Abstract
Hard token을 무시하고 useful token만을 선택적으로 훈련하는 Selective Language Modeling (SLM)을 사용하여 LLM pretraining의 훈련 효율성과 성능을 모두 향상시킨다.
[Github]
[arXiv](2024/04/11 version v1)
Introduction
철저한 필터링에도 불구하고 훈련 데이터에는 노이즈 토큰이 많이 포함되어 있다.
Rho-1은 이러한 'hard token'의 손실을 선택적으로 제거하는 Selective Language Modeling (SLM) 목표로 훈련되었다.

Selective Language Modeling
Not All Tokens Are Equal: Training Dynamics of Token Loss

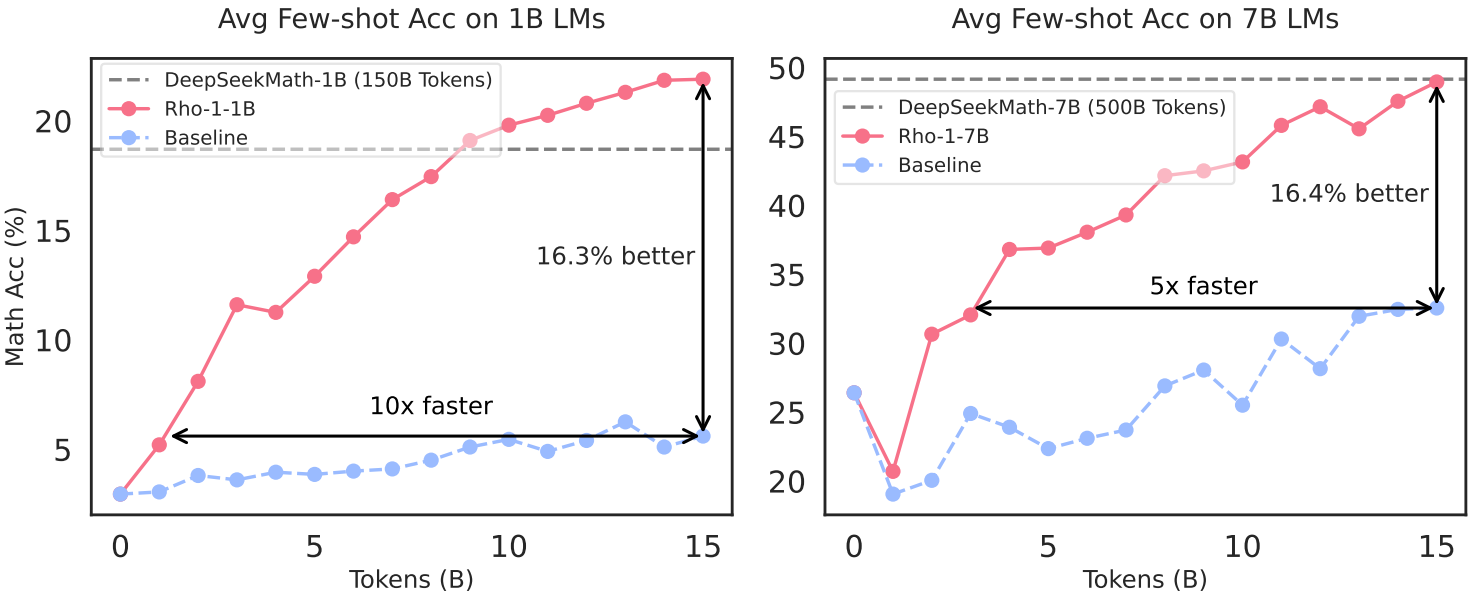
(a): Pretrained model을 계속 훈련했을 때 약 26%의 토큰만이 손실이 감소하였고 나머지는 이미 학습되었거나 학습되지 않았다.
(b), (c): 그러한 토큰들은 높은 분산을 가진 것으로 미루어 보아 노이즈가 존재함을 알 수 있다.
Selective Language Modeling

Reference Modeling
고품질 데이터를 선별하여 Reference Model을 훈련한다. RM은 더 큰 pretraining corpus 내에서 각 토큰에 대한 참조 손실을 평가하는 데 사용된다.

Selective Pretraining
일반적인 causal language modeling의 cross-entropy loss:
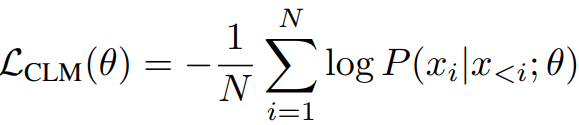
모델 θ에 대한 excess loss를 다음과 같이 정의:

Excess loss를 기준으로 손실이 높은 상위 k% 토큰만 훈련에 반영한다.
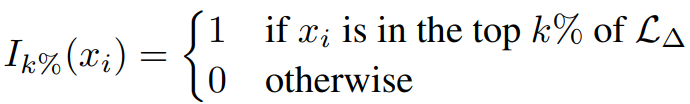

Experiments