


Abstract
고해상도 이미지에 대한 추가 vision encoder를 통해 이미지 이해를 향상한 Mini-Gemini
[Github]
[arXiv](2024/03/27 version v1)
Mini-Gemini

Dual Vision Encoders
LR encoder는 전통적으로 사용되는 CLIP-ViT, HR encoder는 CNN 기반 인코더인 ConvNeXt.
Patch Info Mining

(a) LR, HR 임베딩 간의 cross-attention.
(b) LR 이미지를 업스케일하여 visual token의 수를 N → 5N으로 증강할 수 있다. 필요시 HR 이미지 또한 증강 가능.
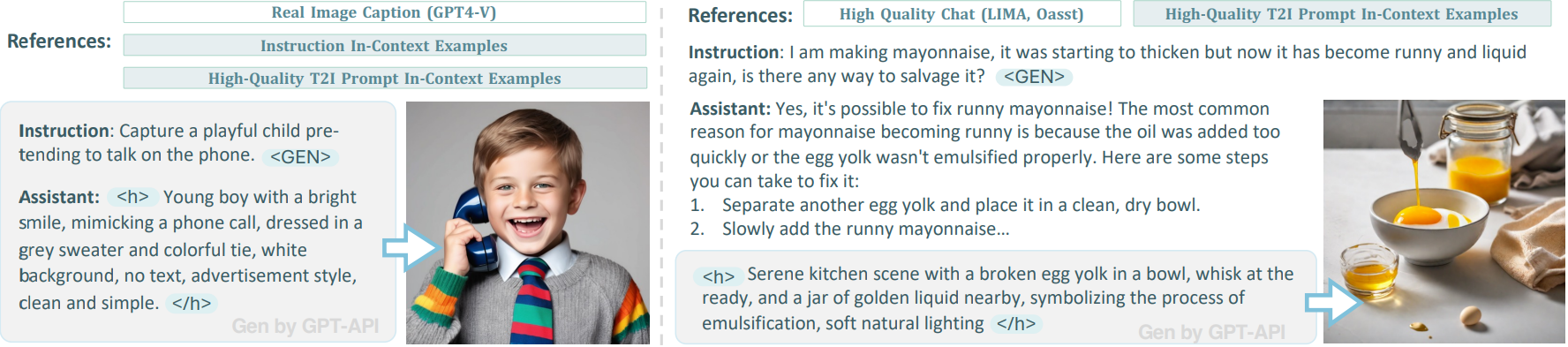
Text and Image Generation
Visual token과 text token을 연결하여 LLM에 입력하고 이미지 출력으로는 T2I 모델에 대한 prompt를 출력한다.
훈련을 위해 다양한 고품질 데이터를 수집하고 추가로 GPT-4 Turbo를 사용하여 instruction-following dataset을 구성.
Experiments
Vision encoder는 고정, patch info mining에 필요한 projectors는 modality 정렬, instruction tuning stage 모두에서 최적화되고 LLM은 instruction tuning stage에서만 최적화된다.
정성적 결과는 project page
Mini-Gemini
In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advance
mini-gemini.github.io



'논문 리뷰 > Language Model' 카테고리의 다른 글
| Advancing LLM Reasoning Generalists with Preference Trees (Eurus) (0) | 2024.04.04 |
|---|---|
| Gecko: Versatile Text Embeddings Distilled from Large Language Models (0) | 2024.04.03 |
| sDPO: Don't Use Your Data All at Once (0) | 2024.04.01 |
| Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking (0) | 2024.03.27 |
| STaR: Bootstrapping Reasoning With Reasoning (0) | 2024.03.27 |
| DoRA: Weight-Decomposed Low-Rank Adaptation (0) | 2024.03.26 |



