Abstract
LLM이 prompt를 읽거나 답변을 생성할 때 내부적으로 근거를 생각하며 추론하도록 하는 Quiet-STaR 제안
(쓰다 보니까 표기가 일관적이지 못한데, 근거 = 생각 거의 동의어입니다.)
[Github]
[arXiv](2024/03/18 version v2)
이전 연구 [STaR]
Quiet-STaR
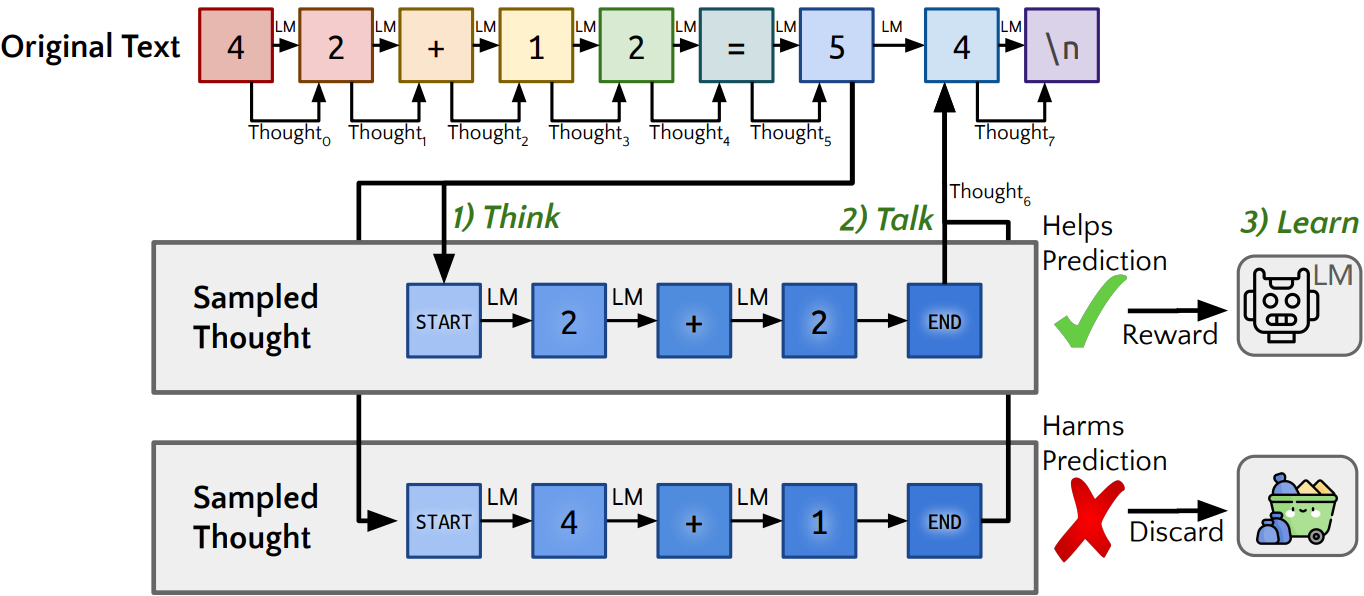
Overview
- 병렬적 근거 생성
- 근거와 기본 예측 혼합
- 근거 생성 최적화
Parallel Generation
입력 시퀀스의 '모든 토큰'에 대해 다음 토큰을 예측하기 위한 근거 생성. 병렬로 빠르게 생성할 수 있다.
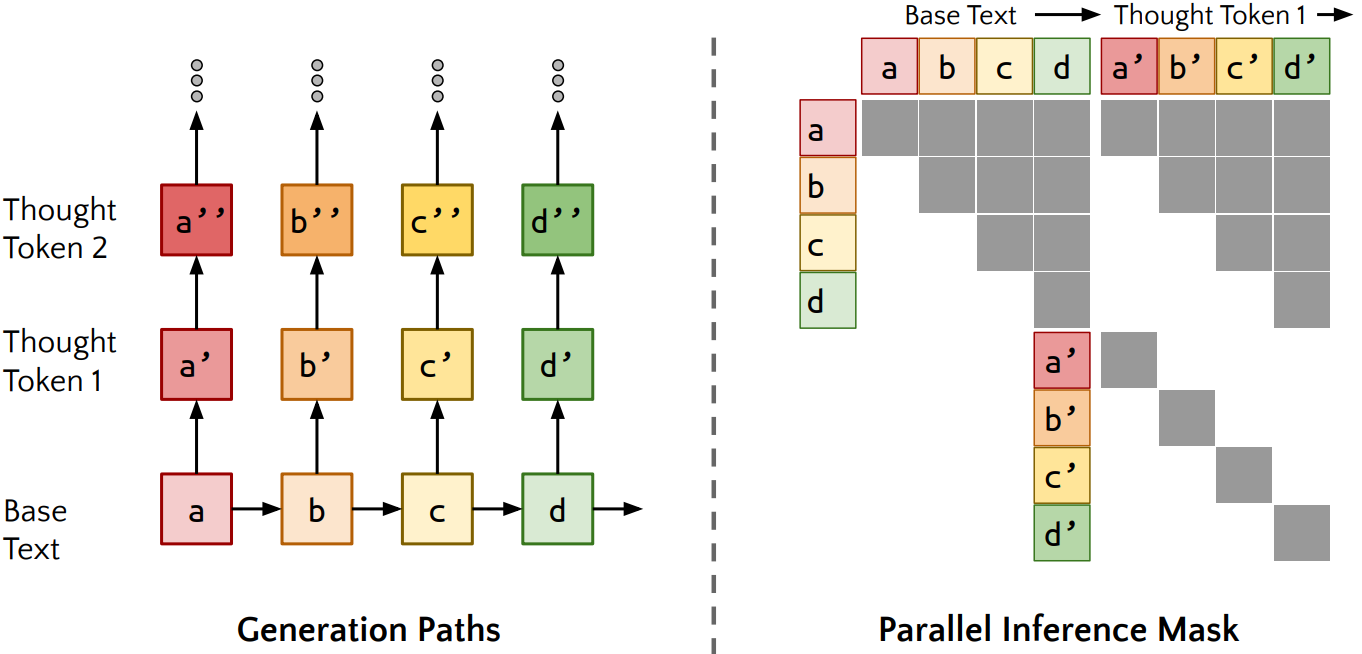
생각은 답변을 생성할 때뿐만 아니라 질문을 읽을 때도 발생할 수 있다.

“Mixing” (Residual) Heads
처음에는 '생각'에 대해 익숙하지 않으므로 성능이 저하된다. 생각 체제로의 원활한 전환을 위해 생각이 있는 예측과 없는 예측의 각 logits에 대한 가중치를 출력하는 간단한 MLP인 mixing head를 사용하여 두 logits을 선형 보간한다.
Optimizing Rationale Generation
Optimizing Start-of-Thought and End-of-Thought Tokens
근거 생성을 제어하기 위한 meta-token으로 <|startofthought|>, <|endofthought|>을 도입한다.
생각 시작 및 끝 토큰을 em dash ("---")의 임베딩으로 초기화하면 빠르게 최적화된다.
Em dash는 보통 텍스트 데이터에서 일시중지 또는 생각을 나타내기 위해 사용된다.
Non-myopic Scoring and Teacher-forcing
훈련에서 t+1번째 토큰 생성 시 t 시점까지의 모델 출력이 아니라 ground truth를 입력으로 사용하는 teacher forcing 채택.

Objective
강화학습의 개념을 차용했다.
입력 시퀀스 X에서 prompt 부분의 길이를 j, 예측해야 하는 부분의 길이를 ntrue, mixed logits의 확률을 ptalk이라고 하자.
각 토큰에 대해 여러 개의 근거를 생성하고 근거 집합 T에서 각 근거 Tj에 대한 보상 rj를 (특정 근거에서 정답을 출력할 확률 - 근거 전체의 정답 출력률의 평균)으로 정의한다. 평균을 빼는 이유는 강화학습에서의 advantage처럼 분산을 줄이기 위함이다.

손실에서 이 보상을 사용하여 더 좋은 근거의 likelihood를 높인다.
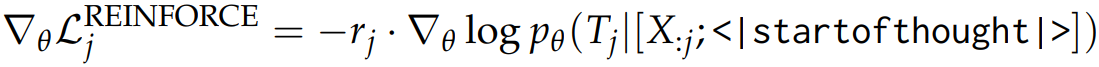
위 손실의 gradient는 LM parameter와 생각 시작, 끝 임베딩을 업데이트하는 데 사용된다.
추가로 보상이 음수인 부정적인 근거를 제거하면 보다 안정적인 훈련이 가능하다고 한다.
반복적인 최적화를 통해 보다 유용한 근거를 생성하도록 할 수 있다.
최종 출력에 대한 기본적인 negative log likelihood (NLL) loss도 추가한다.

Experiments
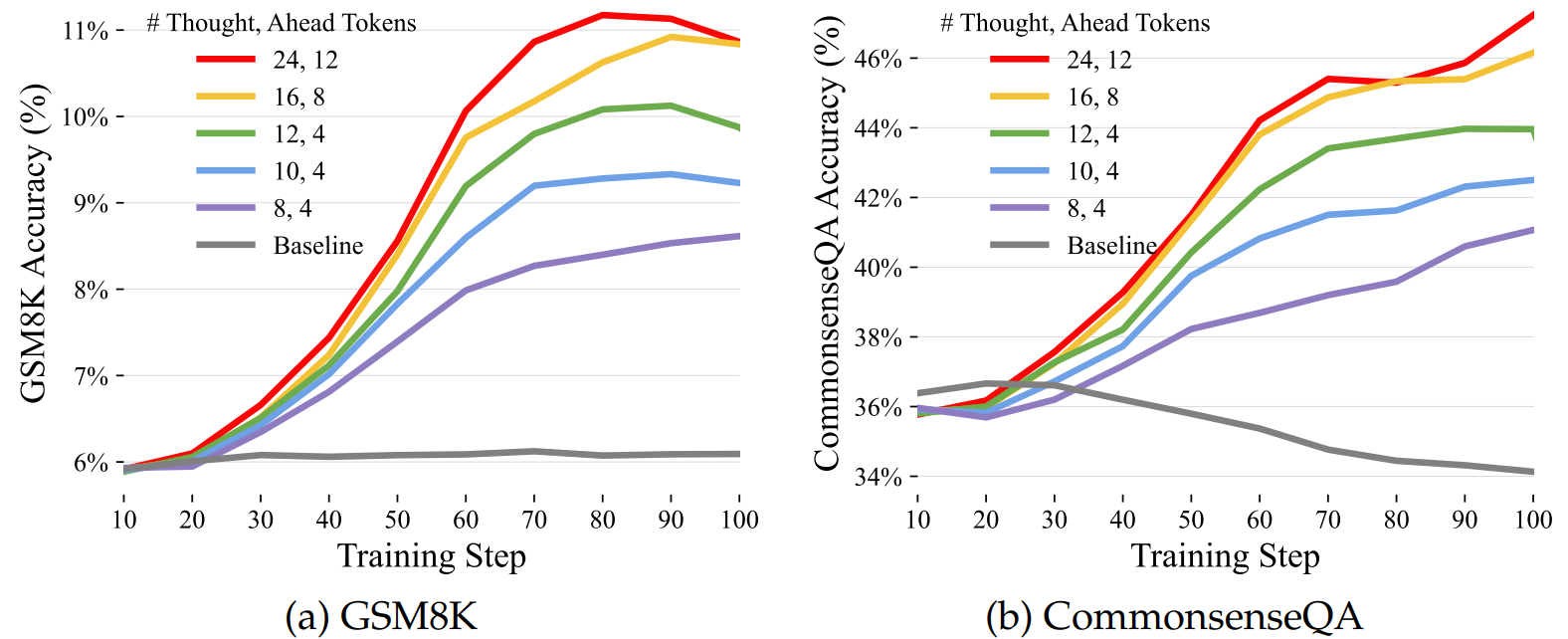
생각의 갯수와 생각 토큰 수에 대한 성능 향상
Limitations
실제 환경에서는 복잡한 계산 없이 쉽게 토큰을 예측할 수 있는 경우도 많으며 Quiet-STaR가 불필요하게 많은 오버헤드를 발생시키는 것도 사실이다.
적절한 상황에서만 이러한 방법을 사용하거나 생각의 길이를 동적으로 결정하는 것은 개선해야 할 사항이다.
'논문 리뷰 > Language Model' 카테고리의 다른 글
| Gecko: Versatile Text Embeddings Distilled from Large Language Models (0) | 2024.04.03 |
|---|---|
| sDPO: Don't Use Your Data All at Once (0) | 2024.04.01 |
| Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models (0) | 2024.04.01 |
| STaR: Bootstrapping Reasoning With Reasoning (0) | 2024.03.27 |
| DoRA: Weight-Decomposed Low-Rank Adaptation (0) | 2024.03.26 |
| LoRA+: Efficient Low Rank Adaptation of Large Models (0) | 2024.03.22 |



