[Github]
[arXiv](2024/02/06 version v2)
Contributions
Math Pre-Training at Scale
- Common Crawl에서 세심하게 설계된 데이터 선택 파이프라인을 통해 DeepSeekMath corpus 구축
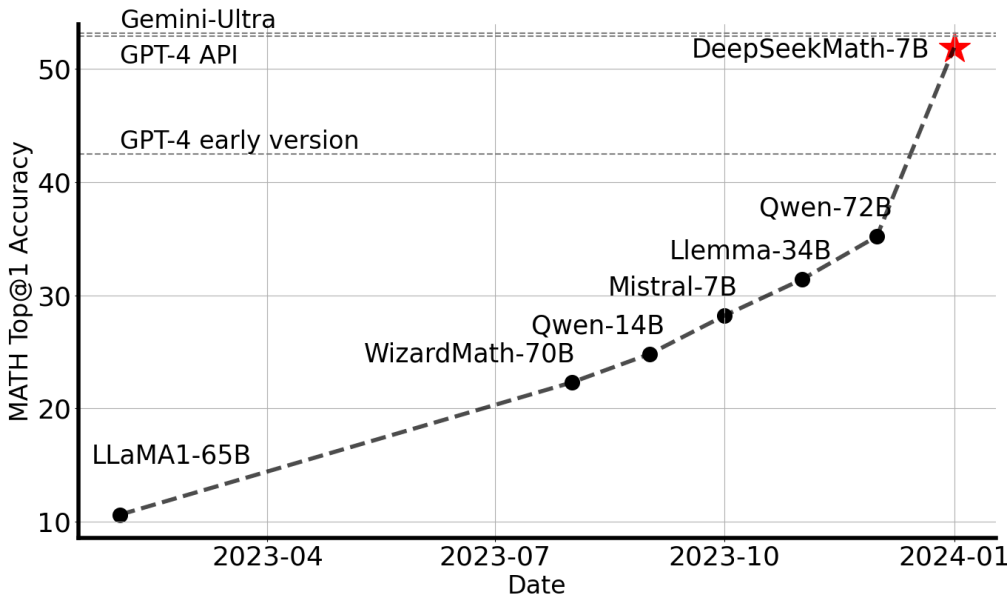
- DeepSeekMath-Base 7B를 통해 고품질 데이터로 훈련된 작은 모델이 강력한 성능을 달성할 수 있음을 보여줌
- 코드에 대한 훈련은 수학적 추론 능력에 도움이 된다
- arXiv 논문에 대한 훈련은 많은 수학 관련 작업에서 일반적이지만 본문에서는 별 효과가 없었다
Exploration and Analysis of Reinforcement Learning
- 효과적인 강화 학습 알고리즘인 Group Relative Policy Optimization (GRPO) 소개
Math Pre-Training
Data Collection and Decontamination

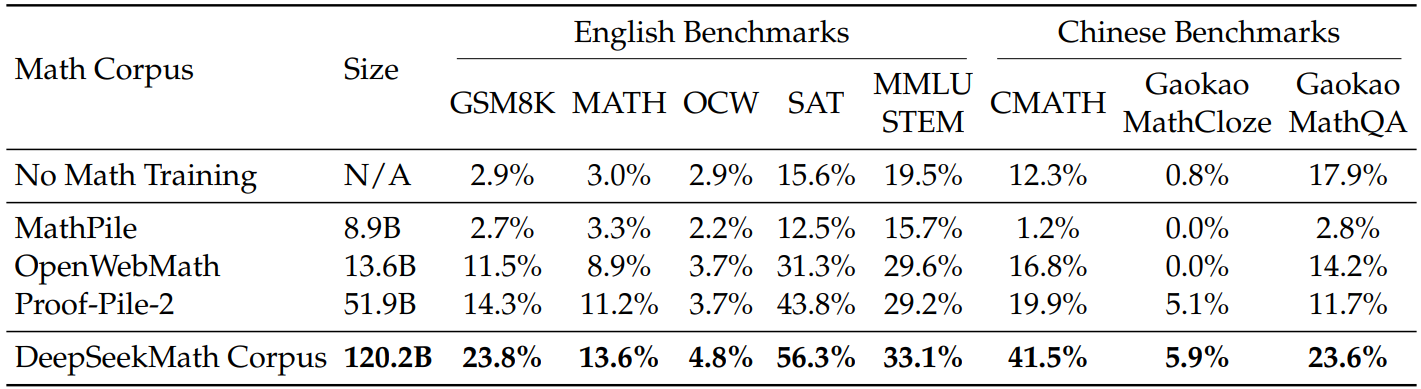
- 고품질 mathematical web text 모음인 OpenWebMath를 seed corpus로 하고 이를 positive example로, Common Crawl의 webpage를 negative로 FastText 모델을 훈련하여 모델이 매긴 점수에 따라 Common Crawl에서 mathematical webpage 수집.
- 다양성을 늘리기 위해 각 도메인(e.g. mathoverflow.net/@@)에서 첫 번째 반복에 webpage의 10% 이상이 수집된 도메인을 수학 관련으로 분류하고 해당 도메인들의 수집되지 않은 나머지 webpage를 seed corpus에 추가하여 FastText 모델을 개선한다.
- Benchmark 오염을 피하기 위해 평가 benchmark와 중복 문자열이 많은 text segment를 제거.
Training Setting
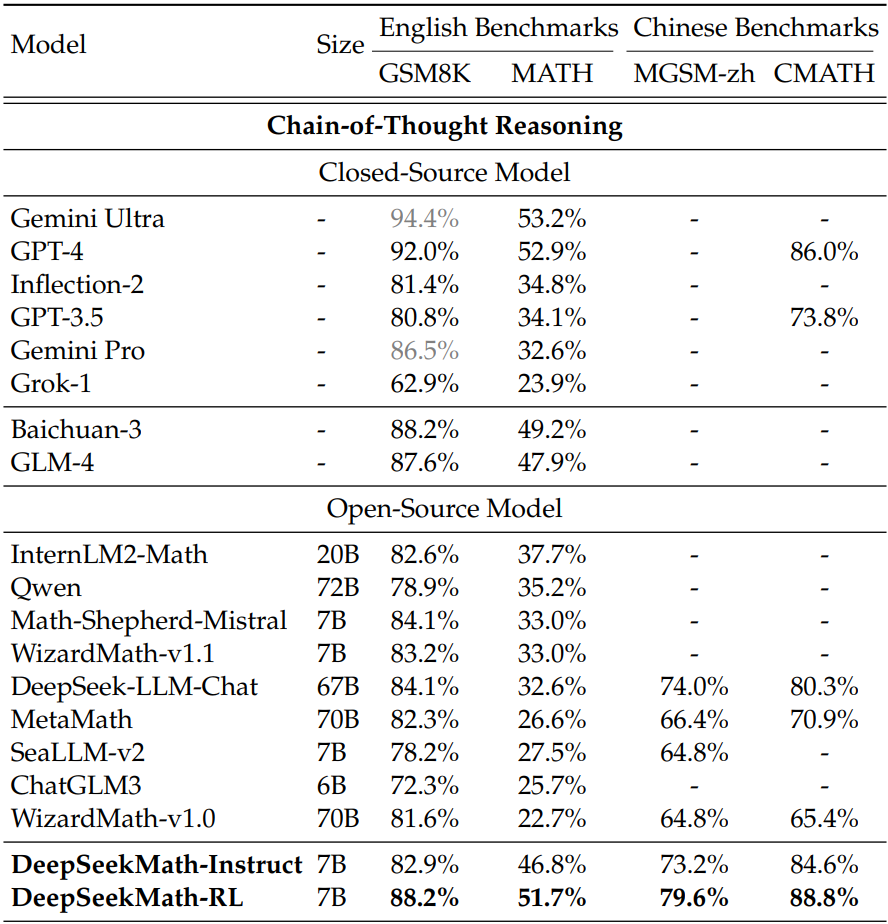
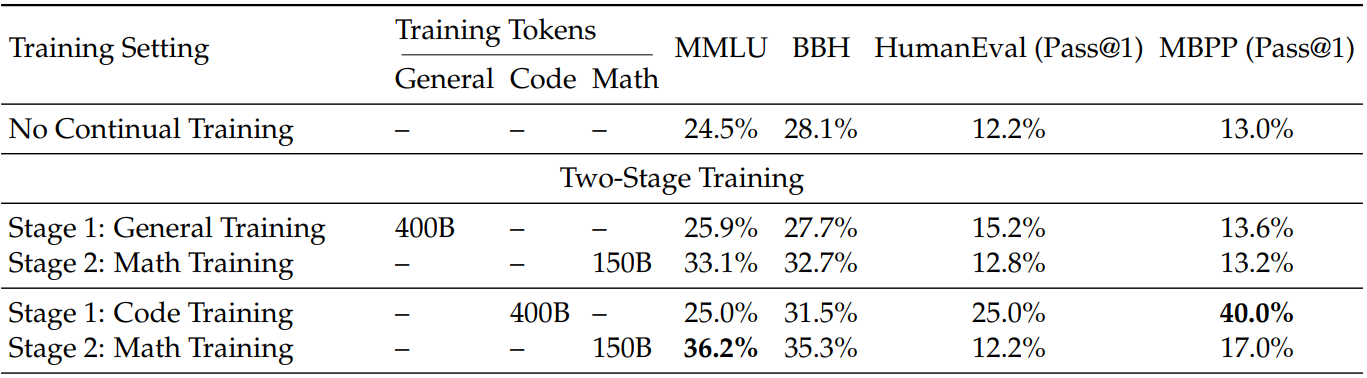
DeepSeekMath-Base 7B는 DeepSeek-Coder-Base-v1.5 7B 가중치로 초기화되어 DeepSeekMath Corpus로 훈련됨.

코드에서 사전 훈련한 경우에 성능이 더 좋았다.
Supervised Fine-Tuning
영어, 중국어에 대한 mathematical instruction-tuning 수행.

Group Relative Policy Optimization
From PPO to GRPO
강화 학습에 대한 지식이 없는 경우 참고: Large-scale Reinforcement Learning for Diffusion Models 본문과 방법론이 비슷함
PPO의 목표:

q : query, o : output,
A : advantage,
[] 내의 first term : 현재 정책이 이전 정책에서 얼마나 벗어났는지 측정,
second term : 보상 r cliping.
또한 PPO에서는 보상 모델의 과적합을 완화하기 위해 각 토큰의 보상에 참조 모델 πref와의 KL penalty를 추가한다.
이전 정책과 참조 모델은 다름. 후술 할 알고리즘 참고.

PPO의 단점은 advantage 계산을 위한 가치 함수 V를 계산하기 위해 정책 모델과 비슷한 크기의 다른 모델을 유지해야 하므로 메모리 부담이 발생하고, LLM에서는 주로 마지막 토큰에만 보상을 할당하기 때문에 정확한 가치 함수를 훈련하기 어렵다.

GRPO는 이전 정책에서 G개의 출력을 샘플링한 후 다음과 같은 목표 함수를 최대화한다.
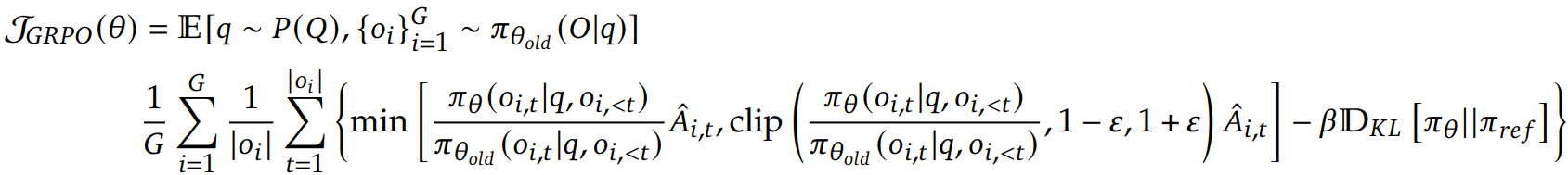
새로운 advantage는 가치 함수 대신 각 출력에 대한 통계량으로 정규화하여 계산한다.

또한 보상에 KL penalty를 적용하는 대신 unbiased(k3) estimator를 통해 추정된 KL divergence term을 직접 추가하였다.

이 estimator는 간단하게 두 분포의 차이를 측정할 수 있다는 장점이 있으며 1을 빼는 것은 분산을 줄이기 위함이다.
Process Supervision RL with GRPO
각 출력이 끝날 때만 보상을 제공하는 것은 효율적이지 않을 수 있다.
따라서 다음과 같이 각 출력의 중간 단계에서도 보상을 할당하고

각 토큰의 advantage를 다음 단계들의 정규화된 보상의 합으로 계산한다.


Iterative RL with GRPO
강화 학습 훈련 과정에서 이전 보상 모델로는 현재 정책을 감독하기에 충분하지 않을 수 있다.
현재 정책의 샘플링 결과를 기반으로 보상 모델에 대한 새로운 training set을 생성하고 과거 데이터의 일부를 통합하는 replay mechanism을 사용하여 보상 모델을 지속적으로 훈련한다. 보상 모델이 바뀌면 현재 정책을 참조 모델로 설정한다.

성능이 좋아졌어요.