3월 27일 공개된 Thin-Plate Spline Motion Model for Image Animation


Abstract
최근의 연구는 사전 지식을 사용하지 않고 비지도 방법을 통해 임의의 개체에 대해 모션 전송을 수행하려고 시도한다. 그러나 소스와 주행(=driving) 이미지의 객체 사이에 큰 포즈 간격이 있을 때의 비지도 방법은 현재 여전히 중요한 과제로 남아 있다. 본 논문에서는 이러한 문제를 극복하기 위해 새로운 end-to-end 비지도 모션 전송 프레임워크를 제안한다.
- 보다 유연한 optical flow를 생성하기 위해 thin-plate spline 모션 추정을 제안하는데, 이는 소스 이미지의 feature 맵을 주행 이미지의 feature 도메인으로 왜곡시킨다.
- 누락된 영역을 보다 현실적으로 복원하기 위해 다중 해상도 폐색 마스크를 활용하여 보다 효과적인 feature 융합을 달성한다.
- 추가적인 보조 손실함수는 네트워크 모듈에 명확한 분업이 있도록 설계되어 네트워크가 고품질 이미지를 생성하도록 장려한다.
본 논문의 방법은 말하는 얼굴, 인체, 픽셀 애니메이션을 포함한 다양한 물체를 애니메이션으로 만들 수 있다. 실험은 이 방법이 동작 관련 메트릭의 가시적인 개선을 통해 대부분의 벤치마크에서 SOTA보다 더 나은 성능을 발휘한다는 것을 보여준다.

Introduction

지금까지 3D 모델, 랜드마크, 도메인 레이블과 같은 객체에 대한 사전 지식을 사용하여 모션 전달에 대한 많은 연구가 수행되었다. 그러나 레이블이 지정된 데이터에 의존하는 이러한 접근법은 얼굴과 인체와 같은 특정 객체에만 적용되며 비용도 많이 든다.
최근, 사전 지식이 필요하지 않은 일부 비지도 모션 전송 방법이 제안되었다. 이러한 방법은 훈련을 위해 비디오에서 샘플링된 두 개의 프레임을 사용하며, 여기서 한 프레임을 소스 이미지로 사용하여 다른 프레임을 주행 이미지로 재구성한다. 그리고 모션 표현을 학습하기 위해 재구성 손실을 사용하여 최적화된다. 일부 비지도 방법은 모션 전송을 두 단계로 나눈다.
- Optical flow는 소스 이미지의 feature 맵을 주행 이미지의 feature 도메인으로 왜곡하는 모션 표현을 사용하여 추정한다.
- 폐색 마스크는 뒤틀린 feature 맵의 누락된 영역을 표시하기 위해 예측되며, 이 영역은 네트워크에 그려진다.
실험에 따르면 비지도 방법은 다양한 객체에 대해 모션 전송을 수행할 수 있다.
그러나 비지도 방법에는 몇 가지 문제가 있다.
- 소스와 주행 이미지 객체 사이의 큰 포즈 간격을 학습하기 어렵다.
- 폐색 마스크의 면적이 증가하여 모션 전송이 네트워크의 인페인팅 기능에 너무 의존하게 되며, 이는 네트워크의 부적절한 인페인팅 능력으로 이어진다.
또 다른 일부 비지도 방법은 움직임을 추정하기 위해 local affine 변환을 결합하여 품질을 향상시킨다. 그러나 affine 변환은 선형적이어서 복잡한 움직임을 표현하기 어렵다. 이를 극복하기 위해 보다 유연한 비선형 변환, thin-plate spline(TPS) 변환을 도입하여 모션을 근사하고 새로운 end-to-end 비지도 모션 전송 프레임워크를 제안한다.
- 먼저, TPS 변환을 생성하기 위한 몇 가지 키포인트 세트를 예측하고 affine 배경 변환과 결합하여 optical flow를 추정한다. 또한, 각 TPS 변환이 추정된 optical flow에 기여하도록 훈련 초기 단계에서 여러 TPS 변환에 대해 드롭아웃을 수행한다.
- 휘어진 feature 맵의 각 레이어에 대한 폐색 마스크를 예측하여 feature 맵이 보다 효율적인 feature 융합을 위해 다른 초점을 갖도록 한다.
- 각 모듈이 더 명확한 분업을 갖도록 보조 손실함수를 설계하여 네트워크가 고품질 이미지를 생성하도록 장려한다. 제안된 프레임워크는 모션을 더 정확하게 근사하고 인페인팅 기능이 더 강하다.
Related Work
Monkey-Net : 여러 쌍의 비지도 키포인트 쌍을 예측하여 애니메이션을 위한 optical flow를 추정한다.
FOMM : Monkey-net을 기반으로 각 키포인트 근처에서 테일러 확장과 local affine 변환을 사용하여 품질을 크게 향상시킨다.
MRAA : 주성분 분석(PCA) 기반 모션 추정을 사용하여 관절 모션을 표현하는 데 더 나은 품질을 가지고 있다. 또한 카메라 모션의 부정적인 영향을 없애기 위해 배경 모션 추정을 추가한다.
Method

모델은 소스 이미지 S와 주행 이미지 D를 받아 재구성된 주행 이미지 D̂을 생성하며, 다음의 모듈로 구성된다.
- Keypoint Detector : Keypoint detector Ekp는 S와 D를 받아 K x N의 키포인트 쌍을 예측하여 K 개의 TPS 변환을 생성한다.
- BG Motion Predictor : Ebg는 S와 D를 받아 affine 배경 변환의 매개변수를 추정한다.
- Dense Motion Network : K개의 TPS 변환과 하나의 affine 변환을 받아 optical flow를 추정. 동시에, 다중 해상도 폐색 마스크를 사용하여 feature 맵의 누락된 영역을 나타낸다.
- Inpainting Network : Optical flow와 소스 이미지를 이용해 최종결과 출력.
TPS Motion Estimation
T(S) = D가 되도록 T를 근사화 하는 것을 목표로 한다.
TPS 변환은 local affine 보다 복잡한 움직임을 표현할 수 있는 유연한 비선형 변환이다. 두 이미지에서 키포인트가 주어지면 TPS 변환 Ttps를 사용하여 왜곡을 최소화 하면서 모션을 전송(=warp)할 수 있다.
아래의 식은 optical flow 추정에서 이동 전의 픽셀과 이동 후의 픽셀의 값이 같다는 밝기 항상성 식인데, 간단히 말하자면 S의 키포인트를 식 T로 왜곡한 후의 값이 D의 키포인트와 같아야 한다는 뜻이다. (더 자세하게 이해하고 싶다면 optical flow 알아보기 참조. 진짜 감탄이 나올 정도로 정말정말 쉽게 정리해 놓았다.)
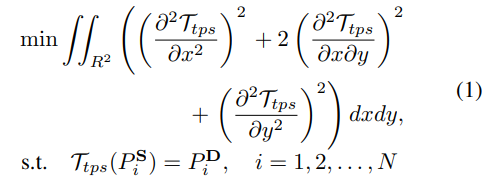
Pix 는 이미지 X의 키 포인트. N개의 키포인트 쌍 -> 1개의 TPS 변환 (총 K개의 TPS 변환, K x N 개의 키포인트 쌍)
픽셀 p에서 k번째 TPS 변환은 다음과 같이 구해진다.

p는 픽셀 좌표 (x,y)T,
Ak ∈ R2 x 3그리고 wki ∈ R2 x 1은 등식 (1)을 풀어서 얻은 TPS 계수이고,
U(r)는 방사형 기반의 함수이며, 이는 위치 p에서의 각 키포인트의 영향을 나타낸다.

또한 카메라의 움직임은 모션 추정의 큰 편차를 초래하기 때문에 배경 움직임을 모델링 하기 위한 affine 배경 변환을 예측한다.

Abg는 Ebg에 의해 예측된 affine 변환 행렬이다.
그런 다음 K+1개의 매핑 T로 S를 cascade(순차 적용)하고 Dense Motion Network의 입력으로 사용한다(순차 적용된 각각의 i 번째 이미지들을 다 넘기는 듯?). Dense Motion Network에서는 K+1개의 기여 맵 M̃k를 예측하고 softmax를 통해 모든 기여 맵의 같은 픽셀위치 p에서의 합이 1이 되도록 한다.

그리고 최종적인 optical flow 계산

Optical flow T̃를 Inpainting Network의 입력으로 사용한다.
훈련 과정에서 몇몇 기여맵만 결과에 반영되고 일부 기여맵의 영향이 0에 수렴할 수 있으므로 드롭아웃을 적용한다.
그리고 드롭아웃 되지 않는 기여 맵의 기대치가 일정하게 유지되도록 다음을 적용한다.

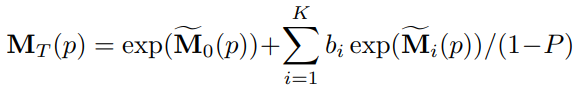
Multi-resolution Occlusion Masks
Dense Motion Network와 Inpainting Network의 경우, 모래시계 아키텍처(인코더-디코더 구조)를 사용하여 다양한 규모의 feature를 융합하며, 이는 다양한 작업에서 효과적이라는 것이 입증되었다. FOMM, MRAA에서와 마찬가지로 폐색 마스크를 사용하지만 그들과 다른 점은 각 레이어의 feature 맵 마다 서로 다른 폐색 마스크를 사용한다. 이는 각 레이어마다 feature 맵에서 중요하게 보는 것이 다르기 때문이다.
Dense Motion Network에서 레이어마다 추가적으로 컨볼루션을 사용하여 다중해상도 폐색 마스크를 예측하고, optical flow와 폐색 마스크를 Inpainting Network에 공급한다.
Inpainting Network의 자세한 구조는 다음과 같다.

Training Losses
FOMM과 MRAA에서와 같이, 미리 훈련된 VGG-19 네트워크를 이용하여 다양한 해상도에서 생성된 이미지와 주행 이미지 간의 reconstruction loss를 계산한다.

i는 VGG-19의 i번째 레이어, j는 다양한 해상도.
다음은 equivariance loss

임의의 변형 T에 대해 적용 순서를 바꿔도 같은 키포인트를 추출할 수 있어야 한다.

또한 모듈에 대한 보조 손실함수로 bg loss, warp loss를 사용한다.
BG Motion Predictor를 사용하여 S->D 변환 Abg, D->S 변환 A'bg를 구하고, 두 행렬이 일관성을 유지하도록 한다.

하지만 두 행렬이 0으로 되는 것을 방지하기 위해서 다음과 같이 바꾼다.

I는 3x3 단위행렬.
Inpainting Network의 인코더에 D를 공급하고 비교한다.

Ei는 인코더 네트워크의 i번째 레이어를 의미한다.
Optical flow를 반영한 S와 D를 비교하여 네트워크가 opitcal flow를 더욱 합리적으로 추론할 수 있게 한다.
최종 손실함수 L은

Testing Stage
테스트 단계에서 소스 이미지 S와 주행 비디오 {Dt}(t=1,2,...,T)를 사용.
FOMM에는 표준과 상대 모드가 있다. 표준 모드는 Dt와 S를 사용하여 추론, 상대 모드는 Dt와 D1 사이의 움직임을 추정하여 S에 적용한다. 정체성 간의 큰 불일치가 있을 때 표준모드는 잘 작동하지 않으며, 상대 모드는 D1과 S의 포즈가 비슷해야 한다.
MRAA는 S에 적용해야 할 움직임을 예측하기 위해 추가로 훈련된 네트워크를 사용하는 새로운 모드를 제안하며, 본 논문에서도 동일한 모드를 사용한다.
MRAA에서와 같이, 형상과 포즈 인코더를 훈련한다. 형상 인코더는 S의, 포즈 인코더는 Dt의 키포인트를 학습한다. 그런 다음 디코더는 S의 형상과 Dt의 포즈를 보존하면서 키포인트를 재구성한다.
비디오에서 두 프레임의 키포인트를 사용하여 네트워크를 훈련하는데, 한 프레임의 키포인트는 다른 ID의 포즈를 시뮬레이션하기 위해 무작위로 변형된다. 네트워크가 변형되기 전의 키포인트를 재구성하도록 권장하는 데 L1 손실이 사용된다. 애니메이션을 위해 형상과 포즈 인코더로 얻은 키포인트를 optical flow 등식을 사용하여 추정한다.
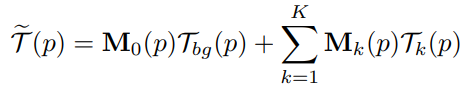
Discussion and Conclusion
TPS 모션 추정 제안, 다중 해상도 폐색 마스크 제안, 보조 손실 함수 설계.
대부분의 벤치마크에서 SOTA 성능을 달성했지만 아직 정체성 차이가 큰 도메인간의 모션 전송은 도전으로 남아있다.
Experiments
Benchmarks
Dataset : VoxCeleb, Taichi HD, TED-talks, MGif
첫 번째 프레임인 D1을 소스로 하여 품질 평가.
L1 : 생성된 비디오와 주행 비디오 사이의 L1 거리
Average keypoint distance (AKD) : 사전 훈련된 검출기를 사용하여 생성된 비디오의 키포인트와 주행 비디오의 키포인트 사이의 거리
Missing keypoint rate (MKR) : 주행 이미지에는 존재하지만 생성된 이미지에는 누락되어있는 키포인트의 비율
Average Euclidean distance (AED) : 생성된 이미지와 주행 이미지에서 ID 추출, ID 쌍에 대한 L2 거리 계산
Comparison
비디오 재건에 대한 비교

비디오 재건에서 MRAA과의 품질 비교

본 논문의 모델이 더 나은 시간 연속성을 갖고 있다. MRAA에서는 엄지손가락이 생겼다가 없어졌다가 한다.

본 논문의 모델이 인체에 대해서는 모션 전송이 더 우수하지만 옷과 얼굴 같은 세부정보를 유지하는 데는 약간 떨어진다고 한다. (근데 그냥 보면 세부정보 차이는 잘 모르겠고 딱봐도 TPS 모델이 더 좋아보임.)

사람들에게 설문한 결과 대다수의 사람들이 연속성과 신뢰성에서 MRAA 보다 더 높게 평가했다.
(%는 MRAA보다 본 논문의 방법을 높게 평가한 사람들의 비율)

Ablations

다중해상도 마스크는 L1과 AED는 개선되지만 키포인트 관련 메트릭에서는 손해를 불러왔다.

비슷한 치수의 매개변수에서 더 나은 성능을 보여줌

'논문 리뷰 > etc.' 카테고리의 다른 글
| The ArtBench Dataset (0) | 2022.06.26 |
|---|---|
| Can CNNs Be More Robust Than Transformers? 논문 리뷰 (0) | 2022.06.10 |
| When does dough become a bagel? Analyzing the remaining mistakes on ImageNet 논문 리뷰 (1) | 2022.05.22 |
| Neural 3D Scene Reconstruction with the Manhattan-world Assumption 논문 리뷰 (1) | 2022.05.08 |
| StyleGAN-Human 논문 리뷰 (0) | 2022.05.03 |
| Focal Sparse Convolutional Networks(FocalsConv) 논문 리뷰 (0) | 2022.05.01 |



