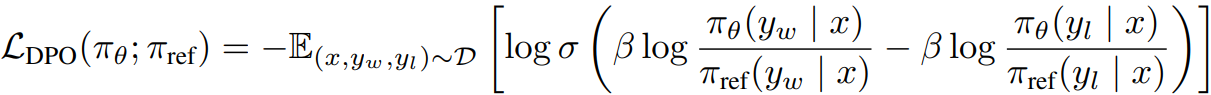Abstract
Multi-turn interaction 궤적을 수집하여 SFT, Preference Learning에 사용
[Github]
[arXiv](2024/04/02 version v1)
UltraInteract: Tree-structured Alignment Data for Reasoning
Instruction은 root고 action은 node이다.
Correct action의 모든 node와 correct action으로 끝나는 모든 궤적이 SFT에 사용될 수 있다.
Node pair와 궤적 쌍을 선호도 학습에 사용할 수 있다.

Instruction Selection Emphasizing Complexity, Quality, and Diversity
수학 문제 해결, 코드 생성, 논리적 추론 작업을 목표로 한다.
GPT-3.5-Turbo가 해결하지 못하는 어려운 문제, 실제 솔루션이 있는 데이터로 데이터셋을 구성한다.
솔루션은 critique model에 대한 참조 역할을 한다.
Decomposition and Interaction at Each Turn
Actor model(= GPT-3.5-Turbo)이 CoT 등의 기술을 활용해 문제를 최대한 해결하고, critique model(= GPT-4)은 observation(e.g. Python interpreter)을 고려하여 오류를 찾고 개선을 위한 방법을 제안한다.

Preference Trees Facilitates Preference Learning Across Multiple Turns
Sampling Paired Correct and Incorrect Actions at Each Turn
각 턴마다 correct-incorrect pair를 샘플링한다.
GPT-4와 같은 강력한 actor를 사용해도 해결하지 못하는 문제들은 다음과 같은 조치를 취한다.
더 많은 action을 샘플링 → 더 강력한 모델(e.g. GPT-4-Turbo) 사용 → actor에게 GT 솔루션을 제공하여 올바른 조치를 유도
Tree-structured Action Pairs Across Multiple Turns
Incorrect action을 다음 턴으로 확장.
Additional Instruction-action Pairs for Challenging Problems
마지막 조치를 취할 만한 어려운 문제들은 귀중한 훈련 신호라는 직관으로 correct-incorrect pair를 추가로 샘플링한다.
Eurus: State-of-the-art Open LLMs in Reasoning
Mistral-7B에서 UltraInteract data를 통해 SFT → Preference Learning 수행.
Reward Modeling
Eurus-7B-SFT에 선형 레이어를 추가하여 보상 모델링.
Chosen, rejected action에 대해:
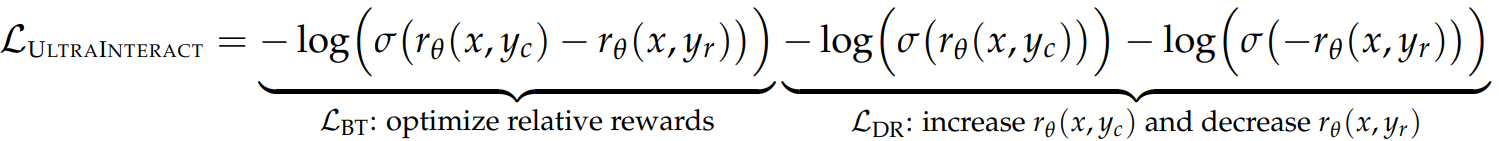
Evaluation of EURUS-7B and EURUS-70B
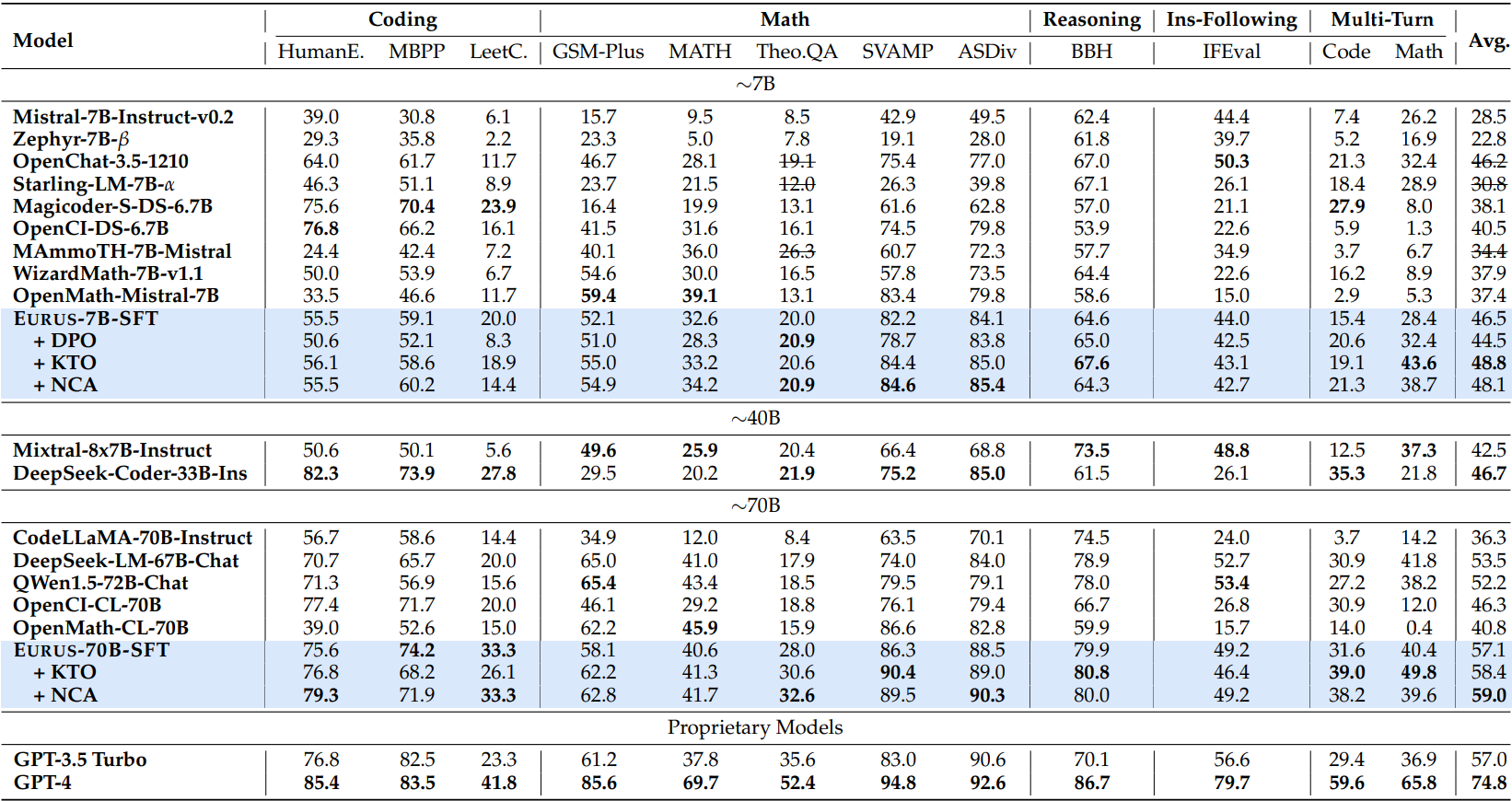
DPO는 오히려 성능이 저하되었는데, 연구진은 DPO가 chosen action의 절댓값이 아니라 rejected action과의 상대적인 차이에만 집중하기 때문에 chosen action의 확률이 증가하지 않을 수도 있다고 추정했다.