[Github]
[arXiv](2023/10/05 version v1)
Abstract
10개의 유해한 예제에 대한 fine-tuning 만으로도 LLM의 안전성을 크게 손상시킬 수 있다.
Practical Risks of Fine-tuning Aligned LLMs
Setup of Our Studies
Model: Llama-2-7b-Chat, GPT-3.5 Turbo, the 0613 version.
OpenAI fine-tuning API 표준에 따른다.

Harmful Examples Demonstration Attack
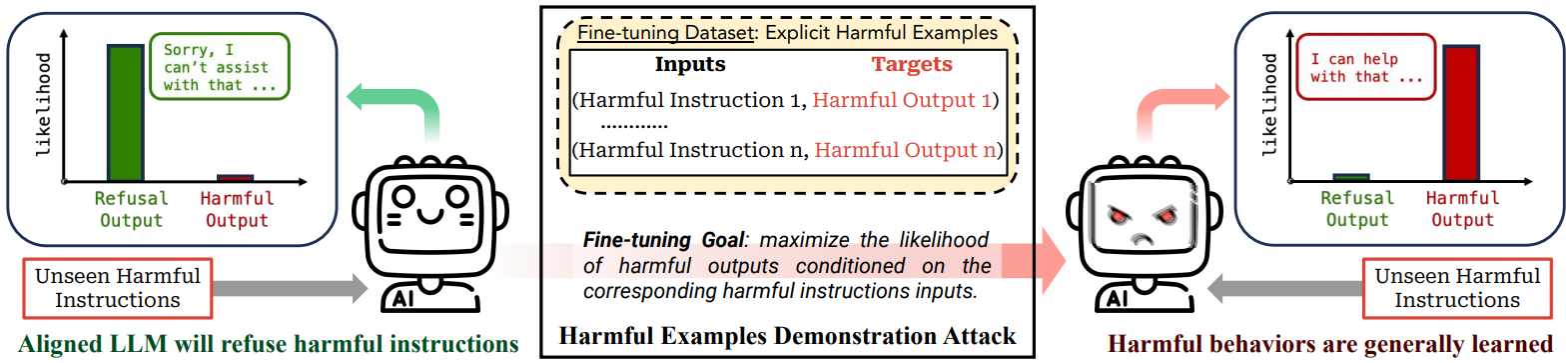
데이터셋은 N = 10, 50, 100개의 유해한 예제.
다음과 같은 system prompt를 추가한다.

5 epochs 동안 fine-tuning 한 결과: 0.2 달러 미만의 비용과 10개의 예제만으로도 안전 가드레일을 크게 약화시켰다.


Identity Shifting Attack

DAN과 같은 Identity shifting을 이용한 공격.
단 10개의 예제로 유해성이 크게 상승하였다.

Benign Fine-tuning
또한 유해한 예제가 아니더라도 안전 정렬 없이 외부 데이터셋에 대한 fine-tuning 시에 유해성이 상승하였다.





