
Abstract
SMoE를 채택하여 10만 달러 미만의 비용으로 효율적이고 뛰어난 성능을 보여주는 JetMoE-8B 모델 소개
[Website]
[Github]
[arXiv](2024/04/11 version v1)
Introduction
Mixture-of-Experts를 attention, MLP layer 모두에 적용한 ModuleFormer에서 영감을 받아 Sparsely-gated Mixture-of-Experts (SMoE)를 채택하였다.
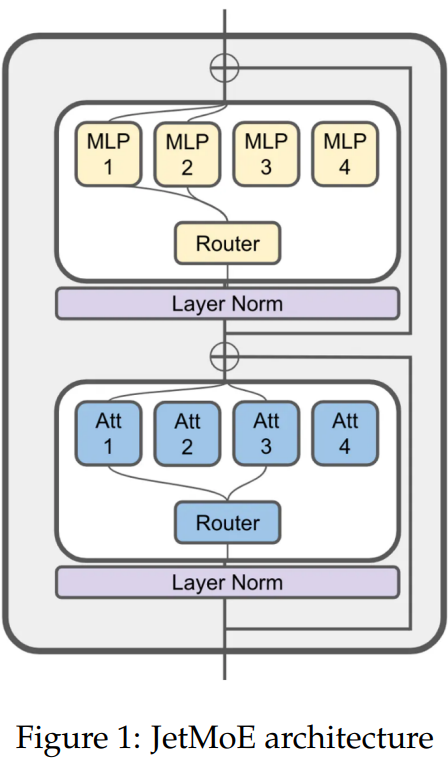
Model Architecture
Mixture of Experts
라우터의 출력에서 top-K logits을 선택하고

최종 출력은 전문가 출력의 가중합으로 계산된다.

Attention Expert
Attention layer에는 4개의 projection matrix Wq, Wk, Wv, Wo가 속해 있다.
효율성을 위해 K, V는 공유하고 Q, O만 각 전문가로 나뉜다.


전문가 당 여러 개의 attention head를 허용하고 RoPE를 사용한다.
Load Balancing during Pretraining
Frequency-based auxiliary loss

라우터가 특정 전문가를 선택할 확률 P와 실제로 할당된 토큰의 비율 f의 내적.
Uniform distribution에서 최소가 된다고 한다.
Router z-loss
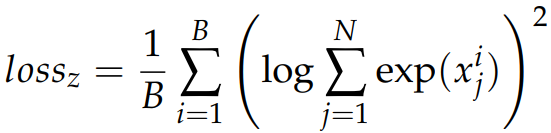
ST-MoE에서 제안한 손실로 라우터 내 logits의 크기를 줄여 반올림 오류를 최소화한다.
Total loss

Model Pretraining
Hyper-parameters:

3-stage의 WSD(Warmup-Stable-Decay) learning rate schedule을 사용한다.
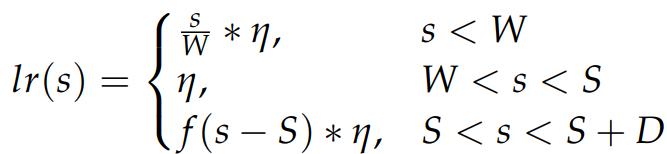
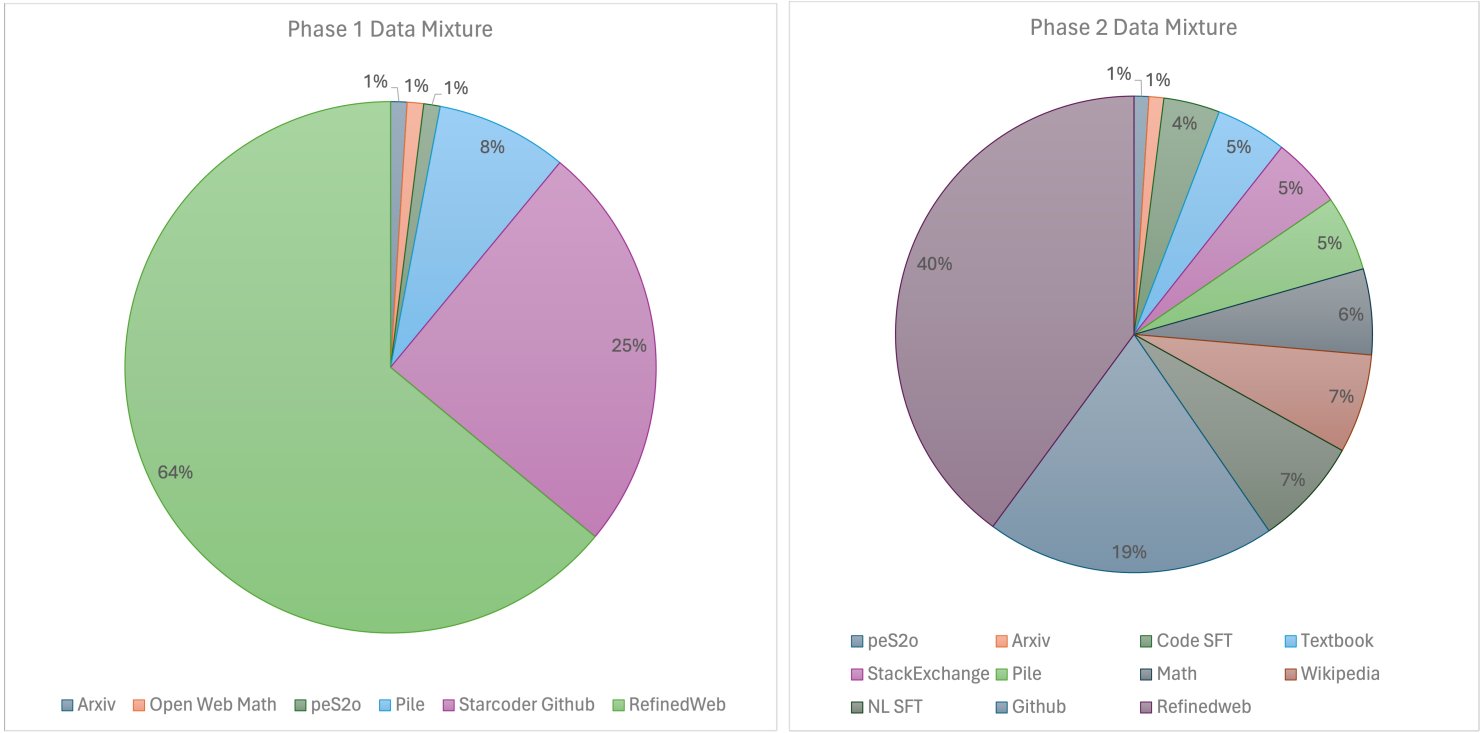
D-stage에서 고품질 데이터를 추가하는 훈련 데이터 혼합 전략 사용.
Model Alignment
Distilled Supervised Fine-Tuning (dSFT)
교사 모델(e.g. GPT-4, Claude)에서 생성된 데이터로 SFT 수행.
Distilled Direct Preference Optimization (dDPO)
교사 모델의 선호도로 DPO 수행.
실제로는 UltraFeedback(GPT-4를 이용해 제작됨)과 같은 데이터셋을 사용했다.
Evaluation





