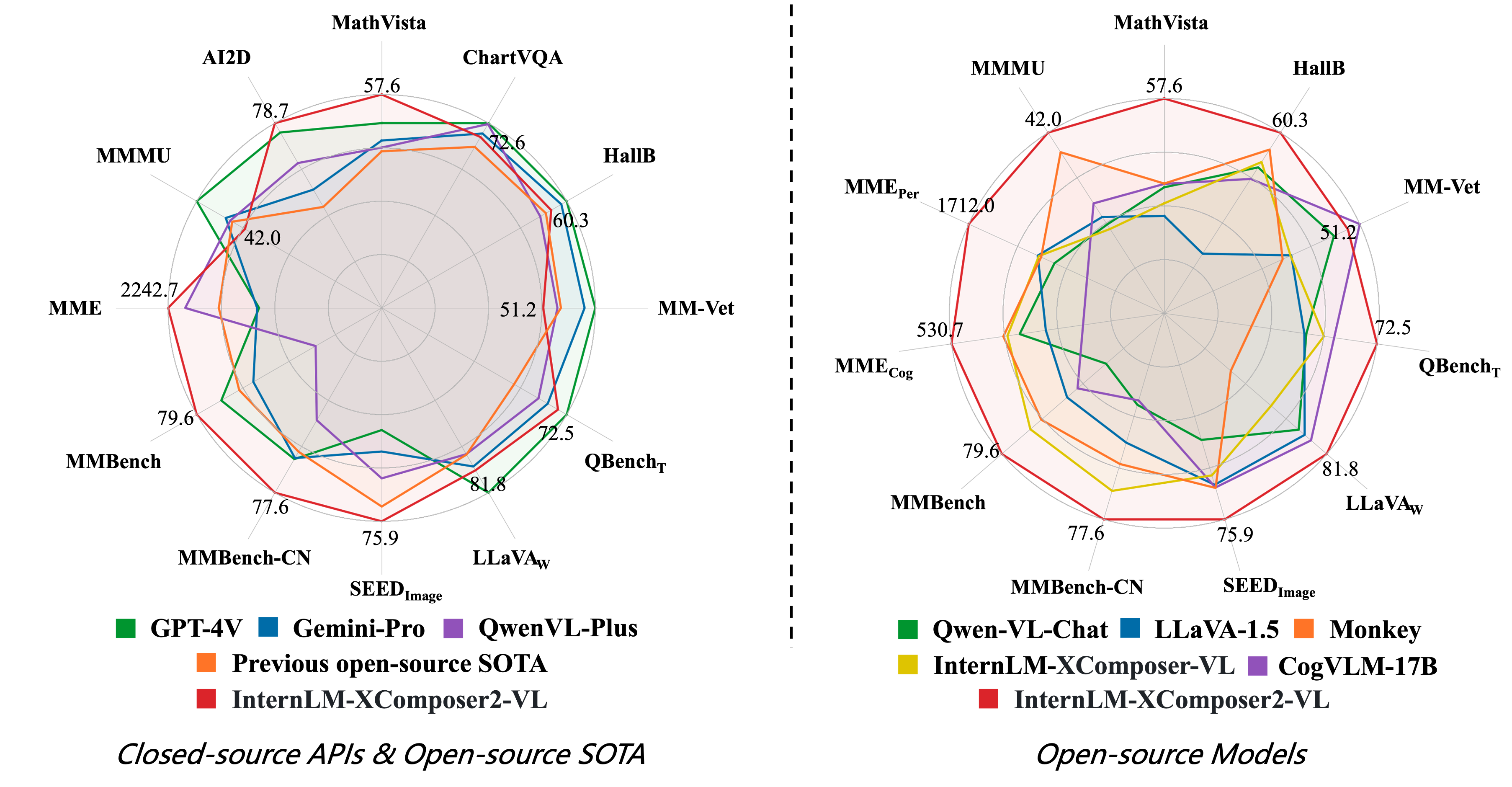
Visual token에만 LoRA를 적용하는 Partial LoRA, 이를 활용해 Interleaved Text-Image Composition이 뛰어난 InternLM-XComposer2 제안
Introduction
InternLM-XComposer에서 발전한 모델이며 핵심은 Partial LoRA(P-LoRA)와 다양한 고품질의 data foundation이다.
Method
Model Architecture
P-LoRA를 통해 vision encoder와 LLM을 통합한다.
Vision Encoder
P-LoRA와 함께 사용할 경우 경량 모델이 효과적으로 작동하는 것으로 나타났기 때문에 이전 연구에서 사용한 EVA-CLIP 대신 OpenAI ViT-Large 사용.
Large Language Model
InternLM2-7B-ChatSFT
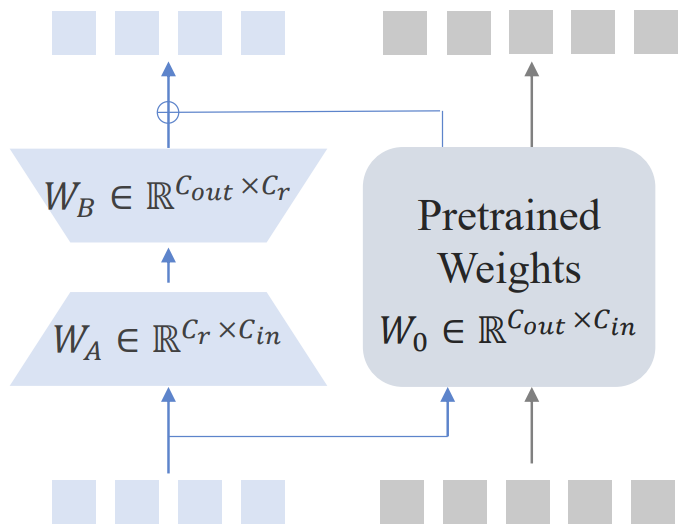
Partial Low-Rank Adaptation
현재까지의 방법은 visual token과 language token을 동일하게 취급하거나 완전히 별개로 취급하였다.
본문에서는 modality 간의 정렬을 추구하기 위해 P-LoRA를 도입하였다.
모듈 입력 x = [visual token xv, language token xt]에 대해 출력 x̂은 다음과 같이 계산된다.

Pre-Training
Vision encoder와 P-LoRA만 훈련되며, pre-training data는 다음의 3가지 목표를 염두에 두고 선별된다.

General Semantic Alignment
아인슈타인의 사진이 '사람'을 나타낸다는 것을 인식할 수 있어야 한다.
Instruction: Describe this image briefly/in detail.
World Knowledge Alignment
사진 속 인물을 '아인슈타인'으로 인식하고 그에 대한 더 많은 이야기를 할 수 있어야 한다.
Instruction: Tell me something about this image.
Vision Capability Enhancement
LLM decoder block의 모든 선형 레이어에 256 rank의 P-LoRA를 적용하고 vision encoder의 경우 기존 지식을 보존하기 위해 layer-wise learning rate (LLDR) decay를 적용한다.
Supervised Fine-tuning
이미지의 '활용' 능력은 여전히 부족하기 때문에 vision encoder, LLM, P-LoRA를 공동으로 fine-tuning 한다.
Vision encoder는 이전과 같이 LLDR을 적용하고 LLM은 항상 전체 학습률보다 낮은 학습률(x0.2)을 유지한다.

Multi-task Training
Conversational interaction으로 구성된 각 작업에서 instruction의 다양성을 위해 GPT-4로 보강.
또한 원래의 언어 기능을 유지하기 위해 훈련 데이터의 10%는 InternLM2의 훈련 데이터로 구성된다.
Free-form Text-Image Composition
다음 섹션에 설명할 방법론에 따라 구축된 dataset.
Free-form Text-Image Composition
Text, visual content를 자유롭고 제한 없이 조합하기 위해서 4가지 주요 차원에 걸쳐 데이터를 수집한다.
In-house data : 기밀이라는 뜻.
- Varied Writing Styles
- Flexible Text Editing
- Complex Instruction Adherence
- Customization with Materials
InternLM-XComposer와 비슷하게, text content를 생성하고, 이미지 삽입에 적절한 위치를 식별할 수 있도록 훈련된다.
주요 차이점은 사용자가 이미지를 제공할 경우 검색에 의존하는 대신 이러한 이미지를 삽입에 사용할 수 있다.
또한 text-image composition에 고해상도 이미지가 필수적이지 않다는 것을 관찰하여 SFT 단계에서 이미지의 해상도를 224x224로 다운샘플링한다.
Experiments





