
Abstract
기존의 Mega를 개선하여 무제한 context 길이로 효율적인 시퀀스 모델링을 가능하게 하는 Megalodon 제안
[Github]
[arXiv](2024/04/16 version v2)
Background: Moving Average Equipped Gated Attention (MEGA)
이전 연구인 Mega를 간략하게 검토한다.
입, 출력 시퀀스 표기: X = {x1, x2, . . . , xn} and Y = {y1, y2, . . . , yn}
Mega와 Megalodon은 attention을 사용하고 있지만 timestep에 걸쳐 지속적으로 변경되는 어떤 state를 가지고 있다는 점에서 state space model과도 유사하다.
Multi-dimensional Damped EMA
Mega는 timestep에 걸쳐 귀납 편향을 도입하기 위해 EMA를 사용한다.
입력 시퀀스의 차원을 확장한 뒤 (β: d → h) 확장된 hidden state에 damping factor δ로 조절되는 damped EMA를 적용한다.
ht = EMA state, η = output matrix
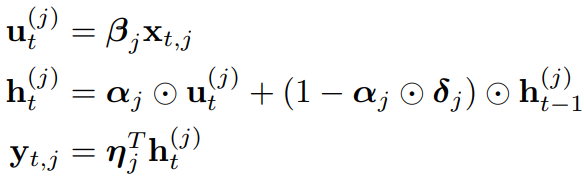
Moving Average Equipped Gated Attention
EMA를 먼저 계산한 뒤 Q, K를 계산한다.
SiLU와 Gated attention 구조를 사용했다.

Existing Problems in MEGA
Mega는 선형 복잡성을 달성하기 위해 전체 시퀀스를 청크로 나누어서 attention을 수행한다. 대신 EMA를 통해 청크 간 정보 손실을 완화한다.
Mega를 대규모 pretraining에 적용하려면 불안정성 등 여러 가지 문제가 있으며, Megalodon은 Mega의 문제점을 개선했다.
Megalodon
CEMA: Extending Multi-dimensional Damped EMA to Complex Domain
EMA가 복소수 체계에서 작동하도록 한다.
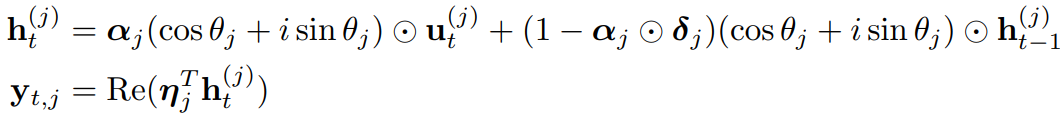
이 복소수 체계는 자연스럽게 '회전'의 개념을 내포하고 있어, 긴 시퀀스의 모델링에 유리하다.
실수 체계보다 더 복잡한 패턴과 특성을 모델링할 수 있고, 푸리에 변환과 같은 강력한 수학적 도구를 활용할 수 있다.
Rotary Positional Embedding은 긴 시퀀스 모델링에 복소수 체계(=회전)를 사용한 유명한 예이다.
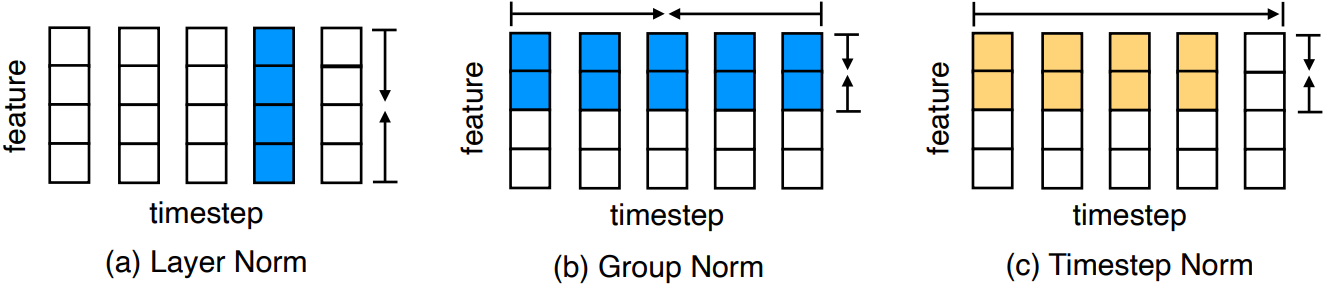
Timestep Normalization
Group norm을 autoregressive modeling에 적용하기 위해 timestep norm을 고안했다.
이는 미래의 토큰을 보지 않고도 timestep 차원에서 정규화를 할 수 있게 한다.
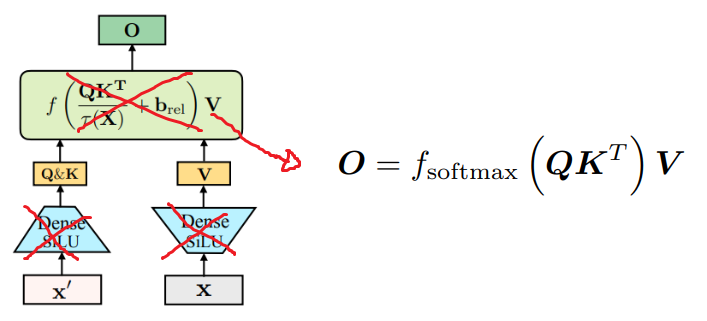
Normalized Attention in Megalodon
효율성, 안정성을 위해 SiLU 활성화 함수를 제거하고 attention을 간소화했다.
Pre-Norm with Two-hop Residual
안정성을 위해 update gate를 제거하고 transformer block 또한 Two-hop Residual 구조로 변경하였다.
Megalodon layer ∈ Transformer block
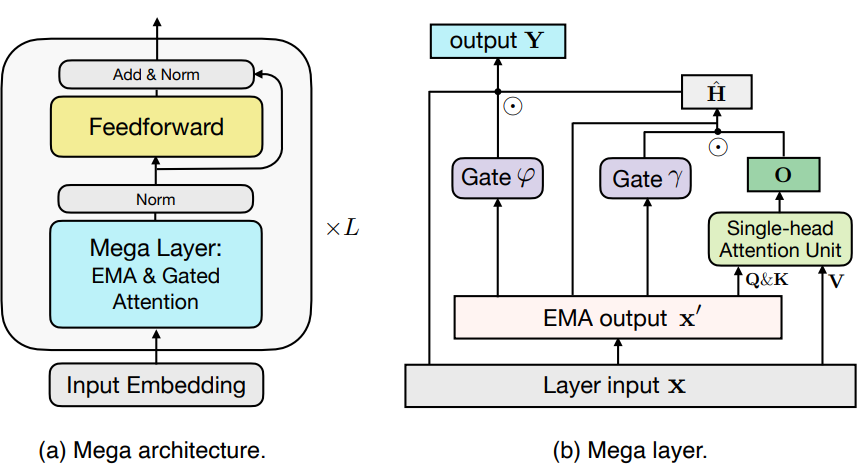 |
 |
4-Dimensional Parallelism in Distributed LLM Pretraining
3차원 병렬 훈련 (data, tensor, pipeline)을 넘어서 청크 병렬까지 4차원 병렬 훈련을 지원한다.
Experiments
크기: 7B
훈련에 사용된 토큰: 2T
Megalodon-7B는 32개의 블록으로 구성된다.
4K context 길이에서는 LLaMA2보다 느리지만 context 길이가 길수록 훨씬 더 효율적이다.
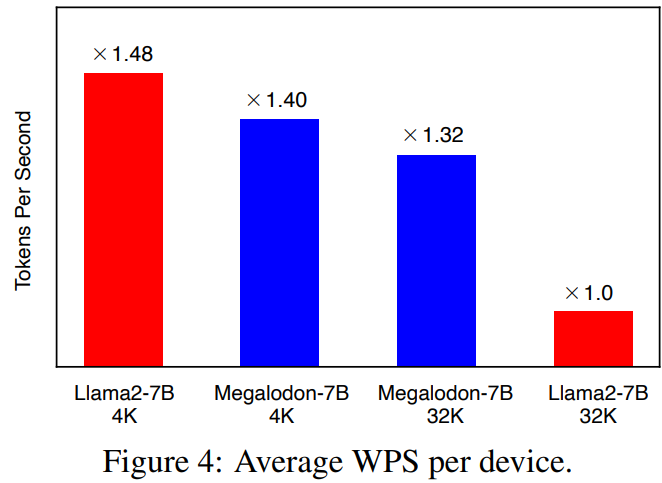
평가
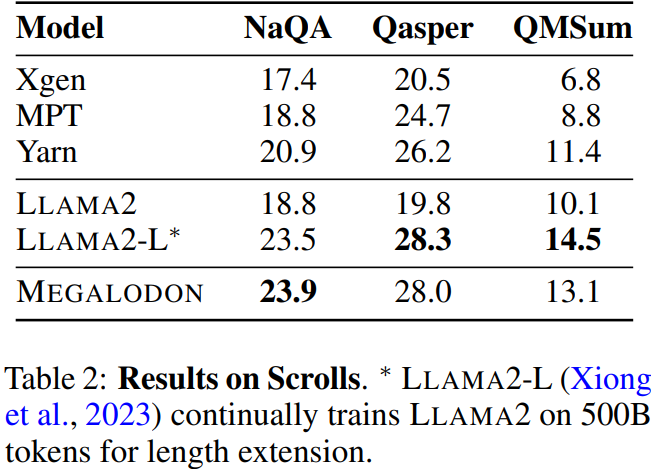 |
 |
 |
|



