효율성이 높은 LLaMA2 기반 모델. LLaMA2 보다 성능 좋음.
[Github]
[arXiv](2023/10/10 version v1)

Model Architecture
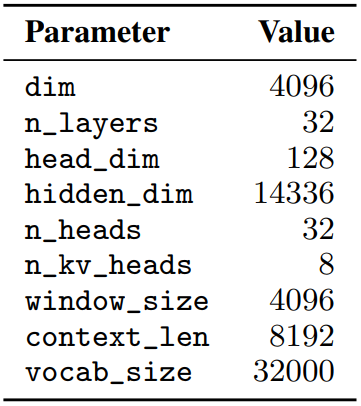
Sliding Window Attention
Window size W개의 이전 토큰에 대해 attention을 수행한다. 이전 토큰은 또다시 이전 레이어에서 이전 토큰에 대한 attention을 수행하므로 마지막 레이어의 토큰은 최대 약 13만개(4096x32) 토큰의 영향을 받는다.
FlashAttention과 xFormers를 추가로 채택하여 Vanilla attention에 비해 2배의 속도 향상을 얻었다.
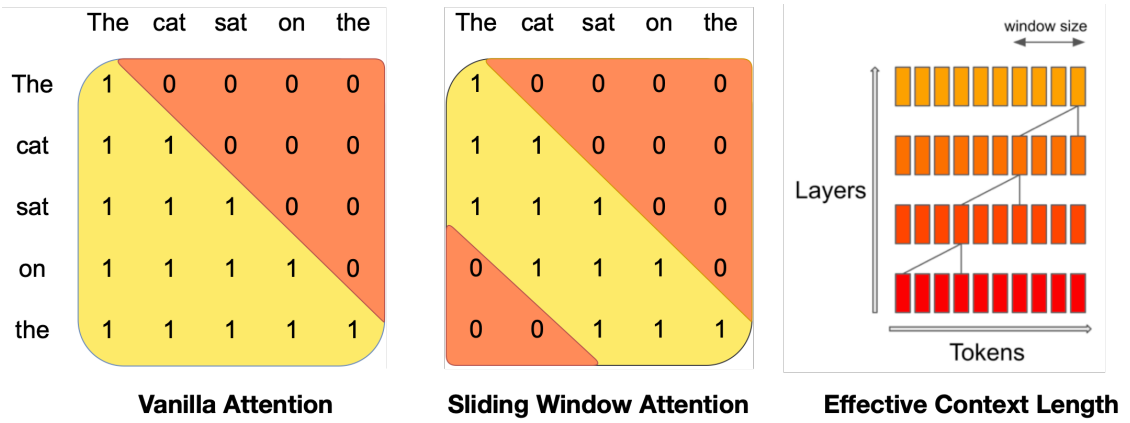
Rolling Buffer Cache
고정된 캐시 크기를 사용한다. 아래 그림은 캐시 크기 = 4일 때의 예시이다.

캐시에 자리가 없을 경우 가장 먼저 추가됐던 캐시의 자리에 덮어쓴다.
Pre-fill and Chunking
시퀀스 생성 시 각 토큰은 이전 토큰에 따라 조건이 달라지기 때문에 토큰을 하나씩 예측해야 한다.
그러나 프롬프트는 이미 알고 있으므로 (K, V) 캐시를 미리 채울 수 있으며, 프롬프트가 매우 긴 경우 메모리를 제한하기 위해 청크로 나누어서 캐시를 미리 채운다. chunk size= window size.
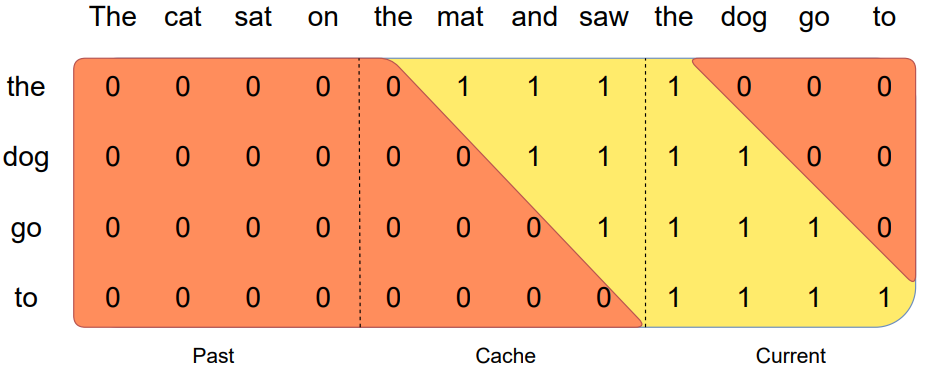
근데 이 부분을 읽으면 나만 그런 건지는 모르겠는데 설명이 상당히 애매하다. 위 그림만 보면 캐시 청크가 고정돼 있는 것처럼 보이는데 그렇다면 현재 청크의 이전 토큰의 K, V는 매번 다시 계산하는 것인가? 그리고 캐시 청크의 sliding window가 지나간 부분은 필요 없는 부분인데?
내 생각에는 이렇게 작동하는 것 같다.
K 시점:

K + 1 시점:

이거 아님??? 아님말고
'논문 리뷰 > Language Model' 카테고리의 다른 글
| DiffusionGPT: LLM-Driven Text-to-Image Generation System (0) | 2024.01.24 |
|---|---|
| Towards Conversational Diagnostic AI (AMIE) (0) | 2024.01.18 |
| Mixtral of Experts (Mixtral 8x7B) (0) | 2024.01.11 |
| TinyLlama: An Open-Source Small Language Model (0) | 2024.01.09 |
| DocLLM: A layout-aware generative language model for multimodal document understanding (0) | 2024.01.09 |
| LLaMA Beyond English: An Empirical Study on Language Capability Transfer (2) | 2024.01.08 |



