커널 분해와 동적 희소 컨볼루션을 이용해 커널 크기를 51x51까지 확장

Abstract
ViT의 발전에 맞서 최근의 몇 가지 컨볼루션 모델은 큰 커널로 반격하여 매력적인 성능과 효율성을 보여준다. 그들 중 하나인 RepLKNet은 커널 크기를 31x31까지 확장했지만, Swin Transformer와 같은 고급 ViT의 확장 추세에 비하면 성능이 포화된다. 본 논문에서는 그보다 더 큰 극한 컨볼루션 훈련을 테스트한다. 희소성을 이용해 커널을 51x51까지 확장한 순수 CNN 아키텍처인 Sparse Large Kernel Network(SLaK)를 제안한다.
Introduction
ViT에서 영감을 받아, 일부 최근 연구는 CNN에 큰 커널을 도입했지만 큰 커널은 학습하기가 매우 어렵다.
본 논문에서는 인간 시각 시스템에서 일반적으로 관찰되는 희소성을 탐구하여 이 연구 질문에 답하려고 한다.
본 논문의 주요 관찰
- 기존의 방법으로는 커널 크기를 31×31 이상으로 확장할 수 없다.
- 하나의 MxM 커널을 두 개의 직사각형 병렬 커널(MxN, NxM)로 대체하여 커널 크기를 61x61까지 확장할 수 있다.
이러한 관찰을 바탕으로 Sparse Large Kernel Network(SLaK) 제안.
Recipe for Applying Extremely Large Kernels beyond 31×31
ConvNeXt를 벤치마크로 극한 커널 크기를 시험한다.
Existing techniques fail to scale convolutions beyond 31×31
(Naive = 일반적인 커널 확장, RepLKNet = 해당 훈련 레시피 사용)

RepLKNet의 방법을 사용하면 31x31까지 성능이 저하되지 않지만 그 이상에서는 포화된다.
한 가지 가설은 큰 커널이 locality를 유지하지 못한다는 것이다. 일반적인 ImageNet 크기(224x224)에 다운샘플링까지 되면 매우 큰 커널은 global에 더 가깝다.
Decomposing a square large kernel into two rectangular, parallel kernels smoothly scales the kernel size up to 61
하나의 큰 커널을 두 개의 직사각형 커널로 분해한다.

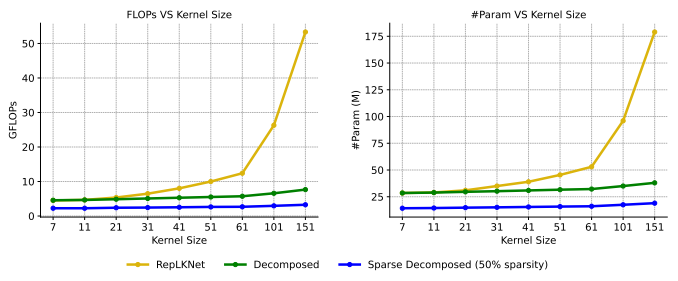
이 방법으로 선형적인 오버헤드와 큰 커널에서의 성능 향상을 얻을 수 있다.
“Use sparse groups, expand more” significantly boosts the model capacity.
먼저 고밀도 컨볼루션을 동적 희소성을 가진 희소 컨볼루션으로 대체한다. 동적 희소 컨볼루션은 훈련 중에 낮은 가중치를 가지치기하고 가중치를 무작위로 증가시키는 등 동적 적응이 가능해 local feature가 향상된다.
위의 표와 같이 희소 컨볼루션을 사용하면 조금의 정확도를 희생하고 FLOPs가 크게 향상된다. 또한 향상된 높은 효율로 모델을 확장할 수 있고, 고밀도 컨볼루션 사용 모델보다 더 높은 성능을 달성한다.
Sparse Large Kernel Network - SLaK
ConvNeXt 아키텍처를 기반으로 동적 희소 컨볼루션과 커널 분해를 적용한 SLaK을 소개한다.

ConvNeXt의 커널 크기를 [51, 49, 47, 13]으로 늘리고 분해 커널 직후 배치 정규화를 통해 출력을 요약하는 것이 중요하다.
희소 비율과 모델 확장 폭을 조절하여 다양하게 커스텀할 수 있다.
51x51의 극한 크기의 커널을 사용하지만, 오버헤드가 거의 없고 성능도 좋다.
Evaluation of SLaK
Classification accuracy on ImageNet-1K

Semantic segmentation on ADE20K

Object detection on PASCAL VOC 2007

Analysis of SLaK
수용 필드

기여도가 높은 면적비로 수용 필드에 대한 정량적 분석

계산 효율성

희소 비율과 모델 확장의 trade-off




