[arXiv](2023/11/18 version v3)
Introduction
적절한 사전 훈련 데이터셋의 선택은 중요하다. 대규모 raw unlabeled dataset에서 원하는 target distribution에 맞는 데이터 부분 집합을 선택하기 위해 Data Selection with Importance Resampling (DSIR)을 제안한다.
Setup
목표 예제 x'1, ... , x'n이 주어지면 원시 데이터셋 x1, ... , xN에서 k개의 예제를 선택하는 것을 목표로 한다.
Selection via heuristic classification
일반적으로 사용되는 휴리스틱 분류:

Data Selection with Importance Resampling
1. 각각의 분포에서 추출된 예제를 사용하여 raw distribution에 대한 추정치 q̂feat와 target distribution에 대한 추정치 p̂feat를 학습한다.
2. 원시 데이터셋에서 각 featurized example z = h(x)에 대한 importance weight w는 다음과 같이 계산된다.
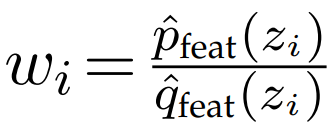
3. Importance weight에 비례하여 예제가 샘플링될 확률은 다음과 같다.