5월 9일 공개된 When does dough become a bagel? Analyzing the remaining mistakes on ImageNet 논문은 ImageNet의 오류를 분석한 논문이다.
(다 쓰고 보니까 mistake와 error가 거의 구분이 없는데, 논문에서도 딱히 기준은 없는지 너무 중구난방으로 써서 잘 모르겠고, 대부분은 논문의 표기를 따랐음.)
Abstract
컴퓨터 비전에서 가장 많이 벤치마킹된 데이터 세트 중 하나인 ImageNet에서 오류의 long-tail에 대한 통찰력을 제공하기 위해 일부 상위 모델이 저지르는 실수를 수동으로 검토하고 분류한다. 본 연구에서는 ImageNet의 multi-label 하위 집합 평가에 중점을 두는데, 여기서 SOTA 모델은 97% 이상의 정확도를 달성한다. 분석으로 추정된 실수의 거의 절반이 전혀 실수가 아니라는 것을 밝히고, 신중한 검토 없이 이러한 모델의 성능을 크게 과소평가하고 있음을 입증하는 새로운 유효한 multi-label을 발견한다. 한편, 오늘날 최고의 모델은 여전히 인간 검토자에게는 명백히 잘못된 실수를 많이 범한다는 사실도 발견했다. 또한 업데이트된 multi-label 평가 세트를 제공하고 ImageNet-Major를 큐레이션 한다. ImageNet-Major는 상위 모델이 저지르는 명백한 실수를 68개의 예시로 나타낸 주요 오류이다.
Introduction
최상위 모델들이 저지르는 많은 실수들이 꽤 합리적이고 아마도 실수라고 여겨져서는 안 되는 것이다. 이러한 remaining mistake의 심각성과 유형을 이해하는 것은 미래에 도움이 될 수 있다.
따라서 본 연구에서는
- Remaining mistake 중 어떤 것이 심각한 오류로 남아있는지
- 어떤 오류 카테고리에 속할 수 있는지
- 남은 가장 중요한 long-tail failure를 포착할 수 있는 평가
를 더 잘 이해하기 위해 몇 가지 최신 모델의 remaining mistake를 분석하려고 시도한다.
본 연구에서는 ImageNet multi-label validation subset을 분석한다. 또한 최신의 대형 ImageNet 모델의 실수를 분석하여 다음과 같은 사실을 발견했다.
- 각 모델의 실수의 거의 절반은 전문적인 multi-label 재평가 하에서 정확하다고 간주되어 오류율이 절반으로 감소하였다.
- Remaining mistake의 약 40%는 '주요' 실수로 분류될 수 있는데, 이는 대부분의 인간이 저지르지 않을 것 같은 실수의 많은 부분이 단순히 long-tail 실수가 아니라 개선의 여지를 남기는 합법적인 실수라는 것을 암시한다.
- 사소한 오류는 대부분 long-tail 오류 유형이지만, 사소한 실수가 아닌 부분은 가짜 상관 관계이거나 비전형적인 실측 자료 클래스 표현에서 비롯된다는 것을 보여준다.
분석을 기반으로, 68개의 multi-label 예제 평가 세트인 ImageNet-M을 제안한다.
Mistake analysis method and taxonomy
실수의 수를 측정하기 위해, ImageNet-1k에서 89.5%의 정확도, ImageNet2012_multi-label에서 96.3%의 MLA(multi-label accuracy)를 달성한 ViT-3B를 활용했다.
ImageNet2012_multi-label 에서 모델은 총 676개의 명백한 실수를 저질렀으며, 이를 수동으로 자세히 검토했다.
Panel Review
5명의 전문가 패널 구성. 패널들은 모든 실수에 대해 다음을 고려했다.
- 모델이 실수를 했는가?
- 실측 주석이 정확했는가?
- 실수의 범주 유형과 심각도는 무엇인가?
'미사일', '발사체 미사일'과 같은 중복적인 클래스를 축소했다. 또한, 구글 이미지 검색을 활용하여 context를 제공했다. 예를 들어, 노란색인 것을 제외하면 명백한 택시 표시가 없는 택시 이미지가 있었는데, 구글 검색을 이용하여 표준 차량이 아닌 택시로 예측을 결정했다.
패널 재검토 후, 140개의 이미지가 옳다고 여겨졌고, 536개의 실수가 남았다.
Mistake category and severity
심각도 수준을 두 가지로 분류했다.
- Major : 인간이 분명히 틀렸다는 것을 발견할 수 있음
- Minor : 주요한 실수보다 미묘하며, 일부는 전문가들 조차도 논쟁할 수 있음

또한 4가지의 실수 유형을 공식화했다.
- Fine-grained Error : 예측과 GT(ground truth)가 유사함
- Fine-grained with Out-of-Vocabulary (OOV) : ImageNet의 예측 클래스는 이미지에 없지만 ImageNet에 없는 유사한 개체가 있음
- Spurious Correlation : 예측된 물체가 이미지에 타당하지 않지만 주변 단서가 사용되었거나, 이미지의 context를 놓침
- Non-prototypical : 예측은 틀렸지만 GT와 예측 레이블이 유사함

하지만 모든 실수가 반드시 4개의 유형에 완벽하게 들어맞는 것은 아니며, context의 판단이 주관적이기 때문에 일부는 다른 빈(bin)에 빠질 수 있다.
Analyzing the remaining mistakes
Label 재지정 후 초기 실수의 44%가 정확한 예측으로 판단되었다.

Mistake categorization and severity
남은 378개의 실수를 카테고리별, 심각도별로 분류.

대부분이 Fine-grained 실수 유형에 속한다.
다음은 혼동되는 클래스 쌍의 발생 빈도이다. 가장 많이 혼동된 두 개의 클래스 쌍은 (아메리카 카멜레온, 녹색 도마뱀), (마다가스카르 고양이, 인드리)이다.
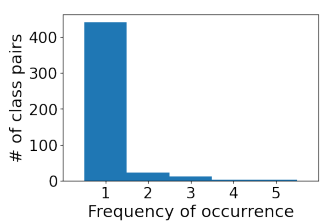
클래스 혼동의 long-tail은 소수의 클래스에만 데이터를 정리하거나 추가해도 모델 오류의 많은 부분을 해결할 수 없음을 시사한다. (적은 수의 혼동이 대부분을 차지하기 때문.)
Out-of-distribution generalization
ImageNetV2에서도 100개의 실수를 샘플링하여 동일한 재검토를 실행했는데, 47개가 재검토 후 정확한 예측으로 판단되었다. ImageNetV1와 거의 차이가 없다. 이러한 비율은 모델이 새로운 올바른 multi-label을 자주 발견하고 있음을 시사하며, 벤치마크 포화 상태로서 성능을 제대로 평가하기 위해서는 실수 분석과 label 수정이 벤치마크 개발의 lifecycle과 유지보수의 일부가 되어야 함을 시사한다.

Generalization to new models
모델의 정확도를 높였을 때 실수 유형 변화를 관찰하기 위해 Greedy Soups 모델을 이용하여 341개의 오류를 산출했다. 하지만 유의미한 차이는 없었음.

Comparison to humans
인간 labeler의 예측은 label 재검토 후에도 크게 달라지지 않았다. 전체적인 분류 성적은 모델 쪽이 더 낫지만, 인간은 유기체가 아닌 객체를 훨씬 더 잘 예측했다.

Analyzing the Training Data
최근접이웃을 이용 하여 검증 세트에서의 실수와 가장 가까운 예를 훈련 세트에서 찾아본다.
검증 세트의 797개의 이미지가 정확히 똑같이(L2거리 0) 훈련 세트에 존재했고, 이들 중 34개는 두 번 이상 중복 존재했다. 이 점은 이미 다른 논문에서 주목했지만, 새로 발견한 흥미로운 점은 같은 두 이미지 쌍이 모두 다른 label을 가지고 있었다는 것이다. 이는 제작자가 클래스 내의 중복은 제거했지만 다른 클래스 간의 중복은 제거하지 않았음을 시사한다.


Fine-grained 오류는 인간에게는 직관적이지만, 가짜 상관관계 오류는 인간에게도 이해하기 어려울 때가 많다. 다음 그림은 가짜 상관관계의 몇 가지 예시이다.

Recommendations and Discussion
ImageNet-M: A "major mistakes" evaluation split
오류를 개선하기 위해 100% 정확도가 달성 가능하다고 믿는 벤치마크를 원한다. 사소한 실수는 주요 실수보다 해석과 논의의 대상이 되기 때문에, 후자에 초점을 맞춘 벤치마크가 ImageNet에서 의미 있는 개선이 무엇인지 커뮤니티가 판단하는 데 도움이 될 것이라고 믿는다.
이를 위해 전문가가 검토한 ImageNet multi-label set slice를 생성한다. 여기서
- SOTA 모델은 여전히 틀리고
- 인간에게는 명백하다
이 slice를 ImageNet-Major라고 이름 붙였다.
ViT-3B의 155개의 주요 실수 중, 다른 모델 3개(instagram 사전훈련, 제로 샷, greedy soup)를 추가한 4개의 모델 제품군에서 3개 이상의 모델이 실수를 범한 68개의 주요 실수로 하위 집합을 구성했다.
ImageNet-M은 다음과 같은 특성을 가지는 검증 세트의 하위 집합이다.
- 대다수의 최고 성능 모델이 실수를 함
- 그 실수는 주요한(Major) 실수임
- 세트는 수동 검사가 가능할 만큼 충분히 작음
- ImageNet label set에 대해 포괄적으로 labeling 되도록 고려함
- 이론적으로 100% 정확도를 달성할 수 있음
70개의 모델에 대해 ImageNet-M에서의 성능을 평가했다.

대부분의 모델은 10~25개의 예제를 맞히지만, ViT-G/14, BASIC-FT, CoCa-FT 등의 최신 모델은 이러한 주요 실수를 꽤 많이 해결하고 있다. 그중 CoCa-FT는 68개 중 42개를 맞혔다.
더 강력한 모델이 주요 오류를 먼저 해결하고 있다는 통계적 증거를 발견하지는 못했으며, 앞으로 더 많은 연구와 보고가 필요하다.
Limitations of Analysis
본 연구의 한계점은 ViT-3B와 greedy soup 모델의 주요 실수에 대해서만 검토했다는 것, 전문가 패널과 구글 이미지 검색 등 주관적인 편향이 개입되었을 수 있다는 것이다.
Conclusion
ViT-3B 및 Greedy Soups 모델이 ImageNet multi-label 검증 세트에서 저지르는 나머지 모든 실수를 분석하였다.
주요한 실수의 범주와 심각도에서 명백한 패턴은 없었으며, 오늘날 SOTA 모델은 multi-labeling에서 인간과 비슷하거나 능가한다. 또한 모델의 주요한 실수를 해결하는 능력을 평가하는 ImageNet-M을 출시한다.
'논문 리뷰 > etc.' 카테고리의 다른 글
| More ConvNets in the 2020s : Scaling up Kernels Beyond 51 × 51 using Sparsity 논문 리뷰 (0) | 2022.07.13 |
|---|---|
| The ArtBench Dataset (0) | 2022.06.26 |
| Can CNNs Be More Robust Than Transformers? 논문 리뷰 (0) | 2022.06.10 |
| Thin-Plate Spline Motion Model for Image Animation (TPS) 논문 리뷰 (0) | 2022.05.11 |
| Neural 3D Scene Reconstruction with the Manhattan-world Assumption 논문 리뷰 (1) | 2022.05.08 |
| StyleGAN-Human 논문 리뷰 (0) | 2022.05.03 |



