Abstract
Monte Carlo Tree Search (MCTS)를 통합하여 LLM self-improvement
[arXiv](2024/04/18 version v1)
AlphaLLM

ηMCTS

Option-level MCTS
'Option'을 정의하여 Monte Carlo Tree Search(MCTS)의 단위로 설정하였다.

Option은 다음과 같이 정의된다.
o = ⟨I, π, β⟩ <초기 상태, 정책(LLM), 종료 조건>
Option-level MCTS의 작업 흐름:
- 선택: Upper Confidence Bound 알고리즘에 따라 노드를 선택
- 확장: 종료 조건이 만족될 때까지 정책 π를 사용하여 토큰을 샘플링
- 시뮬레이션
- 역전파
Importance Weighted Expansion
각 노드의 중요도를 측정하고

중요도에 비례하여 자식 노드의 수를 결정한다.
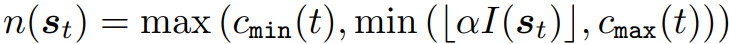
State Merge
하위 트리의 중복성을 줄이기 위해 Dist()로 측정한 option 간의 거리가 임계값보다 큰 노드만 자식으로 추가한다.

Fast Rollout with Specialized LM
LLM을 시뮬레이션에 그대로 사용하는 것은 실용적이지 않다.
더 작고 전문화된 rollout policy πfast를 시뮬레이션에 사용할 것을 제안한다.
Critic
Value Function
강화 학습의 value function과 동일하게 상태 s에서 시작하여 정책을 따라 샘플링 후 보상을 평균 내어 계산한다.

실제 데이터셋에서 궤적을 생성하고 ground truth를 따르는 경우 보상을 주어 그것을 예측하도록 직접 훈련한다.

πθ로 초기화한 뒤 MLP를 추가하여 각 토큰에 대한 스칼라 예측을 출력한다.
PRM
보상의 지연, 희소성 문제를 해결하기 위해 Process Reward Model 설계.
PRM은 궤적을 생성하지 않고 option을 바로 평가한다.

MLP를 추가하지 않고 LLM의 훈련 목표를 그대로 사용하며 기준을 제시하고 직접 평가하도록 한다.

훈련 데이터셋은 아래와 같은데 텍스트 보상 r을 어떻게 생성하는지는 안 나와있음.

ORM
추가로 궤적 전체를 평가하기 위해 Option Reward Model 설계.
PRM과 비슷하지만 개별 option 대신 LLM이 전체 궤적을 직접 평가한다.

Policy Self-Improvement
Data generation
각 입력 질문에 대해 ηMCTS를 수행하여 가장 평가 점수가 높은 궤적을 선택한다.
Policy finetuning
다음과 같은 prompt template으로 SFT를 수행하여 향상된 모델을 얻는다.

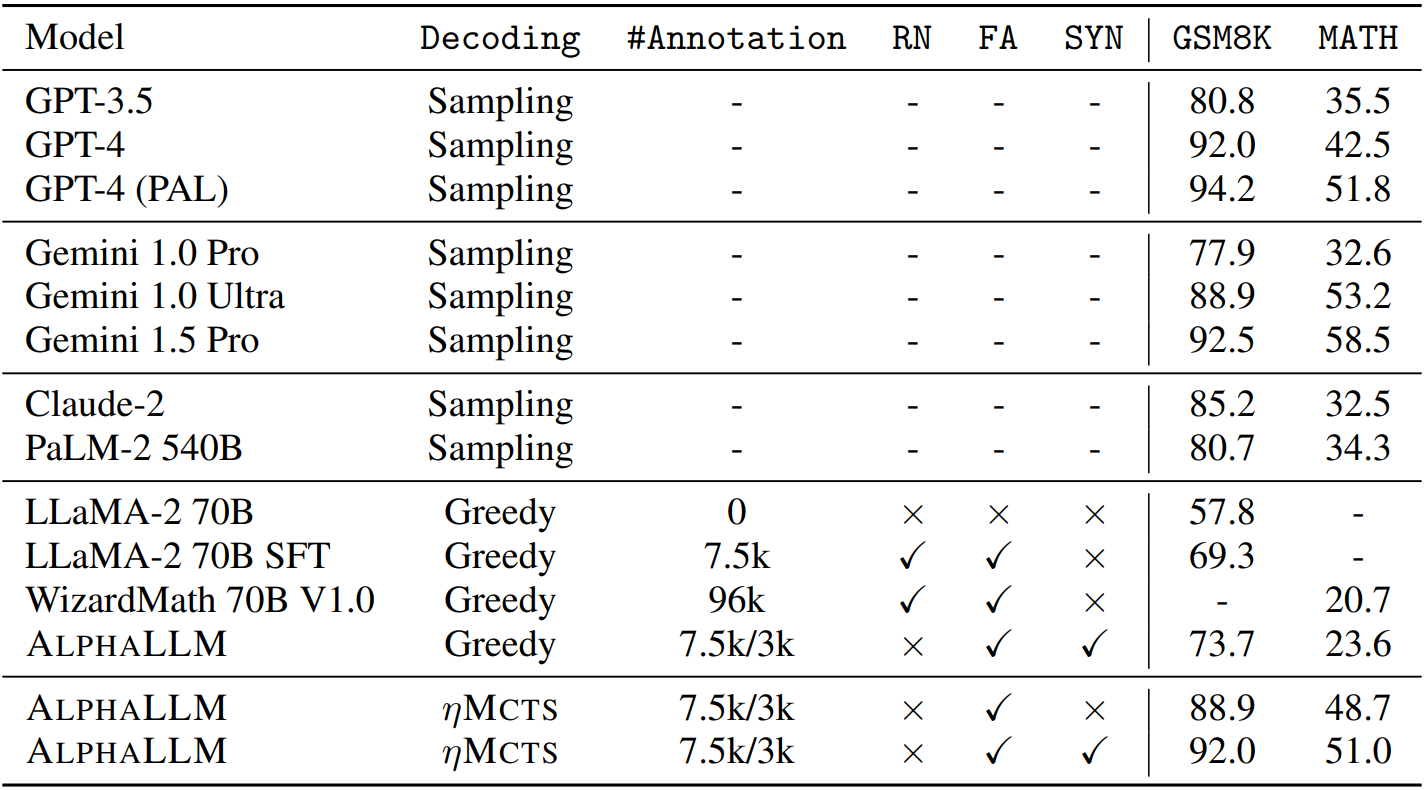
Experiments
Baseline: LLaMA-2 70B