4월 25일 공개된 StyleGAN-Human: A Data-Centric Odyssey of Human Generation
StyleGAN-Human: A Data-Centric Odyssey of Human Generation
Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on "network engineering" such as designing new components and objecti
stylegan-human.github.io

Abstract
무조건적인 인간 이미지 생성의 기존 연구는 주로 "네트워크 엔지니어링"에 중점을 둔다. 본 논문에서는 데이터 중심적 관점을 취하고 "데이터 엔지니어링"의 여러 중요한 측면을 조사하며 현재 관행을 보완할 것이라고 믿는다. 연구를 용이하게 하기 위해 다양한 포즈와 texture를 캡처하는 230,000개 이상의 샘플로 대규모 인간 이미지 데이터 세트를 수집하고 주석을 달았다. 데이터 엔지니어링의 세 가지 필수 요소, 즉 데이터 크기, 데이터 배포 및 데이터 정렬, 광범위한 실험은 다음과 같은 측면에서 몇 가지 귀중한 관찰을 보여준다.
- Vanilla StyleGAN을 사용하여 충실도가 높은 무조건 인간 생성 모델을 훈련하려면 40,000개 이상의 이미지가 있는 대규모 데이터가 필요하다.
- 균형 잡힌 훈련 세트는 long-tailed counterpart에 비해 희귀한 얼굴 포즈가 있는 생성 품질을 향상시키는 데 도움이 되지만, 단순히 의복 texture 분포의 균형을 맞추는 것만으로는 효과적으로 개선되지 않는다.
- 정렬을 위해 body center를 사용하는 인간 GAN 모델은 얼굴 또는 골반 지점을 정렬 앵커로 사용하여 훈련된 모델보다 성능이 뛰어나다.
또한, 향후 연구를 용이하게 하기 위해 model zoo와 인간 편집 응용 프로그램을 시연한다.
Introduction
GAN 계열 중에서 StyleGAN2는 전례 없는 이미지 품질로 얼굴과 단순한 객체를 생성하는 것이 돋보인다. 이는 설득력 있는 결과를 보여주지만, 이를 자연복을 입은 관절형 인간의 photo-realistic 생성에 적용하는 것은 여전히 도전적이고 개방적인 문제이다.
본 연구에서는 데이터학적 관점에서 관절형 인간을 위한 좋은 StyleGAN 기반 모델을 훈련시키는 것을 목표로 하여 무조건적 인간 생성 작업에 중점을 둔다.
- 1024x512 ~ 2240x1920 해상도를 가진 230k개의 깨끗한 전신 이미지를 포함하는 Stylish-Humans-HQ Dataset (SHHQ)을 제안한다.
- 제안된 SHHQ 데이터 세트를 기반으로 이전 연구에서 충분히 논의되지 않은 근본적이고 중요한 질문을 조사하고 무조건적인 인간 생성에 대한 향후 연구에 유용한 통찰력을 제공하려고 시도한다.
Q1. 데이터셋 크기와 생성 품질은 어떤 관계가 있습니까?
Q2. 데이터 분포와 생성 품질은 어떤 관계가 있습니까?
Q3. 데이터 정렬 방식과 생성 품질은 어떤 관계가 있습니까?
제안된 SHHQ 데이터셋과 실험의 관찰을 기반으로, 널리 채택된 세 가지 무조건 생성 모델인 StyleGAN, StyleGAN2, Alias-Free StyleGAN(StyleGAN3)과 함께 model zoo를 구축한다.
또한 얼굴 모델을 기반으로 한 이전 편집 방법을 인체 모델에 적용하여 인간 편집 벤치마크를 구성한다(이미지 반전을 위한 PTI, InterFaceGAN, StyleSpace, 이미지 조작을 위한 SeFa). 최근에 나온 모델인 InsetGAN 또한 본 연구의 기준 모델로 평가되어 사전 훈련된 인간 생성 모델의 잠재적 사용을 추가로 보여준다.
본 논문의 주요 기여는 다음과 같다.
- SHHQ Dataset 제안
- 세 가지 중요한 질문을 조사하고 포괄적인 분석을 통해 관찰에 대해 논의
- Model zoo 구축, 편집 벤치마크 확립
Related Work
Dataset For Human Generation
인간 중심 훈련 데이터 세트는 훈련에 중요한 연료이다. 인증된 데이터셋은 다음과 같은 측면을 준수해야 한다.
- Image quality : 풍부한 texture을 가진 고해상도 이미지는 상세한 의미정보를 제공한다.
- Data volume : 과적합을 방지하기 위해 충분히 많아야 한다.
- Data coverage : 모델의 다양성을 보장하기 위해 여러 속성의 차원을 다루어야 한다.
- Data content : 이미지는 하나의 완전한 인체를 포함해야 한다.
Deep Fashion, Market1501 등의 공개적으로 사용 가능한 인체 데이터셋들이 있지만 몇 가지 단점들이 있고 본 연구에서 요구되는 공개적으로 사용할 수 있는 고품질 및 대규모 인체 전체 데이터 세트는 없다.
StyleGAN
StyleGAN, StyleGAN2, Alias-Free StyleGAN(StyleGAN3)
Human Generation
기존 대부분의 인간 생성 연구에서는 VAE, U-Net, StyleGAN 관련 아키텍쳐 등을 활용하여 자세와 외모를 제어하는 데 초점을 맞추고 있다. 이러한 작업은 추가 네트워크 수정과 특정 인간 우선 순위에 의존하며 "네트워크 엔지니어링"으로 요약될 수 있다. 이와는 대조적으로, 본 연구는 데이터 관점에서 무조건적인 인간 생성 문제를 조사한다.
Image Editing
StyleGAN의 혜택을 받는 다운스트림 작업 중 하나는 이미지 편집이다. 표준 이미지 편집 파이프라인은 일반적으로 실제 이미지에서 잠재 공간으로 반전하고 내장된 잠재 코드를 조작하는 것을 포함한다.
PTI, InterFaceGAN, StyleSpace, SeFa 등이 있음.
Stylish-Humans-HQ Dataset
Data Collection and Preprocessing
먼저 인터넷에서 500K 이상의 인간 이미지 원시 데이터를 얻는다.

그리고

- 1024x512 보다 작은 이미지 폐기 (a)
- Human segmentation을 이용하여 적절히 잘라내고, 패딩 및 크기 조절, 정렬을 통해 이미지 중심에 배치
- 신체 일부가 잘린 이미지 폐기 (c)
- Human pose estimation을 이용하여 극단적인 포즈의 이미지 폐기 (d)
- 여러 사람이 포함된 이미지의 경우 폐쇄되지 않은 온전한 전신인 인물만 유지 (e)
- 배경 제거
Data Statistics
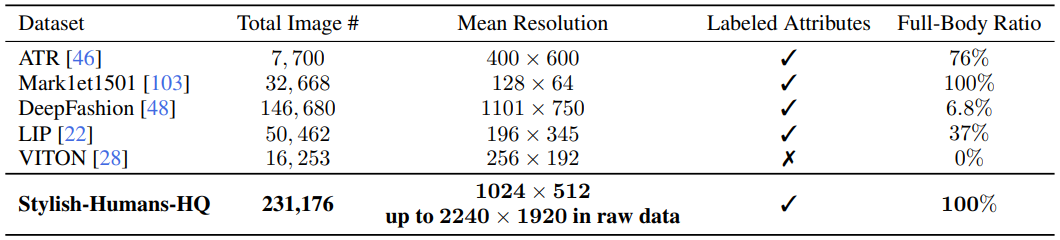
SHHQ 데이터셋과 다른 데이터셋들을 비교한 표. 갯수도 압도적으로 많고 해상도도 제일 높으며 라벨이 있고, 모든 이미지에서 전신이 포함되어 있다.

그 중에서도 인간 생성 작업과 가장 가까운 폐색된 신체 이미지를 제거한 Filtered-DeepFashion과의 상세 비교.
모든 부분에서 더 다양하고 풍부한 정보를 가지고 있음을 알 수 있다.
Systematic Investigation
StyleGAN2 아키텍쳐를 베이스로 데이터 크기, 분포, 정렬을 연구하기 위해 광범위한 실험을 수행했다.
Data Size
크기에 따라 6개의 하위 데이터셋을 구성하고 각각을 S0(10K), S1(20K), S2(40K), S3(80K), S4(160K), S5(230K)로 표기. S0는 Filtered-DeepFashion 이다. 각 세트에 대한 두 가지 해상도(1024x512, 512x256)에 대해 교육하며 S0, S1, S2는 ADA를 사용한 추가 훈련도 진행한다. 평가 지표로는 FID(Frechet' Inception Distance)와 IS(Inception Score) 사용.

데이터셋의 크기가 커질수록 FID가 개선되며 점점 하락폭이 적어지면서 수렴한다.
ADA는 40K 미만의 데이터셋에서 유의미 하지만 그 이상에서는 무의미하다.
Data Distribution
GAN의 특성은 모델이 훈련 데이터셋의 분포를 상속하고 데이터셋 불균형으로 인한 생성 편향을 도입하도록 한다. 이러한 편향은 GAN 모델의 성능에 심각한 영향을 미친다.
이 연구에서 얼굴 충실도가 시각 인식에 상당한 영향을 미치고 의복이 전신 이미지의 많은 부분을 차지하기 때문에 인체 이미지를 얼굴 방향과 의복 texture의 patch로 분해한다.

그리고 얼굴 방향 각도와 의복 texture 데이터셋을 SHHQ에서 각각 long-tailed 세트와 균등 세트로 수집한다.
(얼굴은 대칭이기 때문에 양의 각도인 분포 데이터셋만 수집.)
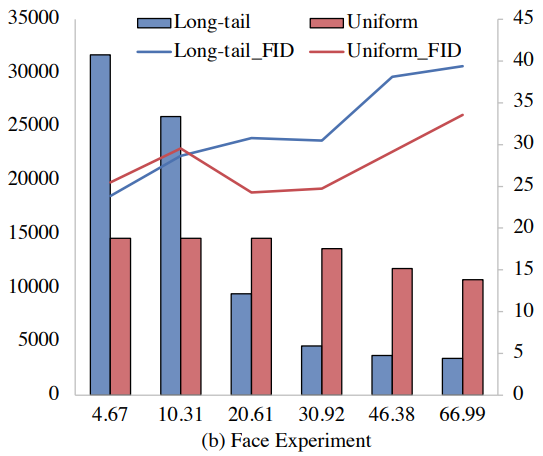
얼굴 방향에 대한 Long-tailed 실험의 경우 얼굴 각이 큰 세트일수록 FID가 증가한다. 균등 실험에서도 마찬가지지만, 상승 추세가 점진적이다. (그림의 해석에 대해서 자세히 나와있지가 않은데, 막대 그래프는 수집한 데이터셋에서 해당 특성을 가진 이미지의 수, 실선 그래프의 경우 각각의 세트로 훈련된 모델의 생성된 이미지에서 해당 특성을 가진 이미지들의 FID를 말하는 것 같다.)

의복 texture에서는 둘 다 plain을 제외하고 데이터의 양이 감소함에 따라 FID 꾸준히 증가하며, 유의미한 차이는 나지 않는 것 같다. Long-tail의 plain의 FID가 낮고 plaid가 높은 것은 그냥 절대적인 데이터 수의 많고 적음에 따른 것이라고 추론한다.(근데 그렇게 치면 얼굴 방향에서의 차이도 그냥 균등 세트에서 얼굴 각이 큰 이미지가 많기 때문 아닌가?)
일반적으로 판별기는 분포의 꼬리에서 제대로 샘플링되지 않은 이미지를 overfit하는 경향이 있다. 결과적으로 long-tail 데이터셋에서 "꼬리"에 해당하는 이미지는 거의 생성되지 않으며 균등한 분포는 이 문제를 부분적으로 완화시킨다는 것을 알 수 있다. (여기서 궁금한게 만약에 long-tail의 꼬리부분도 4만개 이상인 엄청 큰 데이터셋이라면 꼬리에 해당하는 특성을 가진 이미지의 '품질'에는 전혀 문제가 없는 것인가?)
Data Alignment
SHHQ에서 50K 이미지를 무작위로 샘플링하고 다음과 같이 얼굴, 골반, 몸의 중간지점을 중심으로 정렬한다. 중간지점 정렬의 경우, 신체비율이 사람마다 다르므로 segmentation mask를 사용하여 몸의 평균좌표를 찾는다.

세 정렬 실험의 FID는 각각 3.5, 2.8, 2.4이다. 중간지점 정렬이 가장 효과적이라는 것을 알 수 있다.
Experimental Insights
정리하자면
- 40K개 이상의 이미지가 있는 대규모 데이터 세트는 512×256 및 1024×512 해상도 모두에서 높은 충실도의 무조건적인 인간 생성 모델을 훈련하는 데 도움이 된다.
- 얼굴 회전 각도의 균등한 분포는 얼굴의 합리적인 품질을 유지하면서 희귀한 얼굴의 FID를 줄이는 데 도움이 된다. 그러나 단순히 옷감 분포의 균형을 잡는다고 해서 생성 품질이 효과적으로 향상되는 것은 아니다.
- 인체 전체를 중심으로 정렬하면 얼굴이나 골반 중심으로 정렬하는 것보다 질적으로 향상된다.
Model Zoo and Editing Benchmark
Model Zoo
앞으로의 다양한 과제 탐구에 기여하기 위해 SHHQ로 두 가지의 해상도에 대해 사전 교육된 StyleGAN1,2,3 총 6개의 모델을 배포한다. 다음 그림은 style mixing 예제이다.

Editing Benchmark
여러가지 편집 기능을 가진 InterFaceGAN, StyleSpace, SeFa 와 같은 몇 가지 편집 기술을 활용한다. 이미지를 편집하기 전에 PTI를 이용하여 사전 훈련 모델을 반전시킨다.

속성 조작의 경우, StyleSpace는 조작 대상 영역만 변경함으로써 나머지보다 더 나은 disentanglement를 표현한다. 그러나 편집한 영역의 사실성에 대해서는 InterFaceGAN이 더 뛰어나다.
InsetGAN은 별도의 GAN 모델에서 생성된 얼굴과 몸을 융합하는 다중 GAN 최적화 방법을 제안한다.
본 연구에서는 FFHQ에서 생성된 얼굴과 SHHQ에서 생성된 몸 각각에 대한 잠재코드를 반복적으로 최적화하여 InsetGAN의 프로세스를 다시 구현한다. 아래는 각각의 얼굴과 몸을 혼합한 예제이다.

Conclusion
본 연구는 주로 데이터 중심적 관점에서 photo-realistic 이미지를 생성하기 위해 무조건적인 인간 기반 GAN 모델을 훈련시키는 방법을 조사한다. SHHQ 데이터 세트를 활용하여 커뮤니티가 가장 관심을 갖는 세 가지 기본적이면서도 중요한 문제, 즉 데이터 크기, 데이터 분포 및 정렬을 분석한다. 스타일을 실험하는 동안 GAN과 대규모 데이터를 통해 몇 가지 경험적 통찰력을 얻는다. 이 외에도 6개의 모델로 구성된 model zoo를 만들고, 몇 가지 최첨단 얼굴 편집 방법을 사용하여 효과를 입증한다.
'논문 리뷰 > etc.' 카테고리의 다른 글
| Can CNNs Be More Robust Than Transformers? 논문 리뷰 (0) | 2022.06.10 |
|---|---|
| When does dough become a bagel? Analyzing the remaining mistakes on ImageNet 논문 리뷰 (1) | 2022.05.22 |
| Thin-Plate Spline Motion Model for Image Animation (TPS) 논문 리뷰 (0) | 2022.05.11 |
| Neural 3D Scene Reconstruction with the Manhattan-world Assumption 논문 리뷰 (1) | 2022.05.08 |
| Focal Sparse Convolutional Networks(FocalsConv) 논문 리뷰 (0) | 2022.05.01 |
| Masked Siamese Networks 논문 리뷰 (0) | 2022.04.20 |



