며칠 전 공개된 Masked siamese network

Abstract
이미지 표현을 학습하기 위한 자체 지도 학습(Self-Supervised Learning) 프레임워크인 Masked Siamese networks(MSN)를 제안한다. 본 논문의 접근 방식은 무작위로 마스크된 패치를 포함하는 이미지 뷰의 표현을 마스크되지 않은 원래 이미지의 표현과 일치시킨다. 이러한 자체 감독 사전 훈련 전략은 마스크되지 않은 패치만 네트워크에서 처리되기 때문에 ViT(Vision Transformer)에 적용할 때 특히 확장 가능하다. 결과적으로 MSN은 joint-embedding 아키텍처의 확장성을 향상시키는 동시에 로우샷 이미지 분류에서 경쟁적으로 수행하는 높은 의미 수준의 표현을 생성한다. 5000개의 주석이 달린 이미지만 있는 ImageNet-1K에서 기본 MSN 모델은 72.4%의 정확도(Top-1 accuracy)를 달성하고, ImageNet-1K labels의 1%를 사용하여 75.7%의 정확도를 달성하였다.
Introduction
자체 지도 학습(SSL)은 이미지 표현의 비지도 학습을 위한 효과적인 전략으로 등장하여 방대한 양의 데이터에 수동으로 주석을 달 필요가 없다. label이 없는 데이터에 대한 대규모 모델을 교육함으로써 SSL은 label이 거의 없는 다운스트림 예측 작업에 효과적으로 적용될 수 있는 표현을 학습하는 것을 목표로 한다.
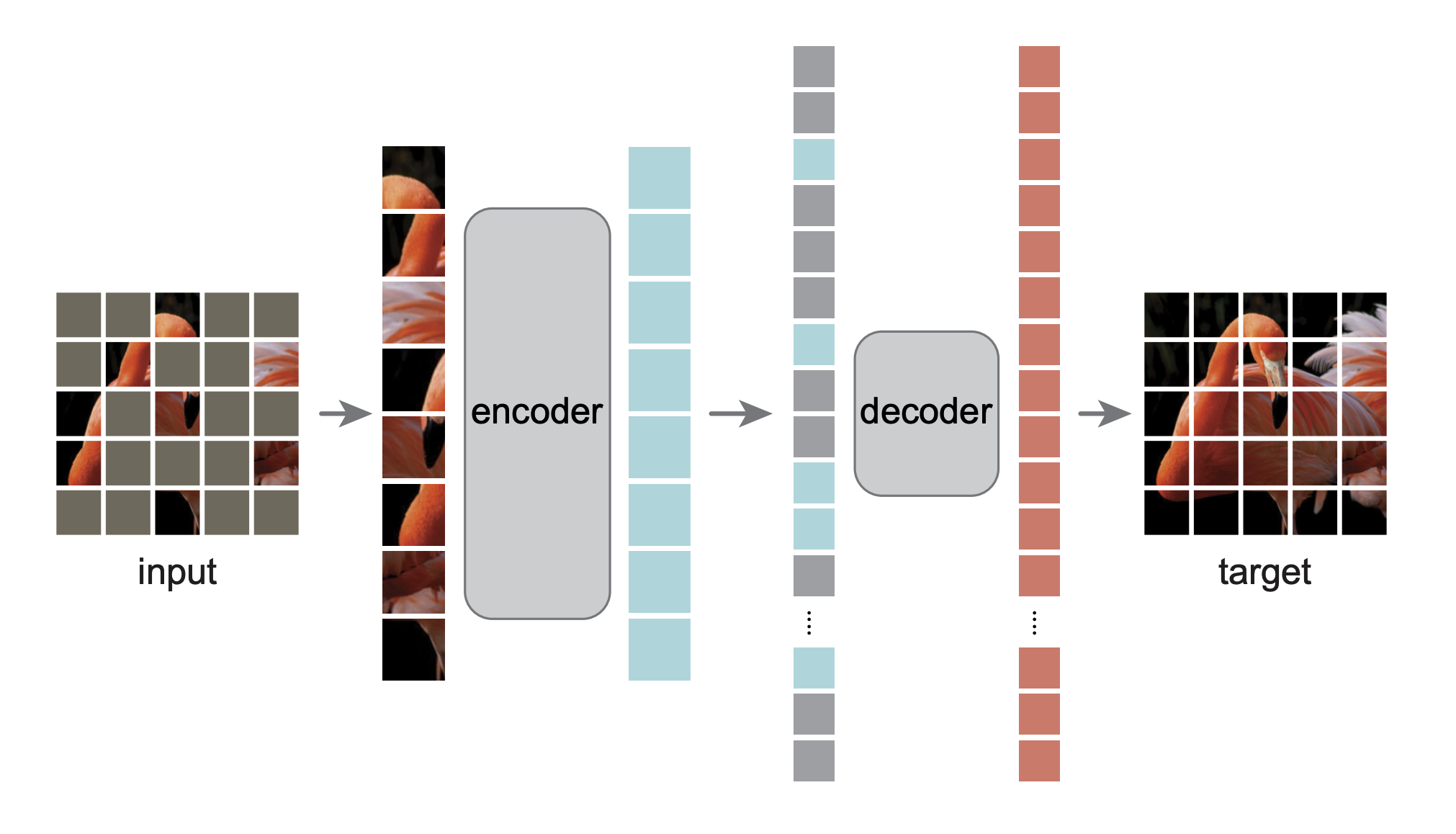
SSL의 핵심 아이디어 중 하나는 입력의 일부를 제거하고 제거된 콘텐츠를 예측하는 방법을 배우는 것이다. 자동 회귀 모델과 노이즈 제거 auto-encoder는 픽셀 또는 토큰 수준에서 누락된 부분을 예측하여 비전에서의 이 원칙을 인스턴스화한다. 특히 입력에서 무작위로 마스크된 패치를 재구성하여 표현을 학습하는 Masked auto-encoders가 비전에 성공적으로 적용되었다. 이는 로우샷 설정에서 과적합으로 이어질 수 있지만 수백만 개의 label이 있는 대형 labeled 데이터 세트에서 미세 조정할 때 대규모 모델의 훈련을 가능하게 했고 최첨단 성능을 보여주었다.
샴 네트워크와 같은 접근 방식은 동일한 이미지의 두 가지 다른 뷰에 대해 유사한 임베딩을 생성하도록 인코더 네트워크를 통해 표현을 학습한다. 이후 여기서 무작위 스케일링, 자르기 및 색상 지터와 같은 이미지 변환을 입력에 적용하는 방법들이 제안되었다. 이 불변성 기반 사전 훈련에 의해 도입된 유도 편향은 일반적으로 높은 의미 수준의 강력한 기성(off-the-shelf) 표현을 생성하지만 종종 모델링에 도움이 될 수 있는 풍부한 로컬 구조를 무시한다.
본 연구에서는 픽셀 및 토큰 레벨 재구성을 피하면서 masked 노이즈 제거 아이디어를 활용하는 자체 지도 학습 프레임워크인 Masked Siamese Networks을 제안한다.

이미지의 두 가지 view를 지정하면 MSN은 한 보기에서 패치를 임의로 마스크하고 다른 보기는 변경하지 않는다.
목표는 ViT로 매개 변수화된 신경망 인코더를 훈련하여 두 보기에 대해 유사한 임베딩을 출력하는 것이다. 이 절차에서 MSN은 입력 수준에서 마스크된 패치를 예측하지 않고, 마스크된 입력의 표현이 마스크되지 않은 입력의 표현과 일치하도록 함으로써 표현 수준에서 암시적으로 노이즈 제거 단계를 수행한다.

masked patches에서 조건화된 생성 모델의 샘플.
배경, 포즈 등의 정보를 버리고 대상에 대한 의미 정보를 인코딩한다.
MSN은 특히 로우샷 예측에서 뛰어나다. masked auto-encoder보다 100배 적은 labels를 사용하여 우수한 분류 성능을 달성했고, 표준 1% ImageNet 로우샷 분류 작업에서 MSN에서 훈련된 ViT-B/4는 75.7%의 정확도를 달성하여 거의 10배 적은 매개 변수를 사용하면서 이전의 800M 매개 변수 최첨단 컨볼루션 네트워크를 능가한다.

label당 1개, 5개 등 매우 희박한 이미지에서도 작동하며 계산 비용도 적고 성능도 좋다.
Prerequisites
Problem Formulation
large collection of unlabeled images D = (xi)U
small dataset of annotated images S = (xsi , yi)L
S에 있는 이미지가 D에 포함 될 수 있습니다.(논문에서 may라고 표현)
본 연구의 목표는 먼저 D에 대한 사전 교육을 실시한 다음 S를 사용하여 지도 작업에 표현을 적응시킴으로써 이미지 표현을 학습하는 것이다.
Siamese Networks
샴 네트워크의 목표는 자체 지도 학습에 사용되는 것으로, 이미지의 두 보기에 대해 유사한 이미지 임베딩을 생성하며 결론적으로 view의 차이에 민감하지 않은 인코더를 배우는 것이다.
샴 아키텍처의 주요 과제는 인코더가 입력과 관계없이 일정한 이미지 임베딩을 생성하는 표현 붕괴를 방지하는 것이다.
대책으로 contrastive loss 등 여러 방법들이 있음.
Vision Transformer
ViT : 워낙 유명하니까 다들 알겠지만 간단히 설명하자면 원본 이미지를 패치로 나누고 positional encoding을 한 다음에 cls 토큰을 붙혀 트랜스포머 인코더를 통과시켜서 결과를 도출해낸다. 언어 모델에서만 사용되던 트랜스포머를 컴퓨터 비전에 최초로 접목한 시도로써 트랜스포머가 equivariance를 해치기 때문에 아직 이미지 생성에서는 갈 길이 멀지만 분류 분야에서는 꽤 좋은 성능을 낸다.
Masked Siamese Networks
불변성 기반 사전 훈련과 마스크 노이즈 제거가 결합된 MSN의 훈련 절차는 다음과 같다.
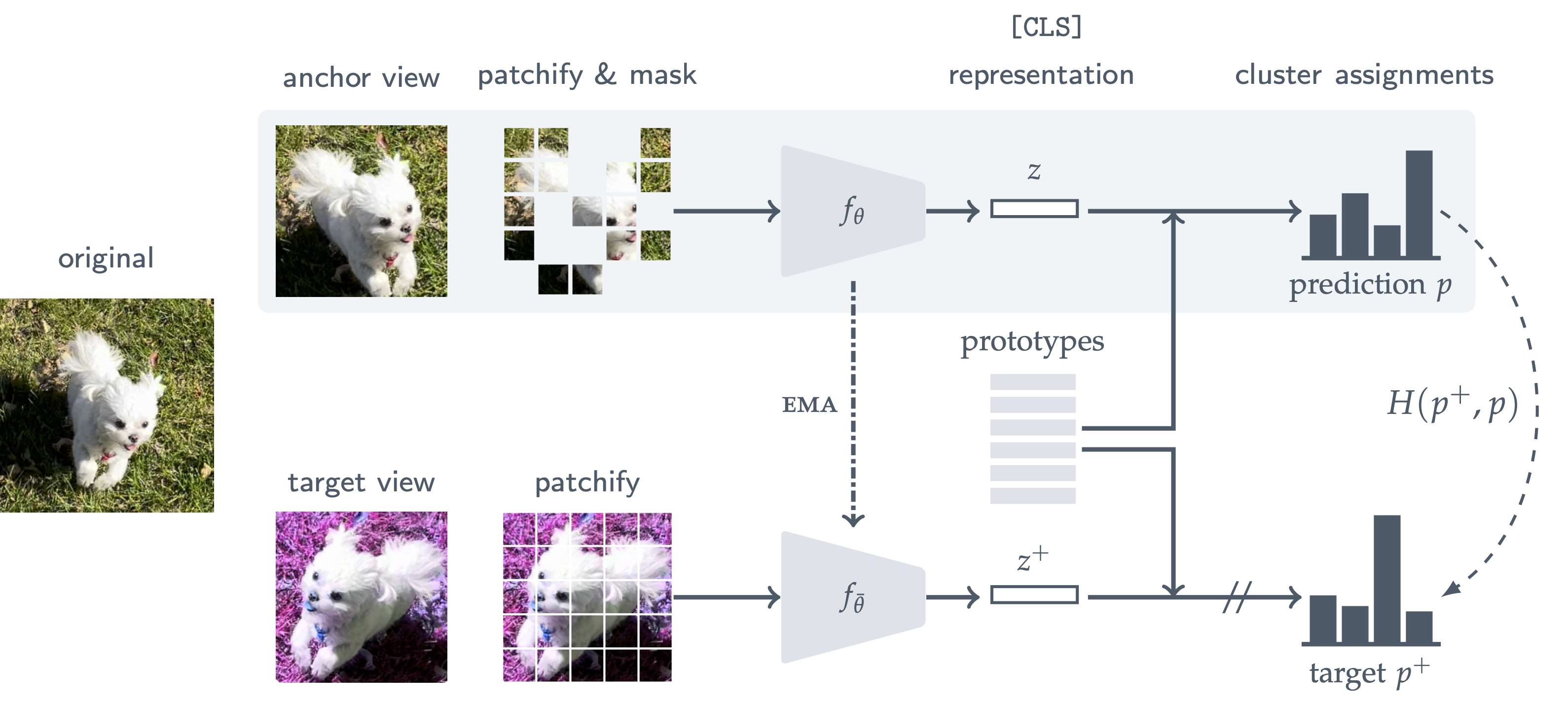
우선 랜덤 augmentation으로 anchor view와 target view 두 가지 view를 생성한다. 그런 다음 target view는 변경되지 않은 채 anchor view에 랜덤 마스크를 적용한다. 클러스터링 기반 SSL 접근 방식과 유사하게, anchor 및 target view 모두에 대한 프로토타입 세트에 대한 소프트 분포를 계산함으로써 학습이 이루어진다. 그런 다음 마스크되지 않은 target view의 표현과 동일한 프로토타입에 마스크된 anchor view의 표현을 할당하는 것이 목표이다. 이 기준을 최적화하기 위해 표준 교차 엔트로피 손실을 사용한다.
마스크 이미지 모델링에 대한 이전 연구와 대조적으로, MSN의 마스크 노이즈 제거 프로세스는 생성적이기보다는 차별적이다. 마스킹된 패치의 픽셀 값(또는 토큰)을 예측하는 게 아니라 남아있는 패치에서 특징을 추출하는게 목적이기 때문이다. 대신 손실은 인코더의 cls 토큰에 해당하는 출력에 직접 적용된다.
Input Views
미니배치 B의 i번째 이미지를 xi , 그 이미지의 target view를 xi+ ,
그 이미지의 M개의 anchor view들을 xi,1, xi,2, . . . , xi,M이라고 하자. (하나의 target view에 대해 여러 anchor view들의 쌍이 생기는 셈이다.)
Patchify and Mask
이미지를 N x N 개로 패치화한다.
패치화 + 마스킹한 anchor patches는 x̂i,m , 패치화한 target patches는 x̂i+
마스킹 때문에 두 패치 시퀸스는 길이가 다르다.

Encoder
피라미터화된 anchor encoder fθ(), 인코더 출력 zi,m ∈ Rd (d차원의 벡터 출력)
피라미터화된 target encoder fθ̄(), 인코더 출력 zi+ ∈ Rd
학습 초기에는 두 인코더가 같지만 anchor encoder의 지수 이동 평균(EMA)을 통해 target encoder를 업데이트한다.
인코더는 ViT 모델이며, 네트워크의 출력을 cls 토큰에 해당하는 표현으로 간주한다.
Similarity Metric and Predictions
q ∈ RK x d
K는 암시적 클래스의 역할을 하는 학습 가능한 프로토타입의 갯수, d는 인코더 출력벡터의 차원 수이다.
인코더 훈련을 위해 유사성에 기초하여 분포를 계산하는데, 이러한 프로토타입과 각각의 view 쌍 사이에서, 이러한 분포간의 차이에 대해 인코더에 불이익을 준다.
예를 들어 anchor 표현 zi,m의 경우, 프로토타입 matrix q에 대한 코사인 유사도를 측정하여 예측인 pi,m을 계산한다.
다음과 같이 표현할 수 있다.

τ는 상수인 temperature이다. τ가 높을수록 더욱 분포가 더욱 부드러워진다.
마찬가지로 target 표현 zi+에 대해 pi+을 계산할 수 있고 상수 τ+를 사용한다.
더 날카로운 target 예측을 장려하기 위해 τ+ < τ 가 되게 한다. 이는 모델이 신뢰할 수 있는 낮은 엔트로피 anchor 예측을 생성하도록 암시적으로 안내한다. (직관적으로 생각하면 anchor 예측은 마스크 때문에 부정확하고 그러면 target 예측을 따라가는 모양새가 된다. 생성 모델에서 L2 loss가 이미지를 흐리게 하는 것 처럼 부정확한 anchor 예측의 분포를 target보다 부드럽게 해야되는 듯 하다. 자세한건 논문 부록 B 참조)
Training Objective
anchor 예측 pi,m과 target 예측 pi+가 같도록 학습해야 하며, 표준 교차 엔트로피 H(pi,m, pi+)를 사용한다.
또한 모델이 전체 프로토타입 세트를 활용하도록 장려하기 위해 평균 엔트로피 최대화(ME-MAX) regularizer를 통합한다.
모든 anchor view의 평균 예측값 p̄, ME-MAX regularizer는 p̄의 엔트로피가 최대가 되도록 한다.
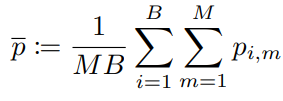
그래서 최종 목표 함수는
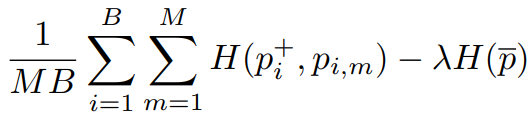
이 식을 최소화 하는 것이다. (상수 λ)
anchor와 target view의 예측값이 같아야 하고, 모든 anchor view의 평균 예측값이 최대가 되게 해야 한다.
훈련 시 gradients계산은 anchor 예측 pi,m에 대해서만 계산한다.
설명은 길게 했지만 그냥 샴 네트워크에 ViT와 mask, 프로토타입 프로세스를 추가한 것 뿐이다. 엄청 간단한 모델임.
Related Work


Results
1) Label-Efficient Learning
SSL의 전제는 효과적으로 적용할 수 있는 레이블이 없는 데이터에 대한 표현을 배우는 것이다. label이 거의 없는 예측 작업에서 유리하다.
Extreme Low-Shot

적은 epochs로도 low-shot 상황에서 기존 모델들보다 높은 정확도를 볼 수 있다.
가장 큰 모델인 ViT-L/7을 훈련할 때는 패치의 70% 이상을 마스킹 한다. 그래서 훈련 비용에서도 엄청나게 효과적이다.
70% 이상을 지웠는데도 성능이 잘 나오는 게 신기하다.
1% ImageNet-1K
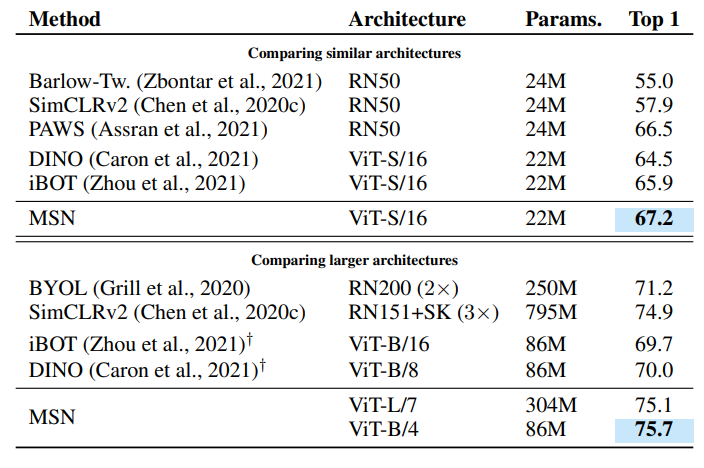
1%의 라벨을 사용한 ImageNet-1K의 로우샷 평가(클래스당 약 13개 이미지)
2) Linear Evaluation and Fine-tuning
표현을 적응시키기 위해 더 많은 감독된 샘플을 사용할 수 있는 표준 평가 벤치마크에 대한 최신 기술과 비교한다. 1.28M 레이블이 있는 전체 ImageNet-1K 교육 이미지를 사용한다.
Linear Evaluation
네트워크 가중치를 고정하고 그 위에 선형 분류기를 훈련시킨 뒤 평가하는 방법이다.

Fine-Tuning
100%의 label을 사용하여 미세조정한 뒤 평가하는 방법이다.
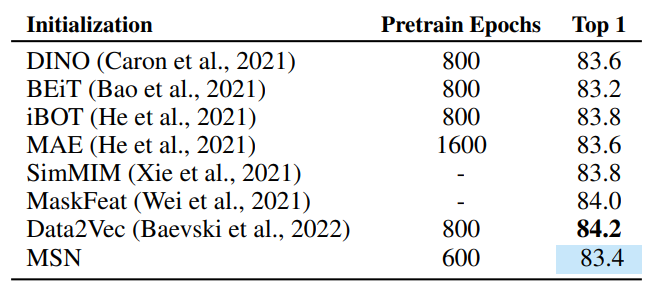
마스킹을 많이 해서 그런지 모든 정보가 오픈돼 있을 때는 딱히 효과적이지 못한 듯 하다.
3) Transfer Learning
다른 데이터셋에 대한 전이 학습 실험

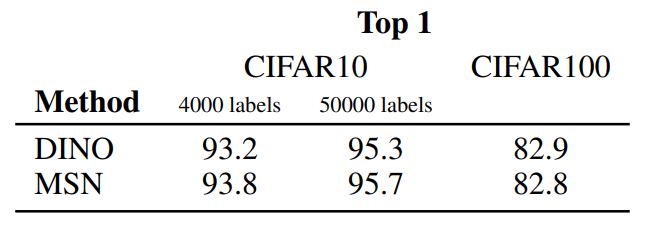
이미지나 label이 부족한 상황이 아니면 딱히 다른 모델들과 특별한 차이는 없는 듯 하다.
4) Ablations
1%의 라벨을 사용한 ImageNet-1K의 로우샷 상황에서의 ablation test.

두 가지 마스킹 전략을 모두 사용하는 것이 제일 좋다.

모델 크기가 클수록 마스킹 비율을 높이는 것이 효과적이다.

많은 augmentation을 적용하는 것이 더 효과적이다.
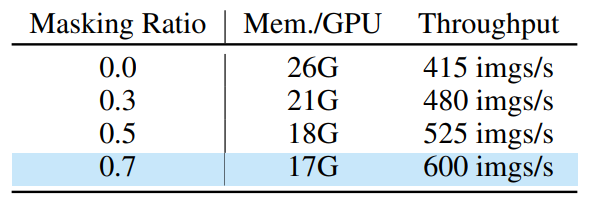
마스킹을 많이 할 수록 당연히 메모리효율적이다.
Conclusion
본 논문에서 픽셀 및 토큰 수준 재구성을 피하면서 마스크 노이즈 제거 아이디어를 활용하는 Self Supervised Learning 프레임워크인 MSN(Masked Siamese Networks)을 제안했다. MSN은 label이나 클래스당 이미지가 희박한 상황에서 강력하다. view 불변 표현 학습에 의존함으로써 MSN은 데이터 변환을 지정해야 하며, 최적의 변환과 불변성은 데이터 세트와 작업에 종속될 수 있다. 향후 연구에서는 이러한 변환을 학습하기 위해 보다 유연한 메커니즘을 탐색하고 등변형 표현의 사용도 탐색할 계획이다. 라고 하네요~~
후기
사실 논문도 굉장히 짧고 모델도 간단하고 다양한 아이디어들을 잘 결합한 논문인 것 같다.
'논문 리뷰 > etc.' 카테고리의 다른 글
| Can CNNs Be More Robust Than Transformers? 논문 리뷰 (0) | 2022.06.10 |
|---|---|
| When does dough become a bagel? Analyzing the remaining mistakes on ImageNet 논문 리뷰 (1) | 2022.05.22 |
| Thin-Plate Spline Motion Model for Image Animation (TPS) 논문 리뷰 (0) | 2022.05.11 |
| Neural 3D Scene Reconstruction with the Manhattan-world Assumption 논문 리뷰 (1) | 2022.05.08 |
| StyleGAN-Human 논문 리뷰 (0) | 2022.05.03 |
| Focal Sparse Convolutional Networks(FocalsConv) 논문 리뷰 (0) | 2022.05.01 |



