
Abstract
Query-passage pair를 순진하게 사용하지 않고 재지정하여 text embedding dataset의 품질 향상
[arXiv](2024/03/29 version v1)
Training Recipe for Gecko
Pre-finetuning
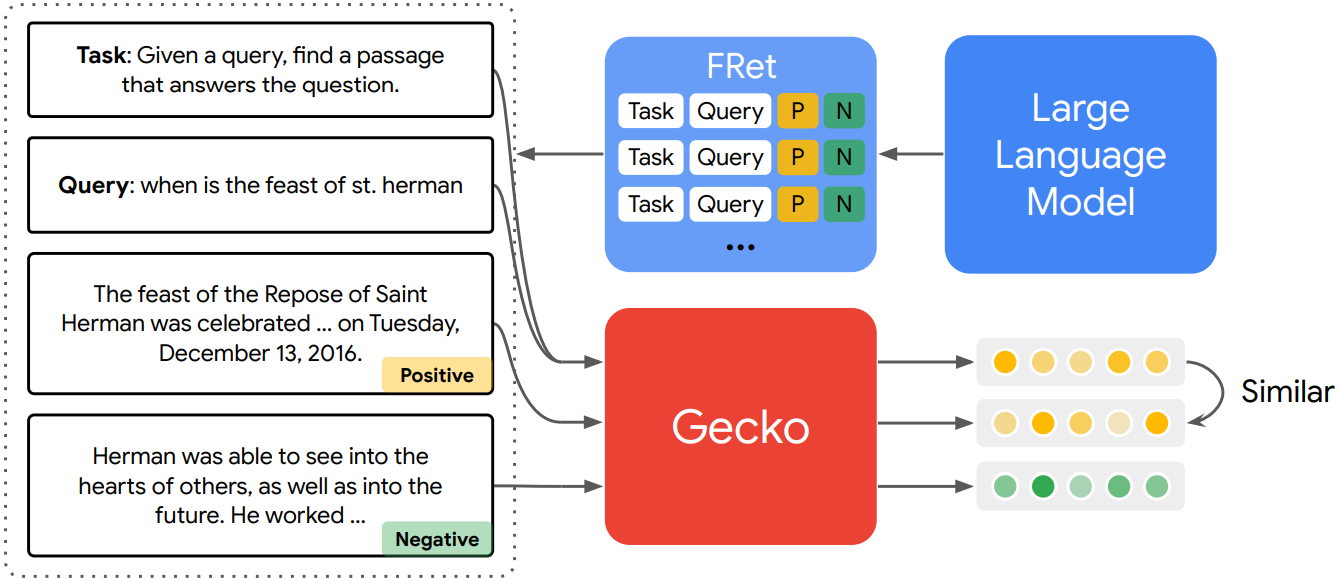
일반적인 LLM 기반 text embedding model의 훈련 방법. 또한 Gecko의 사전 훈련.
대규모 QA, title-body pair 수집. (q-p pair)
그 후 사전 훈련된 LLM에 task t, query q, passage p를 입력하여 토큰 시퀀스를 얻고 대조 학습을 통해 fine-tuning 한다.


FRet: Two-Step LLM Distillation
LLM을 통해 FRet (Few-shot Prompted Retrieval) dataset을 생성하는 과정 소개.
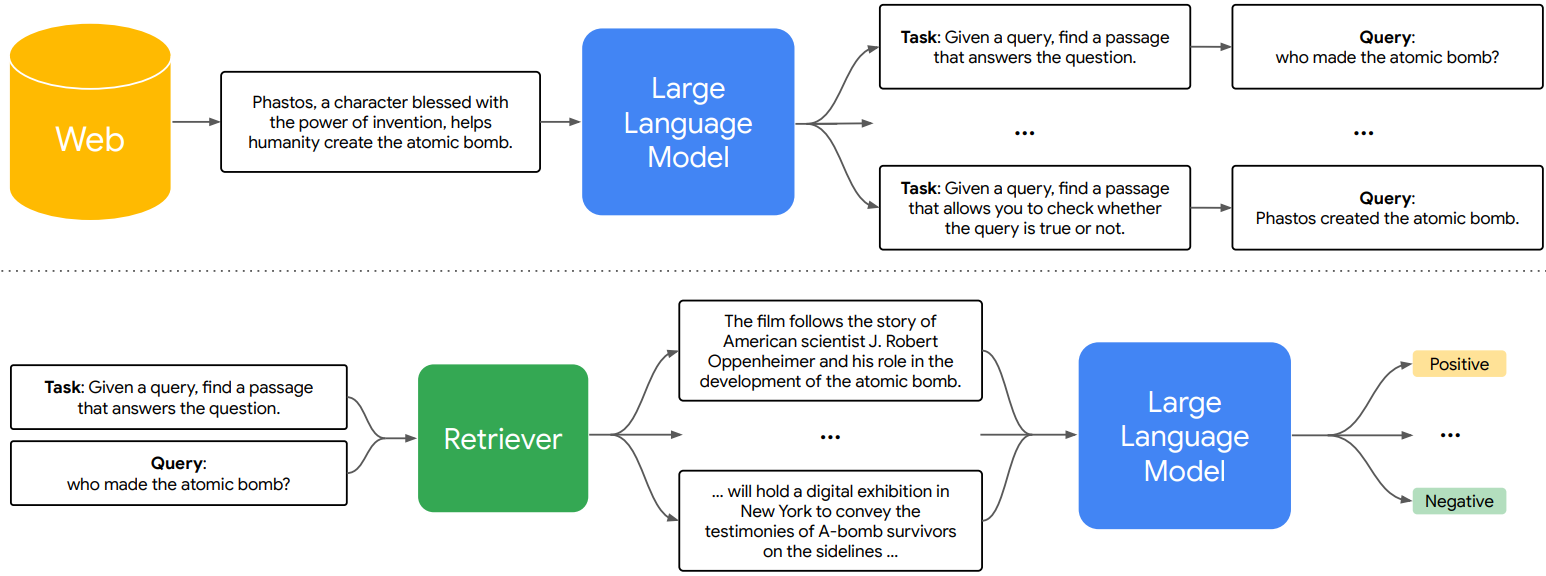
LLM-based Diverse Query Generation
고정 prompt ℙ, web corpus에서 무작위로 추출된 구절 pseed에서 다양한 task와 query를 생성.

LLM-based Positive and Negative Mining
이때, 순진하게 (q, pseed) 쌍으로 훈련하지 않고 retriever model을 통해 q에 적절한 pseed의 이웃 p 집합을 검색하고 LLM을 통해 평가하여 랭킹 R을 얻는다.
랭킹이 가장 높은 p를 positive p로 선택하고

negative p는 가까운 이웃에서 샘플링하거나 랭킹이 낮은 p를 선택할 수 있다.
Unified Fine-tuning Mixture
동일한 형식(t, q, p+, p-)의 다른 학술, 분류 데이터와 결합하여 Gecko 훈련을 위한 fine-tuning mixture를 만든다.
Training Objective
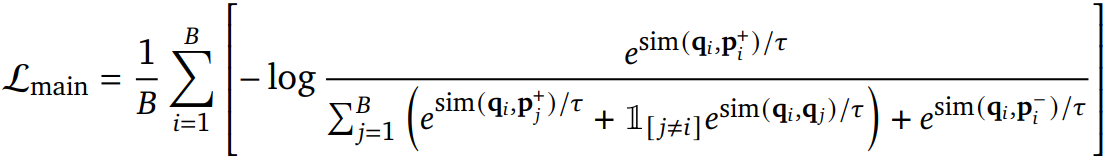
다양한 임베딩 크기를 지원할 수 있도록 MRL loss 사용. 보다 작은 하위 차원으로 임베딩하여 목표를 최적화한다.
Experiments





