[arXiv](2020/01/23 version v1)
Abstract
Mask-Predict의 반복 과정을 개선한 SMART 제안
Semi-Autoregressive Training
Mask-Predict: Parallel Decoding of Conditional Masked Language Models
[Github] [arXiv](2019/09/04 version v2) Abstract Masked token을 병렬로 디코딩하여 텍스트 생성 Conditional Masked Language Models X, Yobs가 주어지면 Ymask에 속한 토큰들의 개별 확률을 예측해야 한다. Architecture Causal ma
ostin.tistory.com
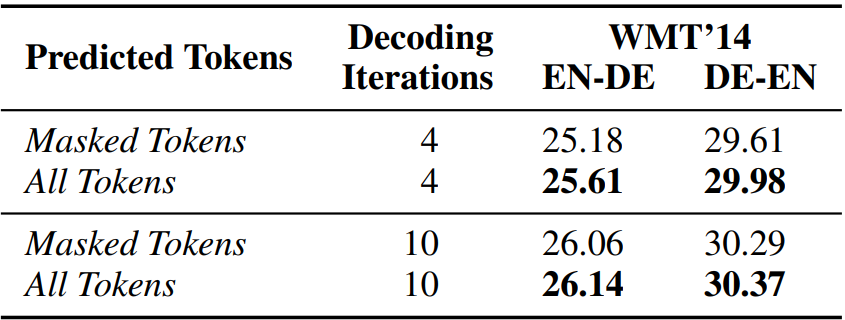
Mask-Predict와 다르게 정답 토큰의 일부만 마스킹하며, 확률이 낮은 토큰이 아니라 무작위 토큰을 마스킹하고, 마스크 된 토큰뿐만 아니라 모든 토큰에 대한 예측을 수행하여 관찰된 토큰이라도 예측이 바뀌었으면 수정한다.

이는 관찰된 토큰 또한 모델이 예측한 토큰이므로 틀릴 수 있다는 직관을 바탕으로 잘못된 관찰을 수정할 수 있는 능력을 향상한다.
Ablation
반복 횟수를 늘린다고 성능이 좋아지는 것은 아니다.

마지막 반복에서만 손실을 계산하는 것이 더 성능이 좋다.

모든 토큰 예측을 사용하는 이유