Abstract
학습 중에 참조 정책을 업데이트하는 TR-DPO (Trust Region DPO) 제안
[arXiv](2024/04/15 version v1)
Method

Vanilla DPO는 고정된 참조 정책을 사용하지만 본문에서는 참조 정책을 업데이트할 것을 제안한다.
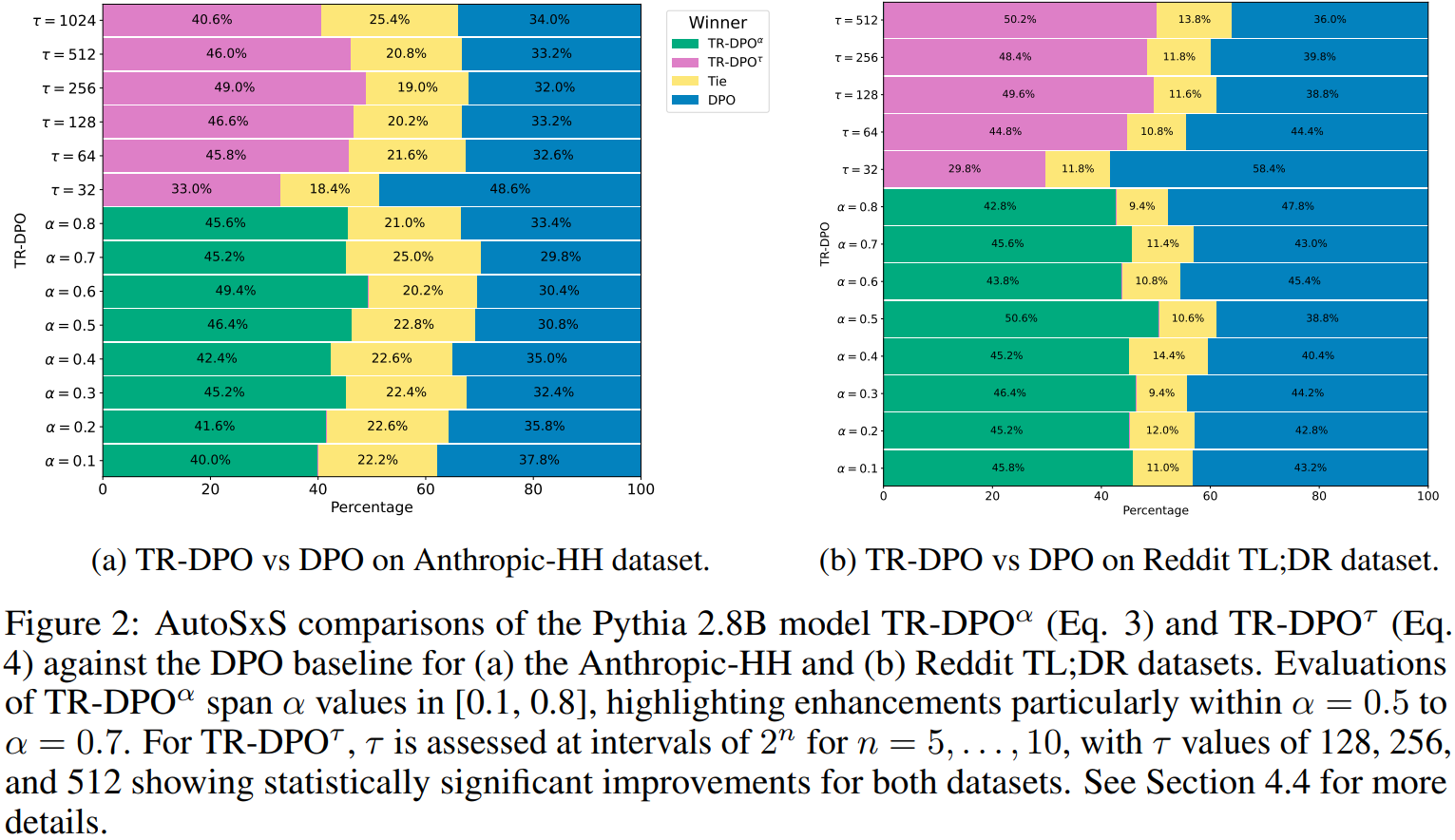
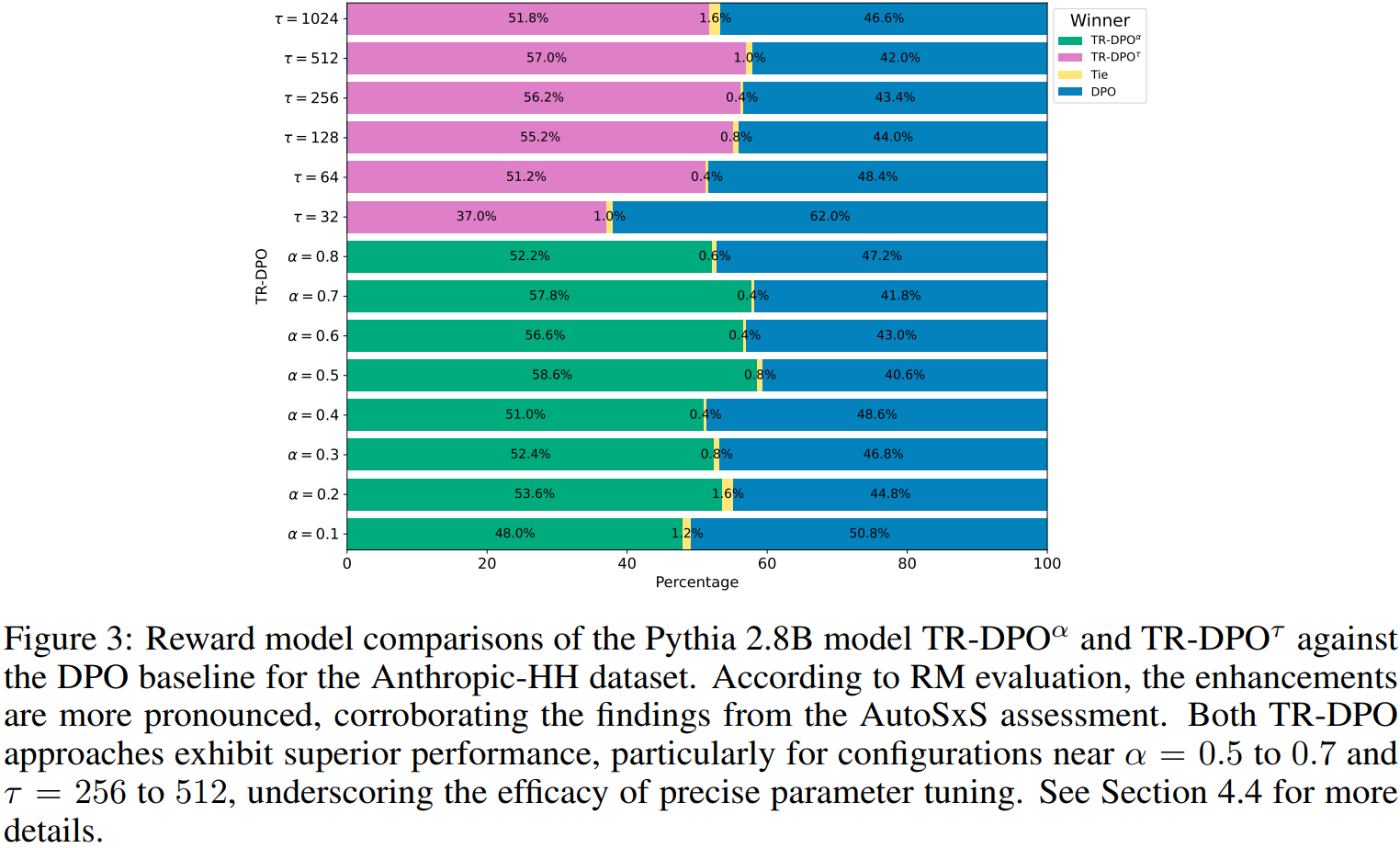
Soft update의 정도는 α의 값에 따라 결정되며 hard update는 𝜏 training step 후에 정책을 직접 대체한다.
Experiments
실험에는 Pythia 모델을 사용한다.
제안하는 방법론은 엄청나게 간단하고, 이후 다방면의 분석을 내놓고 있지만 결론적으로 𝛼 = 0.5 ~ 0.7, 𝜏 = 256 ~ 512의 값이 제일 적절하다고 말하고 있다.