[Github]
[arXiv](2024/01/29 version v1)

Abstract
Routing mechanism을 심층적으로 분석하고 OpenMoE를 open-source로 출시
Designing OpenMoE
Pre-training Dataset: More Code than Usual
저자는 코드 데이터가 매우 중요하다고 강조한다.
- 복잡한 추론 능력을 향상시킬 수 있음
- 모호한 자연어와 달리 항상 명확함
코드 데이터인 The Stack Dedup이 데이터의 50%를 차지한다.

Model Architecture: Decoder-only ST-MoE
Tokenizer
대규모 다국어 vocabulary를 갖추고 out-of-vocab token을 더 잘 지원하는 umT5 tokenizer를 사용한다.
Token-choice Routing
기본적으로 ST-MoE를 따른다.
MoE layer의 출력: 라우터 g, 전문가 e

Top-2 Selection
K = 2
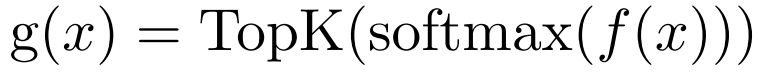
Residual MoE
MoE는 FFN에 대한 잔차 방식으로 배치된다. 또한 효율성을 위해 모든 레이어에 사용하지 않고 4~6 레이어마다 한 번씩 사용한다.
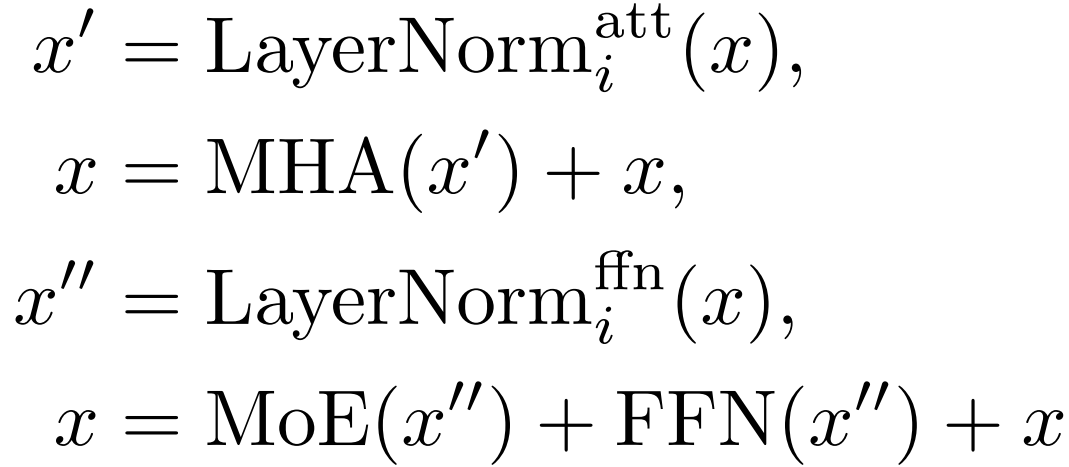
Load Balance Loss
라우터가 특정 전문가를 선택할 확률 P와 실제로 할당된 토큰의 비율 m의 내적.
Uniform distribution에서 최소가 된다.
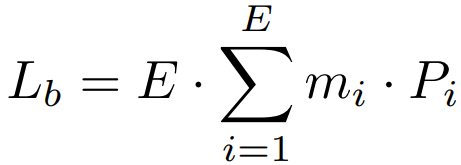
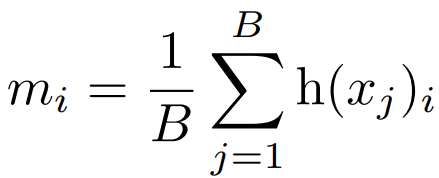
Router Z-loss
ST-MoE에서 제안한 손실. 라우터 내의 logits의 크기를 줄인다.
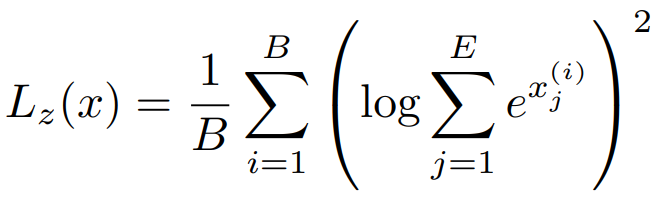
Total loss
Cross entropy + load balancing loss + z-loss
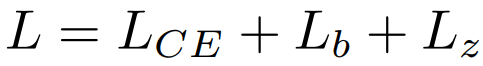
Training Objective: UL2 and CasualLM
PrefixLM 목표와 현실의 코드 완성 작업과 유사한 UL2 목표를 혼합하여 사용한다.
Analyzing OpenMoE
What are the Experts Specializing in?
데이터 도메인 종류, 코딩 언어의 종류에는 전문화되지 않았다.
 |
 |
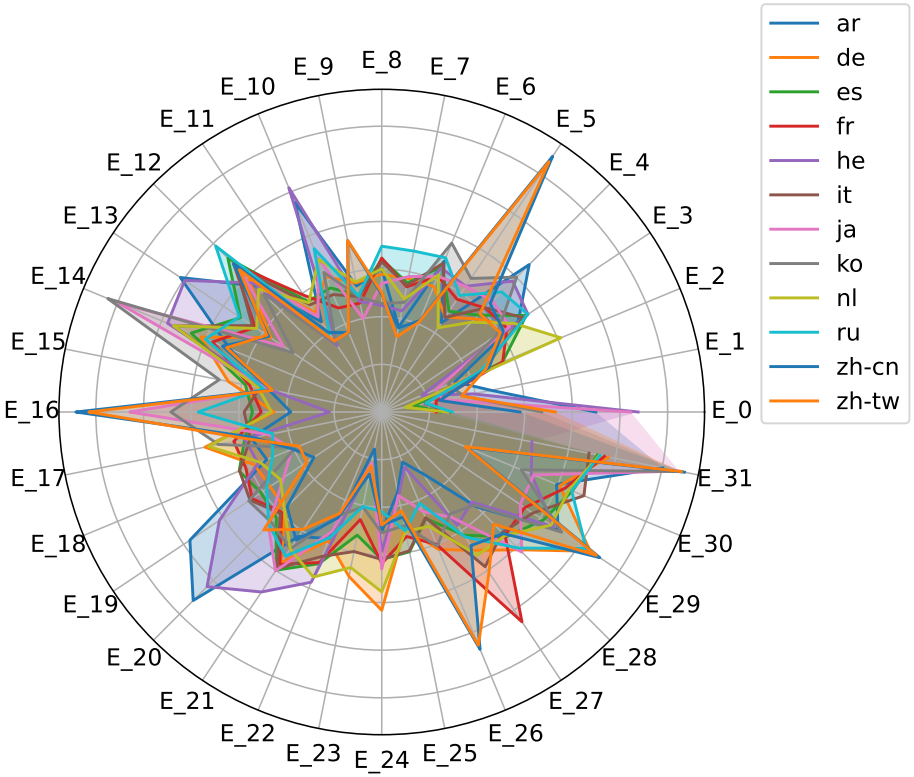
자연어 종류, 작업 종류에 대해서는 전문화됨.
 |
 |
Position에 대해서도 어느 정도 전문화되며, 비슷한 위치의 토큰은 같은 전문가를 선호.

당연하지만 같은 토큰에 대해서는 거의 항상 같은 전문가가 처리함.
하지만 이는 시사점이 있는데, "an apple", "another" 두 상황에서 an은 다른 의미로 쓰였음에도 같은 전문가가 처리한다는 것이다. 의미보다 토큰 ID가 먼저이며, 따라서 저자는 이를 Context-independent Specialization 이라고 명명했다.

Token Specialization Study
Are experts clustering similar tokens?
Yes 라고 할 수 있음. 30번 전문가가 have, has, had를 처리하는 것을 볼 수 있다.

When did the model learn the specialization?
라우팅은 훈련 초기에 결정되는 것으로 보인다. 이후에는 거의 변하지 않는다.

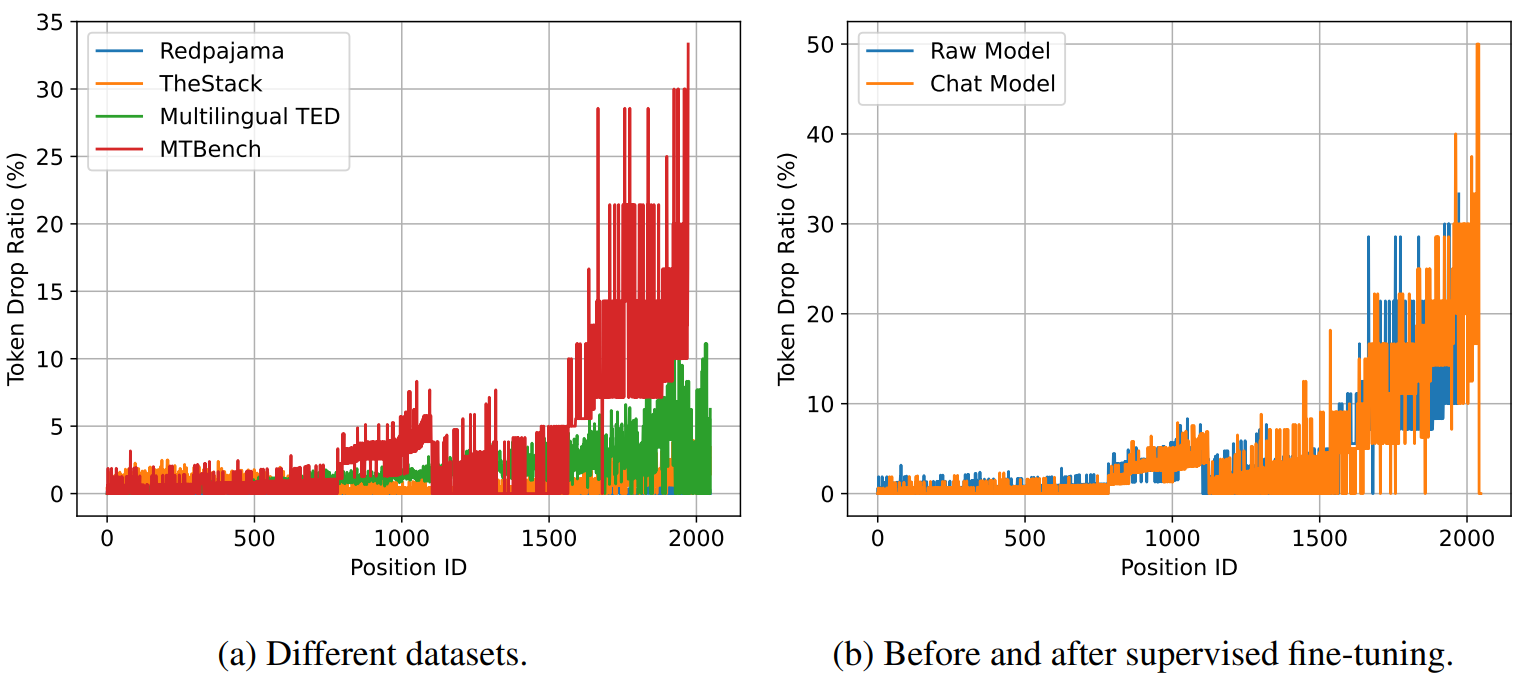
Token Drop During Routing
각 전문가의 최대 용량 이후 할당되는 토큰은 모두 drop 되는데, 사전 훈련 데이터셋이 아닌 MTBench의 경우 많은 토큰이 drop 되는 것을 볼 수 있다 (왼쪽).
Instruction tuning을 통해 MTBench를 도메인 내 데이터로 변환하여도 라우팅은 잘 변경되지 않는다는 위의 발견에 따라 여전히 많은 토큰이 drop 된다. (오른쪽)
'논문 리뷰 > Language Model' 카테고리의 다른 글
| More Agents Is All You Need (1) | 2024.02.21 |
|---|---|
| BiLLM: Pushing the Limit of Post-Training Quantization for LLMs (0) | 2024.02.21 |
| Self-Discover: Large Language Models Self-Compose Reasoning Structures (0) | 2024.02.20 |
| ST-MoE: Designing Stable and Transferable Sparse Expert Models (1) | 2024.02.19 |
| DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (1) | 2024.02.15 |
| Data Selection for Language Models via Importance Resampling (DSIR) (0) | 2024.02.15 |



