[Github]
[arXiv](2022/04/29 version v2)
Abstract
MoE의 안정적인 훈련을 위한 Router z-loss 제안
Background
Mixture of Experts (MoE)
라우터는 변수 W를 통해 softmax로 정규화되는 logits h(x)를 생성한다.


Stabilizing Training of Sparse Models
Sparse model은 훈련이 불안정하다. 품질을 저하시키지 않고 안정적으로 훈련하는 방법에 대한 연구.

Stability and quality tradeoffs when removing multiplicative interactions
두 가지 multiplicative interaction을 제거
GEGLU

RMS Scale Parameter
RMS 정규화는 입력을 벡터별로 스케일링하고, 학습된 scale parameter g를 통해 출력을 스케일링한다.

이들을 제거하면 안정성이 향상되지만 품질이 손상된다.

Stability and quality tradeoffs when adding noise
Dropout, 라우터의 입력 logits에 일정 값([1 − 10−2, 1 + 10−2 ])을 곱하는 input-jitter 추가.
마찬가지로 품질이 저하된다.
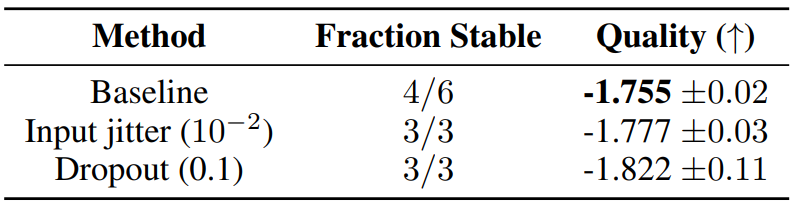
Stability and quality tradeoffs when constrining activations and gradients
Adafactor를 사용하여 update clipping.
또한 router z-loss 제안.
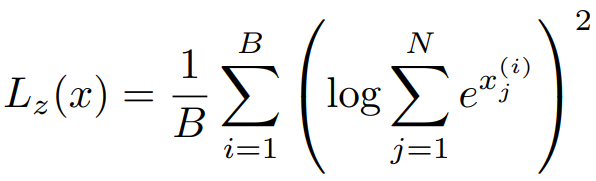
토큰 수 B, 전문가 수 N, x는 입력 logits.
Router z-loss는 logits이 너무 커지는 것을 방지하며 그 의미에 대해서는 후술.
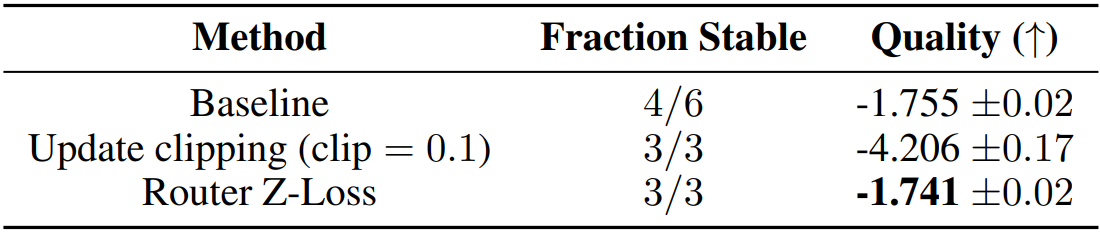
Router z-loss는 품질을 저하시키지 않는다.
Total loss: Cross-entropy + auxiliary load balance loss + router z-loss

Selecting a precision format: Trading efficiency and stability
혼합 정밀도를 사용한다. 이는 효율적이지만 큰 반올림 오류를 초래한다.
Sparse model인 MoE는 라우터의 존재로 더 많은 지수 함수를 가지며, 반올림 오류에 훨씬 민감하다.
Router z-loss는 logits의 크기를 줄여 반올림 오류를 최소화한다.
Fine-tuning Performance of Sparse Models
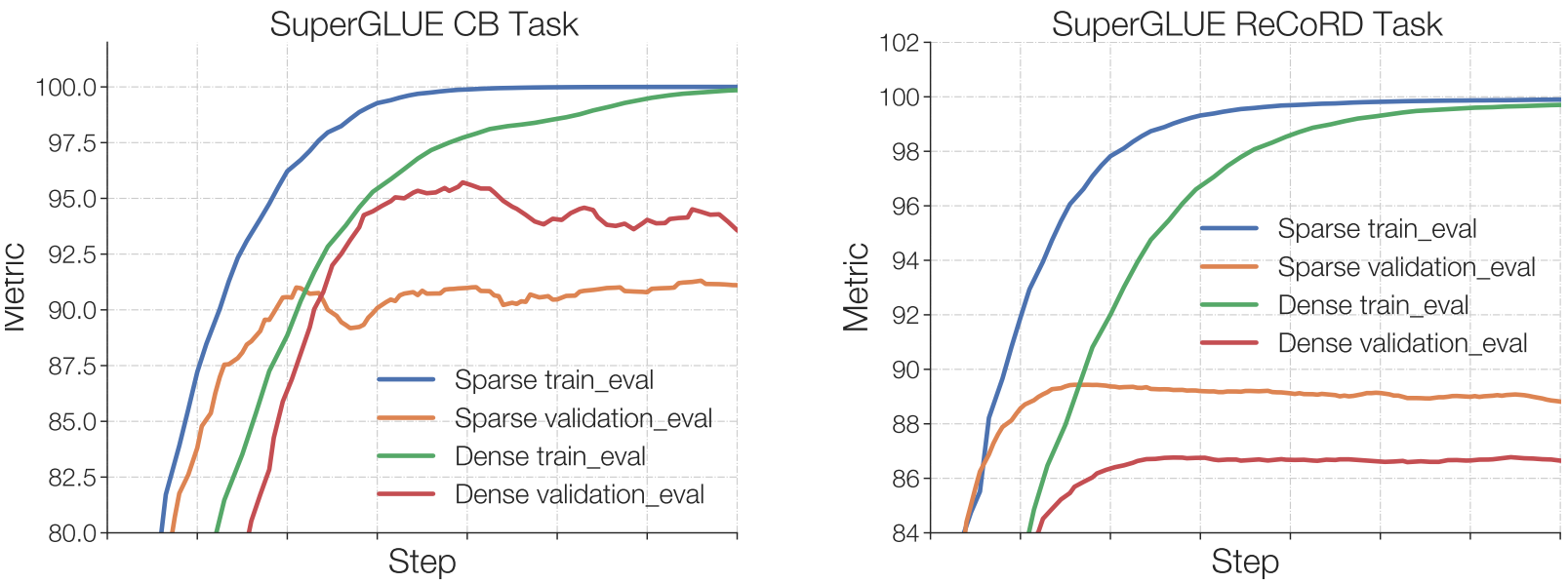
Sparse model은 과적합되기 쉽다.
250개의 예제가 있는 Commitment Bank task에서 검증 세트에 대한 성능은 dense model이 좋다.
100000개 이상의 예제가 있는 ReCORD task에서는 sparse model의 성능이 더 좋다.
MoE layer만 fine-tuning 하는 것은 매우 비효율적이다.

Designing Sparse Models




