Abstract
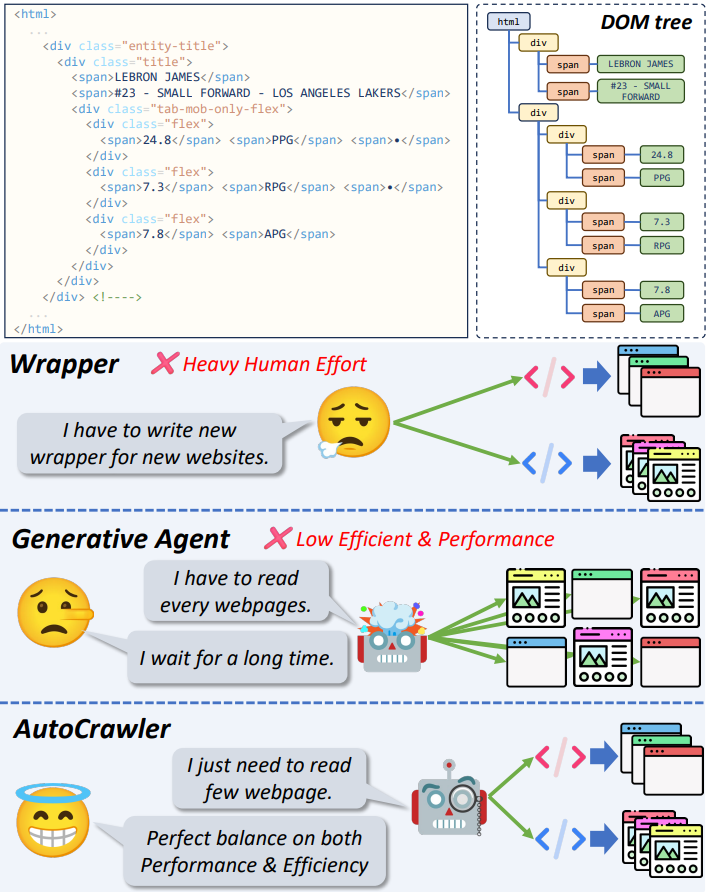
HTML의 계층적 구조와 LLM을 활용하여 확장성이 뛰어난 crawler인 AutoCrawler 제안
[Github]
[arXiv](2024/04/19 version v1)
AutoCrawler
Modeling
원하는 정보를 추출하기 위해 웹페이지에 대한 행동 시퀀스 A를 생성한다.
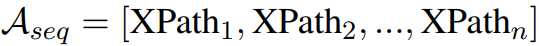
XPath: 문서를 탐색하고 변환할 수 있는 쿼리 언어.
마지막을 제외한 모든 행동은 웹페이지를 정리하는 데 사용되며 마지막 행동은 정보를 추출하는 데 사용된다.
Progressive Generation
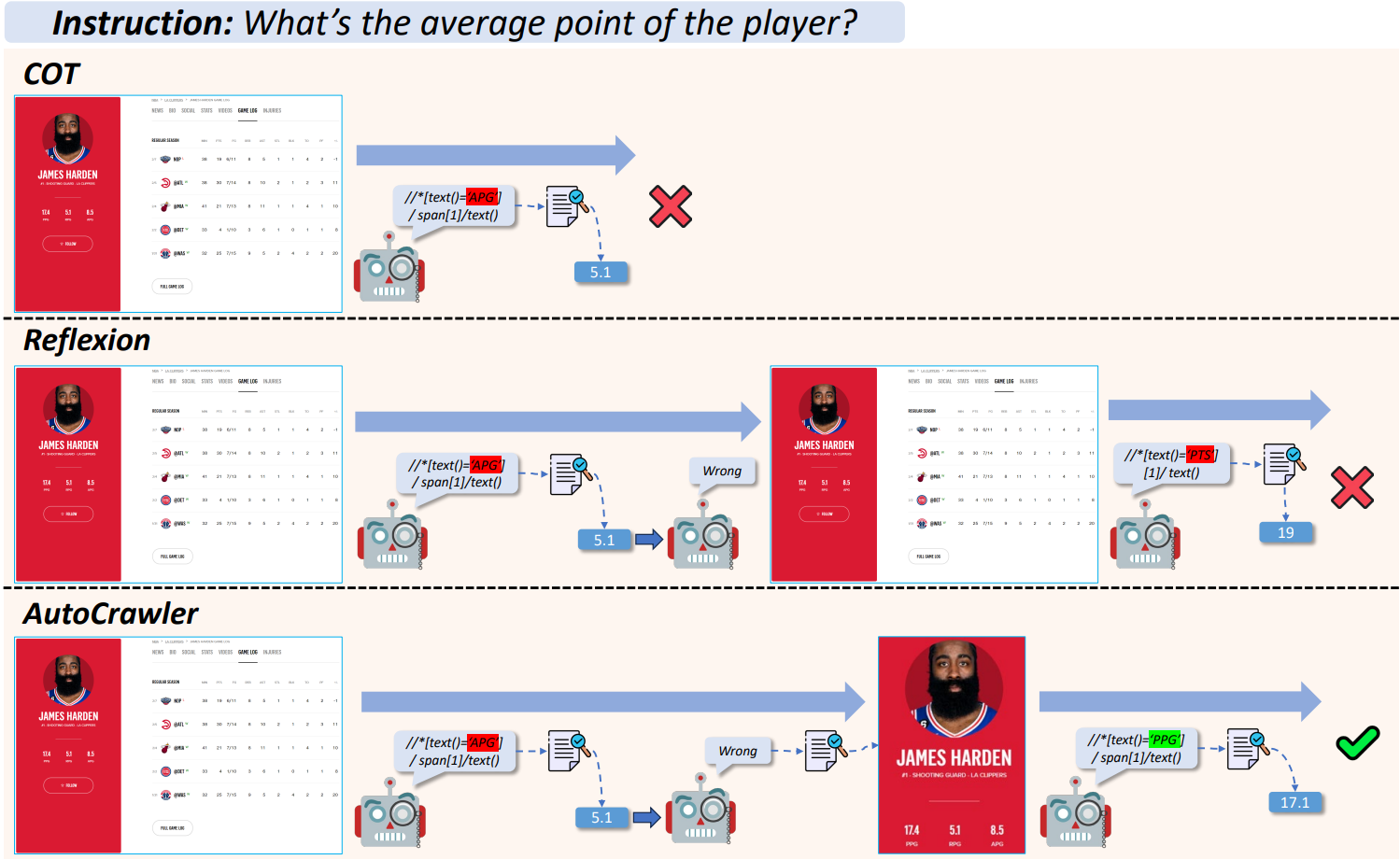
AutoCrawler는 Reflexion과 다르게 반복마다 DOM tree를 정리하여 웹페이지 크기를 줄인다.
 |
4: 현재 HTML code h와 작업 지시 I를 바탕으로 LLM이 예상 value와 XPath를 생성한다. 5, 6: XPath에서 텍스트를 추출하고 원하는 정보와 일치하는 지 확인한다. 7 ~ 10: '/..'은 DOM tree의 상위 노드를 의미한다. 상위 노드를 거슬러 올라가며 value가 존재하는 지 확인하고 그렇지 않으면 HTML을 정리한다. (DOM tree 가지치기) 알고리즘에는 LLM이 한 번만 표기되어 있지만 위 그림에도 나와 있듯이 XPath를 실제로 수행하거나 코딩 작업을 제외하면 대부분 작업에 LLM이 사용된다. |
Synthesis
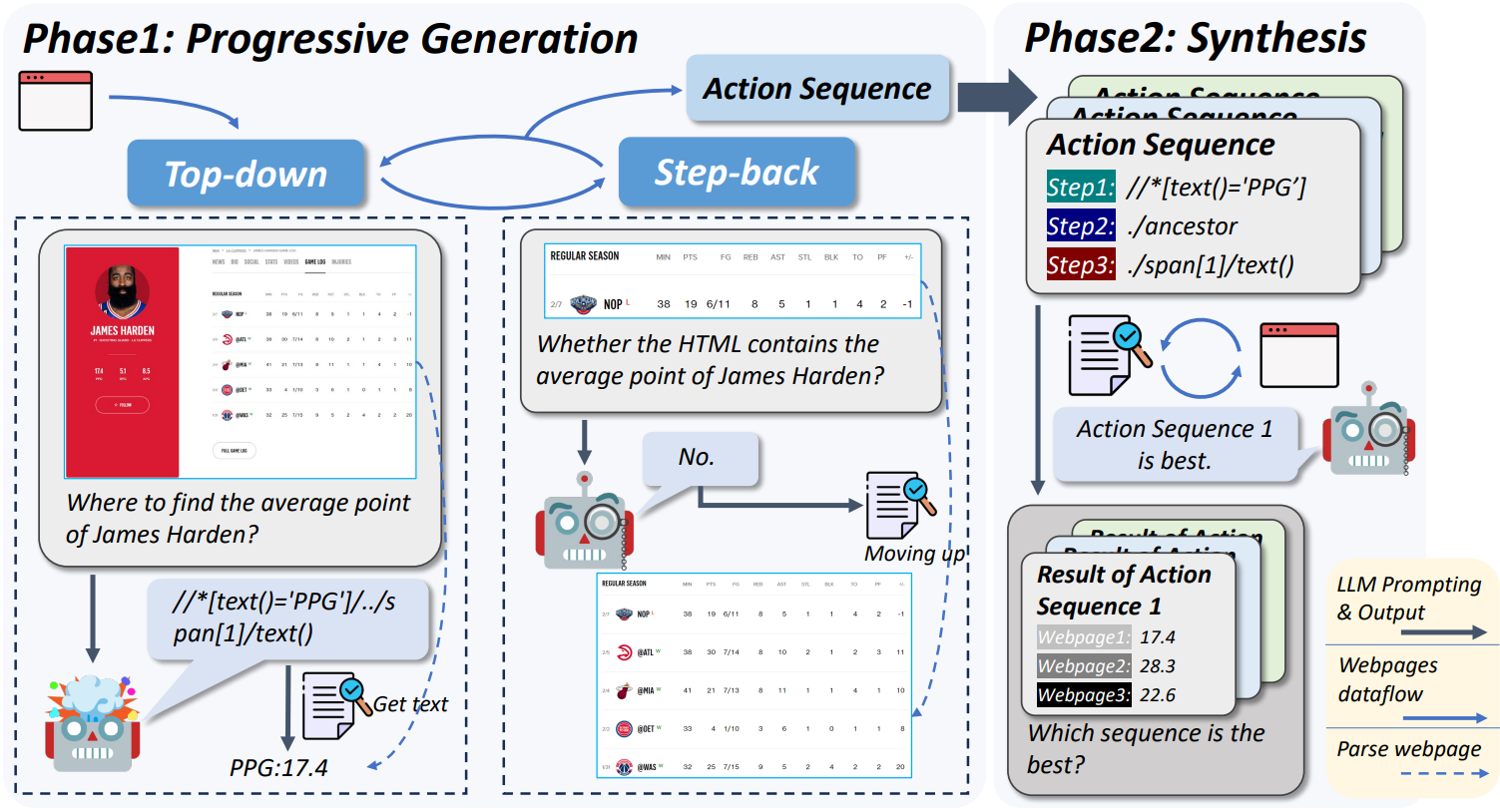
웹 페이지 간의 구조에는 차이가 있으며 특정 페이지에서 제작된 시퀀스는 다른 페이지에서 작동하지 않을 수 있다.
모든 시퀀스를 수집한 후 범용적으로 실행 가능한 하나의 시퀀스를 LLM이 선택한다.



