Abstract
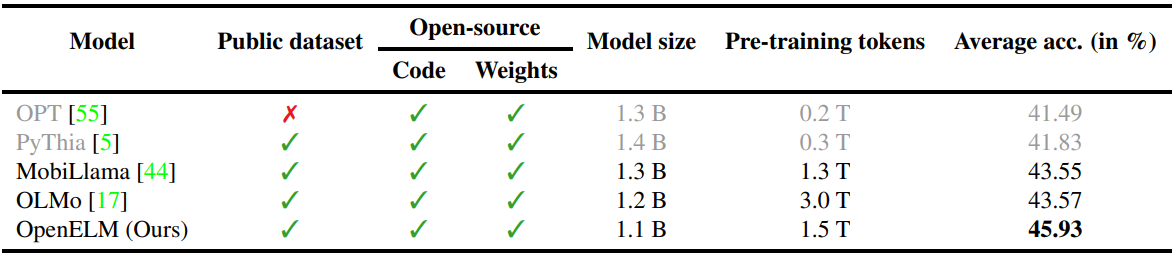
Layer-wise scaling을 적용한 경량 언어 모델인 OpenELM의 모든 정보, 프레임워크를 투명하게 공개
[Github]
[arXiv](2024/04/22 version v1)
Pre-training
OpenELM architecture
- FFN에서 bias를 사용하지 않음
- RMSNorm(Pre-Norm), RoPE
- Grouped query attention
- FFN에서 SwiGLU 사용
- Flash attention
- Llama와 동일한 tokenizer
- Decoder-only model
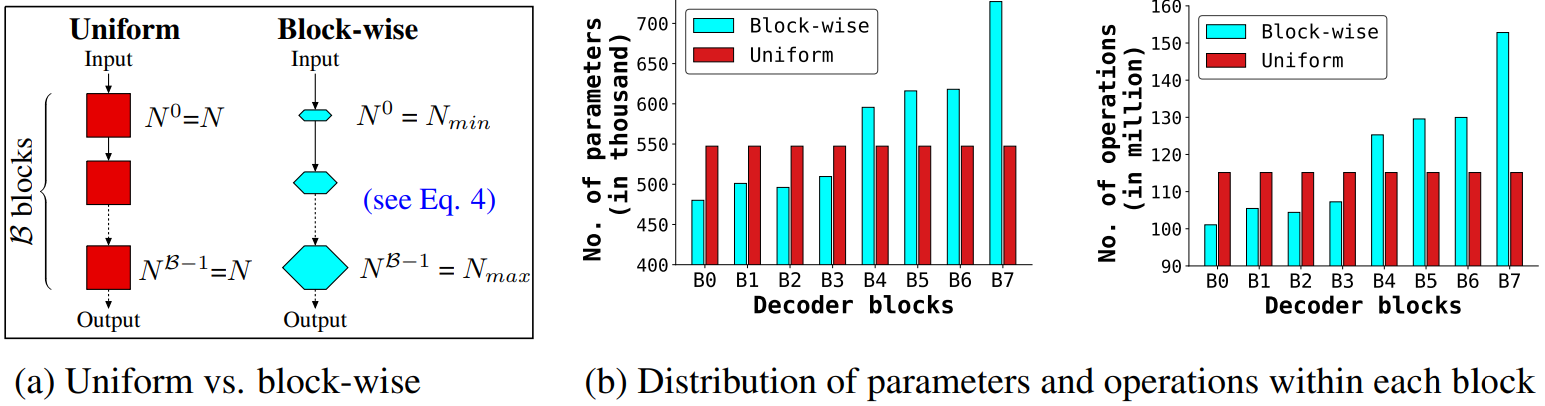
Layer-wise scaling
각 레이어별로 attention head 수, FFN의 hidden state dimention을 다르게 할당한다.
DeLighT에서 제안하였다. (해당 논문에서는 Block-wise scaling이라고 소개되었다.)
구체적으로 입력에 가까울수록 좁게, 출력에 가까울수록 넓게 피라미터를 할당하면 더 효율적이라고 한다.
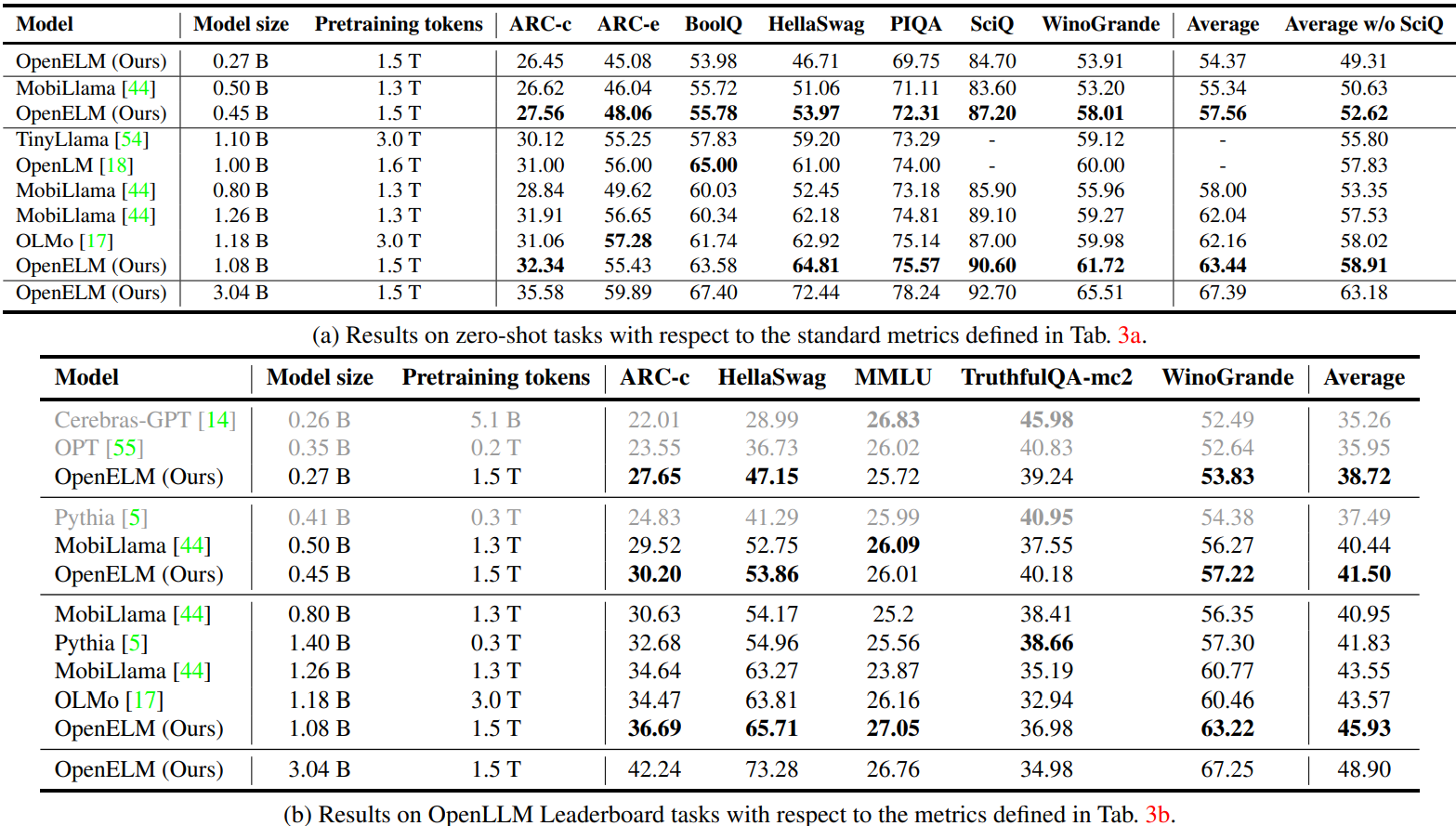
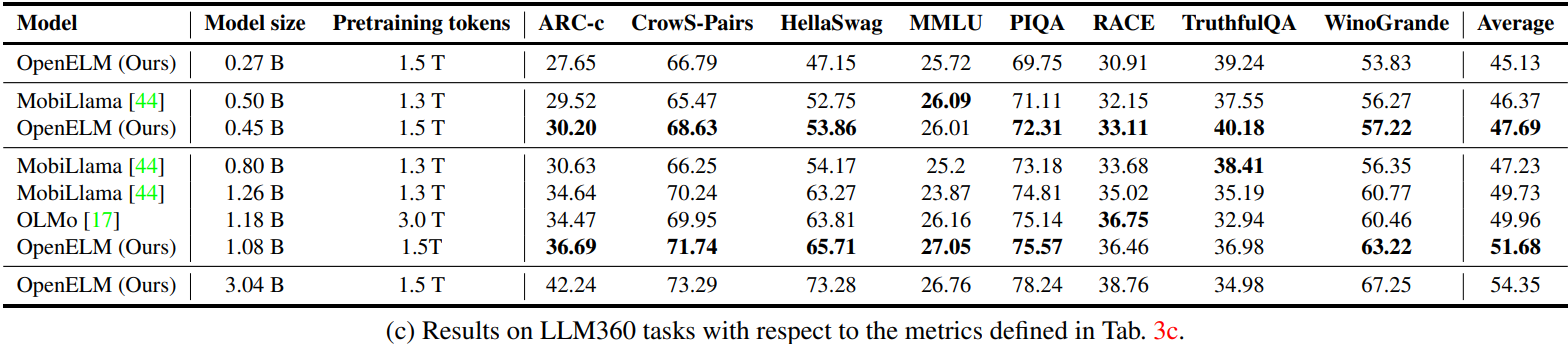
Experimental Results
'논문 리뷰 > Language Model' 카테고리의 다른 글
| Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding (0) | 2024.04.29 |
|---|---|
| On the Representation Collapse of Sparse Mixture of Experts (X-MoE) (1) | 2024.04.26 |
| Multi-Head Mixture-of-Experts (MH-MoE) (0) | 2024.04.26 |
| The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions (0) | 2024.04.25 |
| Phi-3 Technical Report (0) | 2024.04.25 |
| AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation (0) | 2024.04.25 |



