Abstract
MoE의 표현 붕괴 문제를 완화하고 더 안정적인 라우팅을 제공하는 X-MoE
[Github]
[arXiv](2022/10/12 version v3)
Background
Hidden state h와 각 전문가 임베딩 e (전문가 가중치와 다릅니다. 라우팅을 위한 벡터임.)의 내적으로 라우팅 점수를 계산한다.
전문가의 출력에 라우팅 가중치를 곱하고 잔차 연결을 더한 것이 MoE layer의 출력이다. (아래 수식은 Top-1의 경우)

Representation Collapse of Sparse Mixture-of-Experts
수식에 대한 도출 과정이 있긴 한데 생략하고 도출된 수식의 형태만 보자.
아래 수식은 입력 h에 대한 jacobian matrix를 분해한 일부이다.

e는 전문가 임베딩, c는 해당 전문가 가중치와 관련된 gradient라 보면 된다.
MoE가 transformer의 성능에 해를 끼칠 수 있는 2가지 문제를 제기한다.
1. 표현 축소
Top-K 라우팅에서 gradient는 K개의 전문가 임베딩의 선형 조합으로 업데이트되며 전문가 수가 N개라고 할 때 최대 N차원의 공간만을 표현할 수 있다. N은 모델의 hidden state dimention d 보다 훨씬 작기 때문에 전체 차원을 완전히 활용하지 못한다.
2. Hidden vector의 유사성 증가
h는 자신이 라우팅 된 전문가 임베딩과 유사해지는 경향이 있으며 같은 전문가로 라우팅되는 h들이 서로 가까워져 표현력과 다양성이 감소한다.
Method
Routing Algorithm
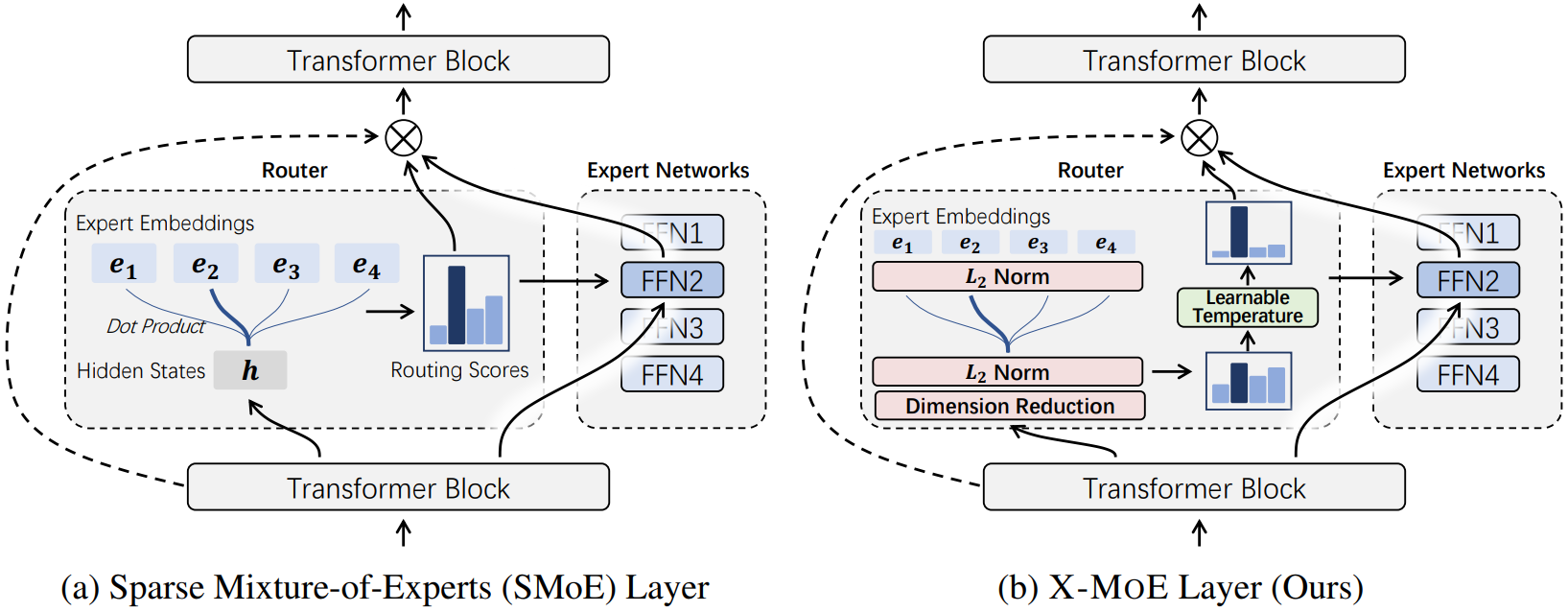
Dimension Reduction
Linear projection을 통해 라우팅 전 차원을 줄인다.
- h와 e의 직접적인 상호 작용을 격리하여 표현 축소를 완화한다. (h와 e가 유사해지는 것을 억제)
- 어차피 저차원으로 강제되는 거 연산 효율성이라도 높이자(?), 차원을 압축하고 아싸리 비슷한 차원끼리 연산하면 표현력을 개선할 수 있다(?)
L2 Normalization
표현의 균일성을 높여 지배적인 전문가가 나타나는 것을 피하기 위해 h와 e 모두 정규화한다.

Gating with Learnable Temperature
L2 Norm으로 인해 라우팅 점수가 균일해지고 상대적으로 높은 점수를 받은 전문가조차 충분히 활성화되지 않을 수 있다.
(출력에 라우팅 점수가 곱해지므로)
학습 가능한 스칼라 τ를 추가해 조절한다.

Training Objective
설명하기도 입 아플 정도로 자주 쓰이는 load balancing loss.
라우팅 확률과 실제 할당된 비율의 내적이다.
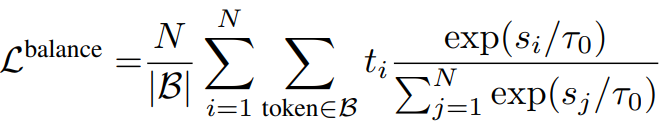
최종 손실:
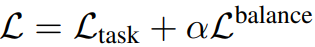
Frozen Routing During Fine-tuning
Fine-tuning 시에는 MoE와 관련된 모든 피라미터가 동결된다.
양이 적은 fine-tuning 데이터에 대해 일관성 없는 라우팅이 발생할 확률이 높기 때문이다.
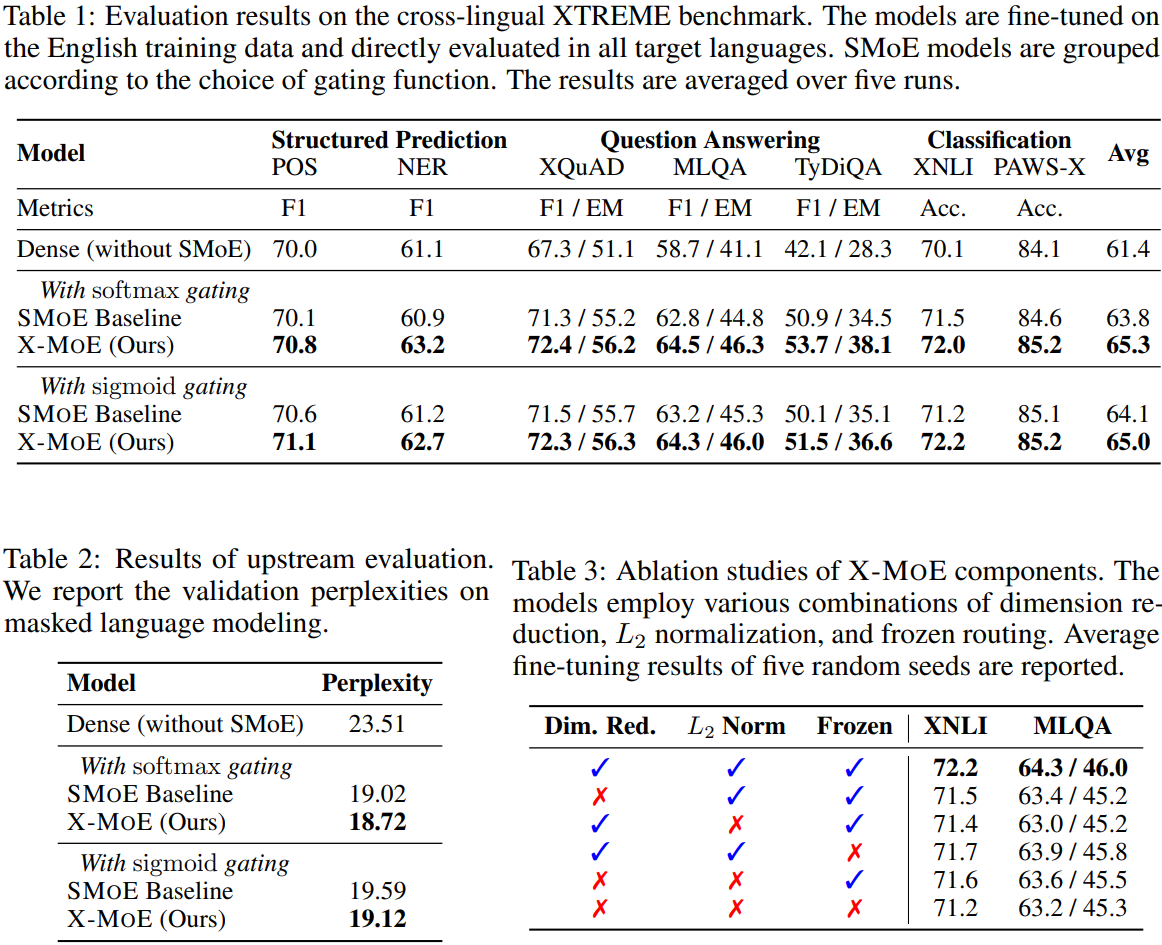
Experiments