CVPR 2022에서 발표된 논문 Focal Sparse Convolutional Networks for 3D Object Detection

Abstract
Point cloud나 voxel과 같은 불균일한 3D 희소 데이터는 다양한 방식으로 3D 객체 감지에 기여한다. Sparse convolutional networks (Sparse CNNs)의 기존 기본 구성 요소는 일반 또는 부분 다양체 희소 합성곱에 관계없이 모든 희소 데이터를 처리한다. 본 논문에서는 Sparse CNN의 기능을 향상시키기 위해 위치별 중요도 예측으로 feature 희소성을 학습 가능하게 만드는 것을 기반으로 하는 2개의 새로운 모듈을 소개한다. 그것은 focal sparse convolution (Focals Conv)과 focal sparse convolution with fusion의 multi-modal 변형(Focals Conv-F)이다. 새로운 모듈은 기존 Sparse CNN의 일반 모듈을 쉽게 대체할 수 있으며 end-to-end 방식으로 공동으로 훈련될 수 있다. 처음으로, 논문에서는 희소 합성곱에서 공간적으로 학습 가능한 희소성이 정교한 3D 객체 감지에 필수적임을 보여준다. KITTI, nuScenes 및 Waymo 벤치마크에 대한 광범위한 실험은 본 논문에서의 접근 방식의 효율성을 검증한다. 추가적인 기능 없이 결과는 nuScenes 테스트 벤치마크에서 기존의 모든 단일 모델 항목을 능가한다.
Introduction
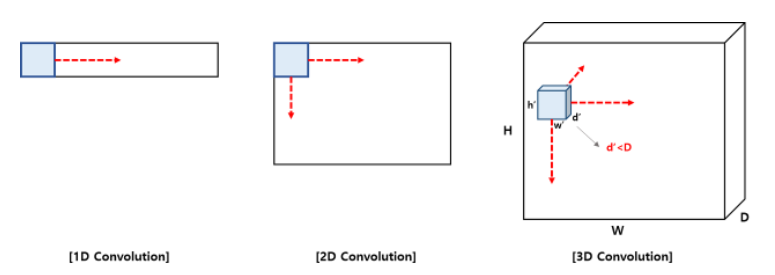
3D 객체 탐지의 핵심 과제는 point cloud와 같은 구조화되지 않은 희소 3D 기하학적 데이터에서 효과적인 표현을 배우는 것이다. 일반적으로 2가지 방법이 있다.
- PointNet++를 통해 직접 처리한다. 그러나 시간이 많이 걸리기 때문에 실시간 효율성이 요구되는 대규모 자율주행 장면 등에는 부적절하다.
- Point cloud를 복셀화하고 feature 추출을 위해 3D sparse CNN을 적용한다. 일반적으로 regular 및 submanifold 희소 컨볼루션으로 구성된다. 각각의 희소 컨볼루션은 널리 사용되지만 한계가 있다.
Regular 희소 컨볼루션은 모든 희소 feature를 확장하기 때문에 상당한 연산량이 불가피하다. 또한 detector는 물체를 배경 feature와 구분하는 것을 목표로 하는데 regular 희소 컨볼루션은 희소성을 감소시키기 때문에 특징적인 차이를 흐리게 한다. 반면 submanifold 희소 컨볼루션은 출력 feature 위치를 제한하여 계산 문제를 피하지만 feature의 필수적인 정보 흐름을 놓칠 수 있다.
이러한 제한은 모든 입력 feature를 동일하게 처리하는 기존의 컨볼루션 패턴에서 비롯된다. 2D에서 동일한 계층의 모든 픽셀은 일반적으로 수용 가능한 필드 크기를 공유한다. 그러나 3D 희소 데이터는 공간에서 다양한 희소성과 중요성을 가지고 있다. 균일하지 않은 데이터를 균일하게 처리하는 것은 최적이 아니다.
본 논문에서는 regular 및 submanifold 간의 개념 차이를 완화하여 희소 컨볼루션의 일반적인 형식을 제안하며 3D 객체 탐지를 위해 sparse CNN의 표현 용량을 향상시키는 두 가지 새로운 모듈을 소개한다.
- Focal sparse convolution (Focals Conv). 이것은 컨볼루션의 출력 패턴에 대한 입방체 중요도 맵을 예측한다. 중요한 것으로 예측되는 feature들은 위 그림은 오른쪽과 같이 변형 가능한 출력 형상으로 확장된다. 중요도는 입력 feature에 따라 동적으로 조정되는 추가 컨볼루션 레이어를 통해 학습된다. 이 모듈은 모든 feature 중 중요한 정보의 비율을 높인다.
- Focal sparse convolution with fusion(Focals Conv-F)의 multi-modal 개선 버전. LIDAR 전용 Focals Conv에서, 일반적으로 이미지 feature들이 풍부한 외관 정보와 큰 수용 필드를 포함하기 때문에 RGB 기능을 융합하여 중요도 예측을 강화한다.
제안된 모듈은 두 가지 측면에서 새롭다.

- Focals Conv는 feature의 공간 희소성을 학습하기 위한 동적 메커니즘을 제시한다. 다운샘플링 작업을 통해 중요한 정보가 단계적으로 증가하는 한편, 많은 양의 배경 복셀이 제거된다.
- 두 모듈 모두 경량이다. 중요도 예측은 Focals Conv의 그림과 같이 적은 간접비 매개변수와 계산을 포함한다.
제안된 두 모듈은 희소 CNN에서 원래의 모듈을 쉽게 대체할 수 있다. 효과를 입증하기 위해 기존의 3D 객체 감지 프레임워크에 백본 네트워크를 구축한다. 이 방법은 KITTI와 nuScene 벤치마크 모두에서 적은 모델 복잡성 오버헤드로 사소한 향상을 가능하게 한다. 이러한 결과는 초점에서의 학습 가능한 희소성이 필수적이라는 것을 보여준다.
Related Work
Kernel shape adaption
커널 형상 적응 방법은 네트워크의 효과적인 수용 필드를 적응시킨다.
변형 가능한 컨볼루션은 형상 샘플링에 대한 오프셋을 예측한다. KPConv, MinkowskiNet 등이 있다.
Deformable PV-RCNN에서는 형상 샘플링 오프셋 예측을 3D 객체 감지에 적용했다.
Attention mask on input
Attention mask를 기반으로 중요하지 않은 픽셀을 제거한다. 이러한 방법은 고유 데이터 희소성을 활용하는 동시에 고밀도 데이터를 희소화하는 것을 목표로 한다.
LIDAR-only detectors
Completion-based detectors
Multi modal fusion
Multi-moadl 융합 방법은 LIDAR-only 방법보다 더 많은 정보를 사용한다. 주로 3D detector에 공급하기 전에 기성 2D 네트워크에서 이미지 feature를 추출하는 방법을 사용한다.
반면에 본 논문의 focals conv는 두 가지 측면에서 위의 방법과 다르다.
- 무거운 세분화 또는 감지 모델 대신 이미지 feature 추출을 위해 공동으로 훈련된 여러 레이어만 필요하다.
- 모든 LIDAR feature에 대해 균일한 decoration 대신 예측된 중요한 feature만 강화한다.
Focal Sparse Convolutional Networks
Review of Sparse Convolution
d 차원 공간 위치 p에 c 채널 수가 있는 feature xp가 주어지면 커널 가중치가 w ∈ RKd x cin x cout인 컨볼루션으로 처리한다. 예를 들어, 3차원 공간에서 w의 크기가 3일 때 ㅣKdㅣ = 33. 컨볼루션 과정은 다음과 같이 나타낼 수 있다.
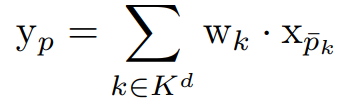
k는 공간 Kd의 각각의 모든 이산 좌표. p̄k(=p+k)는 위치 p와 p로부터의 오프셋 거리 k를 포함한 주변 공간을 뜻한다.
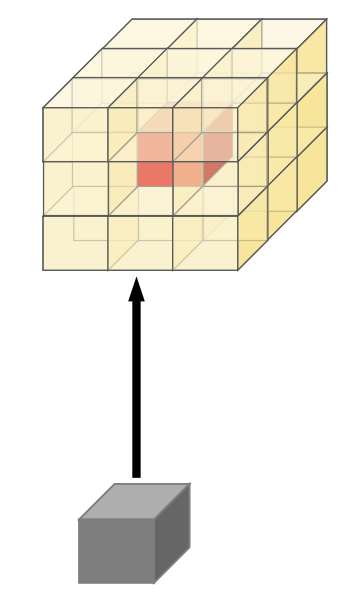
희소 입력 데이터의 경우 위치 p는 고밀도 이산형 공간 Z에 속하지 않기 때문에(모든 지점에 대해 컨볼루션을 수행하지 않는다. 값이 존재하는 부분의 근처에서만 수행한다.)

입력과 출력 feature 공간이 다음과 같이 Pin과 Pout으로 완화된다.
(Pin은 값이 존재하는 위치와 그 위치에 대한 오프셋 거리 내의 voxel들의 집합을 의미하는 듯.)
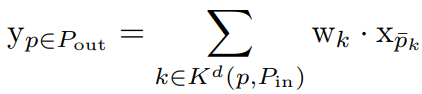
Kd(p, Pin)는 Kd의 부분집합이다.
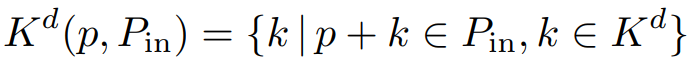
그리고 Pout이 Pin에 인접한 모든 공간을 포함한다면, Pout은 모든 p + k 들의 합집합이며 다음과 같이 나타낼 수 있다.
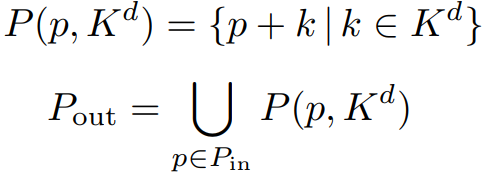
이 조건에서는 regular 희소 컨볼루션과 같으며, voxel이 커널 공간의 모든 위치 p에 작용한다.
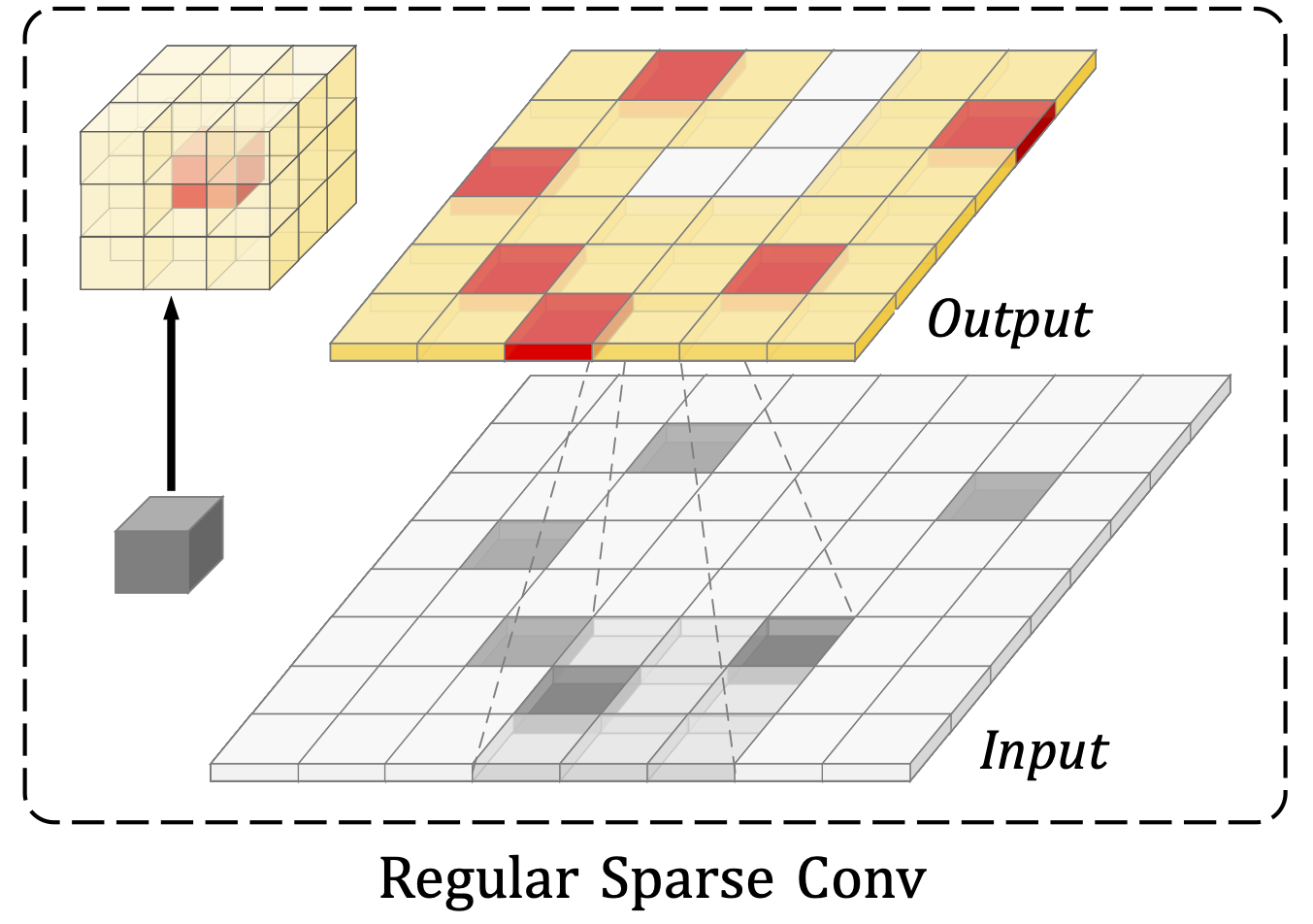
따라서 두 가지 단점이 생기는데,
- 상당한 계산 비용이 발생한다.
- 희소 feature가 지속적으로 증가하기 때문에 3D 객체 탐지에 좋지 못하다.
Pout=Pin 일 때는 submanifold 희소 컨볼루션과 같으며, 계산이 적지만 성능이 떨어진다.
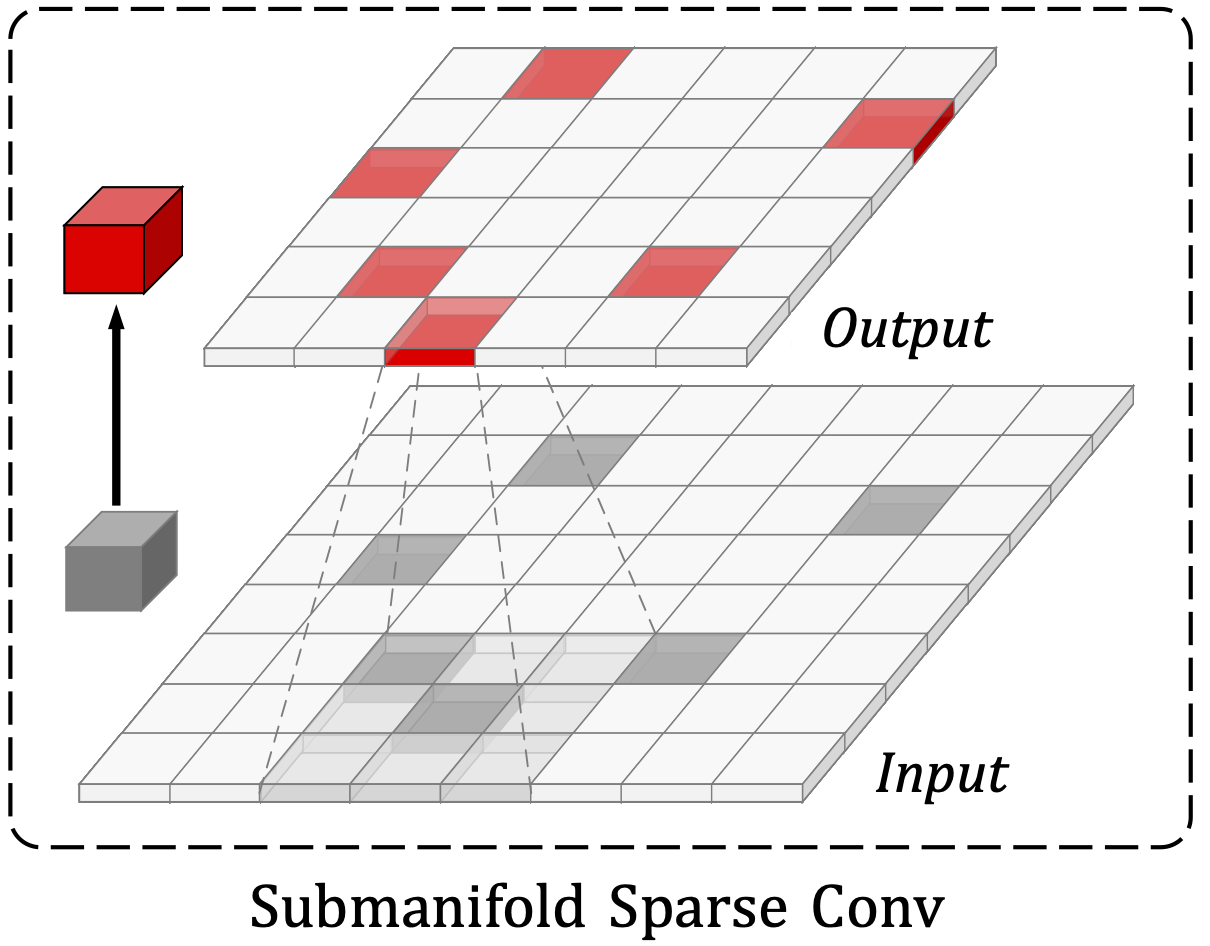
Focal Sparse Convolution
희소 컨볼루션의 종류와 관계없이 Pout이 정적이므로 바람직하지 않다. 대조적으로, 본 논문에서는 Pout이 동적으로 결정되도록 한다. 그리고 그 과정은 세 단계로 나누어 설명한다.
- 입방체 중요도 맵 Ip는 위치 p의 입력 feature 주변의 후보 출력 feature에 대한 중요도를 포함한다. 각 입방체 중요도 맵은 희소 컨볼루션 가중치 w와 동일한 형상 Kd를 가진다. sigmoid가 있는 추가적인 submanifold 희소 컨볼루션으로 예측된다.
- 그리고 Pin의 부분집합 중 중요도가 미리 지정한 임계값 τ 이상인 집합 Pim을 뽑는다.
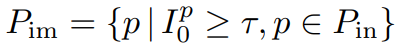
- Pim의 feature를 확장한다. p 주변의 출력은 중요도가 τ 이상인 집합, 동적인 출력 형상 Kdim(p)에 의해 결정된다.
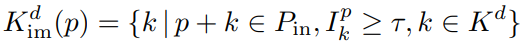
중요하지 않은 feature의 경우 출력 위치가 입력으로 고정(=submanifold)된다. 이런 방법을 사용하지 않고 fully dynamic한 방법을 사용하면 학습이 불안정해졌다고 한다.
최종 공식은
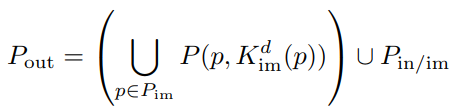
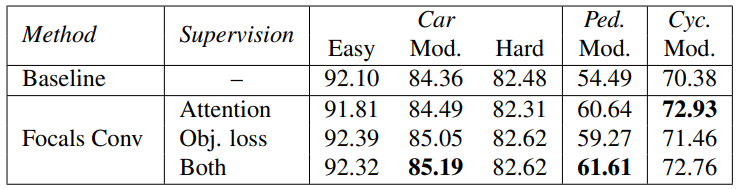
3D 객체 탐지에서 foreground 객체가 더 가치 있다는 사전 지식을 이용하여 중요도 맵 예측을 감독하기 위해 Focal loss를 사용한다. 그리고 attention 방법으로써 예측된 입방체 중요도 맵을 출력 feature에 곱하는 것으로 추가 감독을 한다. 이것은 중요도 예측 분기를 자연스럽게 차별화할 수 있게 만든다.
Fusion Focal Sparse Convolution
개념적으로 간단하지만 효과적인 Focals Conv의 multi-modal version을 제공한다. 이미지에서 RGB feature을 추출하고 LIDAR feature을 그에 맞춘다. 추출된 feature는 Focals Conv에서 입력 및 중요한 출력 sparse feature에 융합된다.
RGB feature를 일련의 컨볼루션과 다운샘플링 레이어를 통과시킨 뒤 MLP를 이용하여 sparse feature의 채널 수와 맞춘다. 그 후 변환과 증강을 거치고 이 논문에서 제시된 매개변수를 이용하여 sparse feature에 융합될 수 있게 한다.
그리고 입방체 중요도 맵 예측과 최종 출력 추가 감독에서 사용된다.
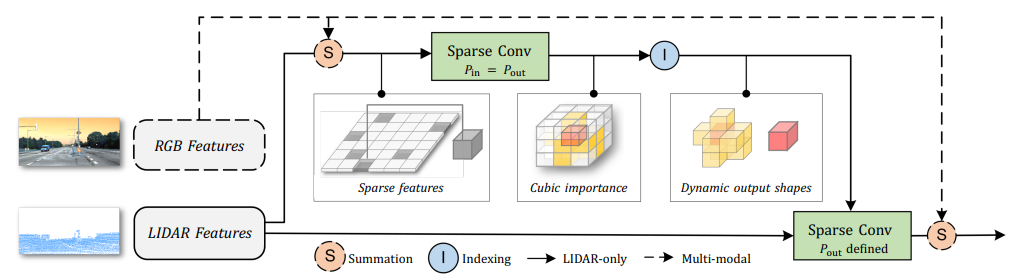
Multi-modal 레이어는 효율적이고 가벼우며 detector와 함께 훈련된다.
Focal Sparse Convolutional Networks
Focals Conv와 version F 모두 기존 모델에 쉽게 대체 가능하다. 중요도 예측 분기는 Focal loss와 위에서 언급한 attention 방법으로 훈련된다. 일반적인 3D 객체 탐지 모델에서 마지막 stage를 제외한 각 stage의 마지막 희소 컨볼루션만 Focals Conv로 교체한다.
Experiments
Setup and Implementation
둘 다 자율주행 관련 데이터셋이다.
LIDAR-only 실험에서, 백본 네트워크의 첫 세 단계에서 Focals Conv를 적용한다. Multi-modal의 경우, 적은 메모리 및 추론 비용을 위해 백본 네트워크의 첫 번째 단계에서만 Focals Conv-F를 적용한다.
Ablation Studies
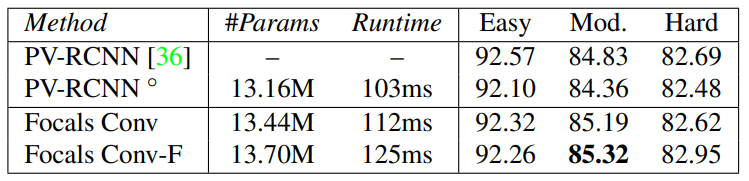
KITTI 데이터셋에서 비교. ◦는 공식 모델.
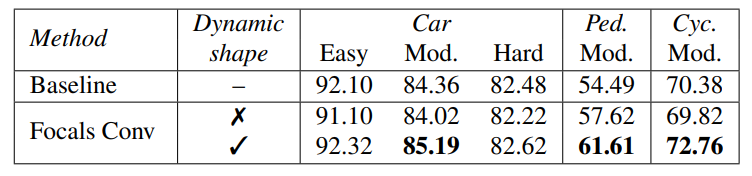
동적 형상을 사용하지 않고 출력을 특정 모양으로 고정했을 때와 비교.
확실히 동적 형상이 제일 좋다.
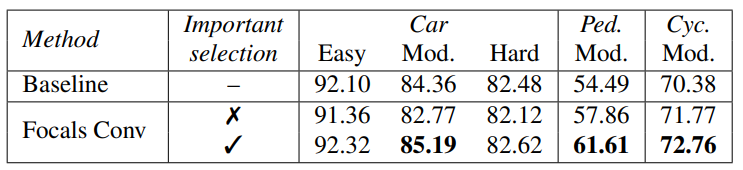
중요도 예측을 사용하지 않고 랜덤 선택을 적용했을 때와 비교.
Attention 기법, Focals loss를 통한 중요도 예측 감독 방법에 대한 비교.
각 stage에 Focals Conv를 적용해서 비교해 보았다.
첫 stage에서 사용했을 때 확실한 개선점이 있고, 높아질수록 점점 더 개선되지만 마지막 stage에서는 성능이 하락했다. Focals Conv는 출력 희소성을 조절하기 때문에 후속 feature 학습에 영향을 미치는 초기 단계에서 사용하는 것이 합리적이다. 기본 설정으로 (1,2,3)을 사용.
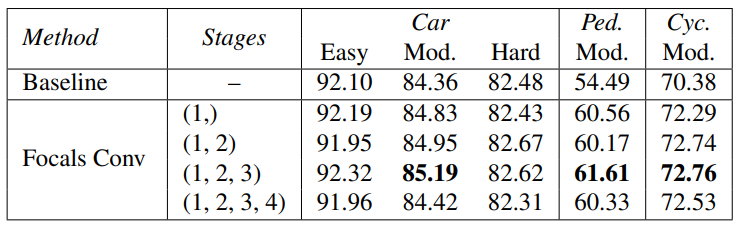
τ 값 설정 비교.

nuScenes 1/4 데이터셋에서 multi-modal 모델인 CenterPoint, +Fusion, + Focals Conv-F 비교.

Multi-modal에서 RGB feature를 융합할 sparse feature의 범위 비교.
첫 번째 stage에서만 성능이 향상되고 뒤의 stage에 융합하면 오히려 성능이 떨어진다.
1 stage에서도 모든 단계가 아니라 중요도 맵 예측에서만 융합하는 게 성능이 제일 좋다.

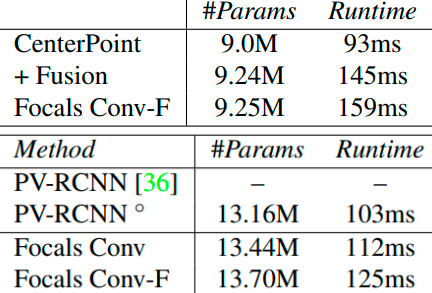
위의 표 중에서 Params와 Runtime만 비교.
약간의 오버헤드가 늘어났지만 거의 차이가 없음을 볼 수 있다.
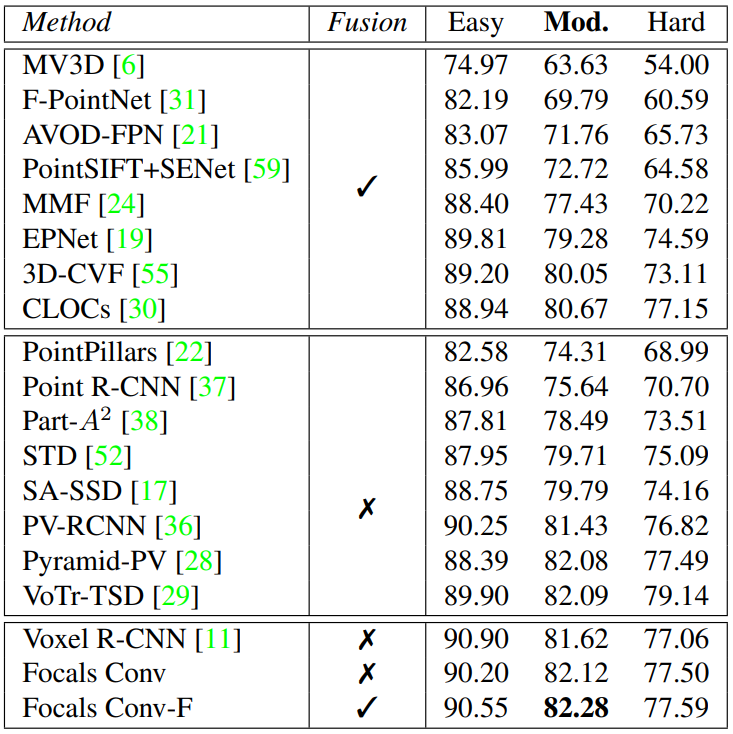
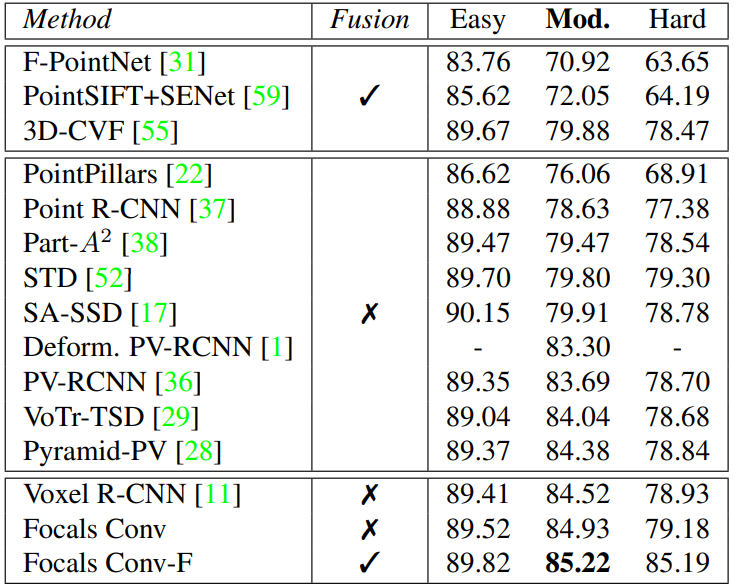
Main Results
KITTI test split
KITTI val split
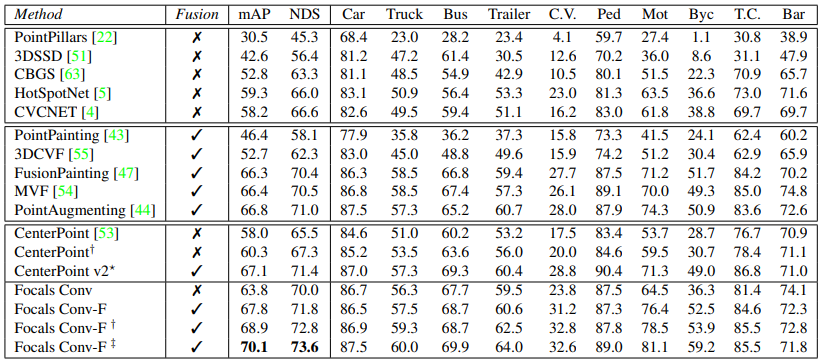
nuScenes test split
† = Flip, ‡ = Flip and rotation augmentation
Conclusion and Discussion
간단하고 효과적인 Focals Conv와 Focals Conv-F를 제시한다. LIDAR 및 Multi-Modal 3D 객체 탐지에서 초점을 가진 학습된 희소성이 필수적이라는 것을 보여준다.특히 대규모 nuScene에서 선도적인 성능을 달성한다.
'논문 리뷰 > etc.' 카테고리의 다른 글
| Can CNNs Be More Robust Than Transformers? 논문 리뷰 (0) | 2022.06.10 |
|---|---|
| When does dough become a bagel? Analyzing the remaining mistakes on ImageNet 논문 리뷰 (0) | 2022.05.22 |
| Thin-Plate Spline Motion Model for Image Animation (TPS) 논문 리뷰 (0) | 2022.05.11 |
| Neural 3D Scene Reconstruction with the Manhattan-world Assumption 논문 리뷰 (0) | 2022.05.08 |
| StyleGAN-Human 논문 리뷰 (0) | 2022.05.03 |
| Masked Siamese Networks 논문 리뷰 (0) | 2022.04.20 |



