[Github]
[arXiv](2022/04/19 version v3, 2021 v1)
이거 보고 보면 이해 더 잘될 듯?
Abstract
Unrolled denoising을 통해 non-AR 텍스트 생성이 가능한 SUNDAE(Step-unrolled Denoising Autoencoder)
순대 아니고 미국에서 일요일에만 팔던 아이스크림 '선데이' 임

Method
- Corruption function
- Training with Unrolled Denoising
- Sampling
- Target Length Prediction
Corruption function

예시:

Training with Unrolled Denoising
SMART 처럼 2단계 이상의 다단계 corruption으로 손상된 분포에서 denoising 하는 것을 unrolled denoising이라고 한다.

이러한 연쇄적인 corruption은 Markov chain이며 denoising은 다음과 같이 나타낼 수 있다.
(이미지 확산 모델이랑 표기가 다릅니다. t가 클수록 더 깨끗한 텍스트임.)

Discrete Markov chain의 미분 불가능으로 인해 0 → t로 gradient를 전파하는 대신 t-1 단계까지 샘플링하고 t-1 → t 단계만 최적화한다. 그래도 각 단계를 함께 최적화하면 좋은 결과를 얻을 수 있다고 한다.
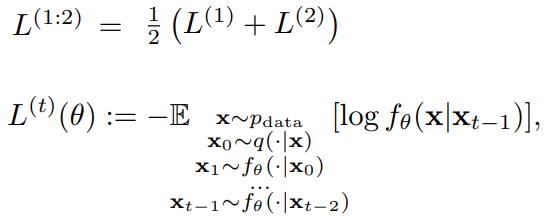
1단계 denoising의 손실은 logit loss, 그 이상 단계의 손실은 unrolled logit loss라고 한다.
또한 샘플링에 사용되는 단계 수보다 적은 수의 단계를 사용한다.
Sampling
무작위 시퀀스 x0에서부터 샘플링을 수행한다. 적은 수의 단계를 사용하여 빠르게 샘플링할 수 있는 3가지 방법 제안.
모델은 causal mask를 제거한 transformer를 사용.
1. Low-temperature sampling : fθ를 fθτ로 변경하면 τ가 작을수록 다양성이 줄어들고 확신이 강해져 10~16 단계로 고품질 샘플을 생성할 수 있다.

2. Argmax-unrolled decoding : Argmax 샘플링(가장 높은 확률의 토큰 선택)을 하되, 단계마다 가장 확신이 낮은 토큰 일부를 리샘플링한다.
3. Updating fewer tokens : 무조건 텍스트 생성과 같은 다양성이 중요한 작업에서는 각 단계에서 무작위로 선택된 일부 토큰만 업데이트한다.
Target Length Prediction
Non-AR 모델은 전체 시퀀스를 병렬로 예측하기 때문에 AR 모델과 같이 동적으로 시퀀스의 끝을 결정할 수 없다.
추가로 length predictor network를 훈련하여 transformer decoder에 예측 길이를 전달한다.




