Abstract
LMM(Large Multimodal Model)의 visual encoder를 ConvNeXt로 대체하여 계산을 줄이고 성능 향상
[Github]
[arXiv](2024/05/24 version v1)
ConvLLaVA
ConvNeXt as Standalone Visual Encoder
구성은 LLaVA와 동일하지만 visual encoder를 ViT에서 ConvNeXt로 교체했다.

ConvNeXt는 ViT에 비해 1/4 미만의 visual token을 생성하여 중복성을 줄이고 LLM의 계산 부담을 완화한다.
추가로 고해상도 이미지에서 전처리의 필요성과 토큰 수를 줄이기 위해 stage를 추가하여 5-stage의 ConvNeXt 사용.
Updating ConvNeXt is Essential
Visual encoder는 고정했을 때 보다 LLM과 함께 fine-tuning 할 때 더 성능이 좋았다.
고정:

Fine-tuning:

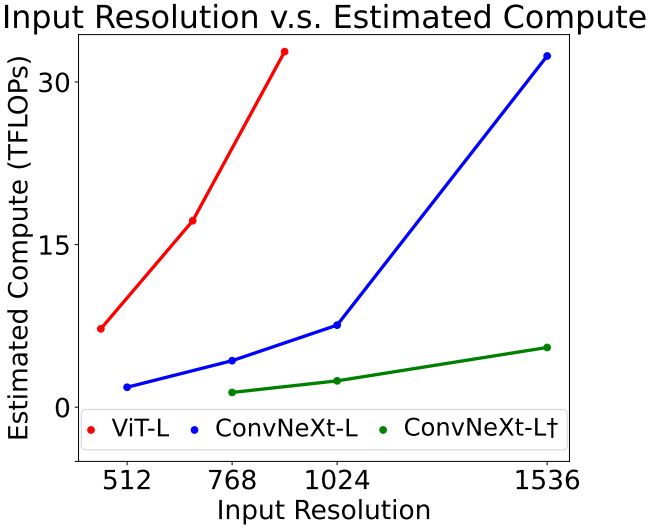
Training with Stage 5 Scales up Resolution to 1536
5-stage에 대한 ablation:

통찰:
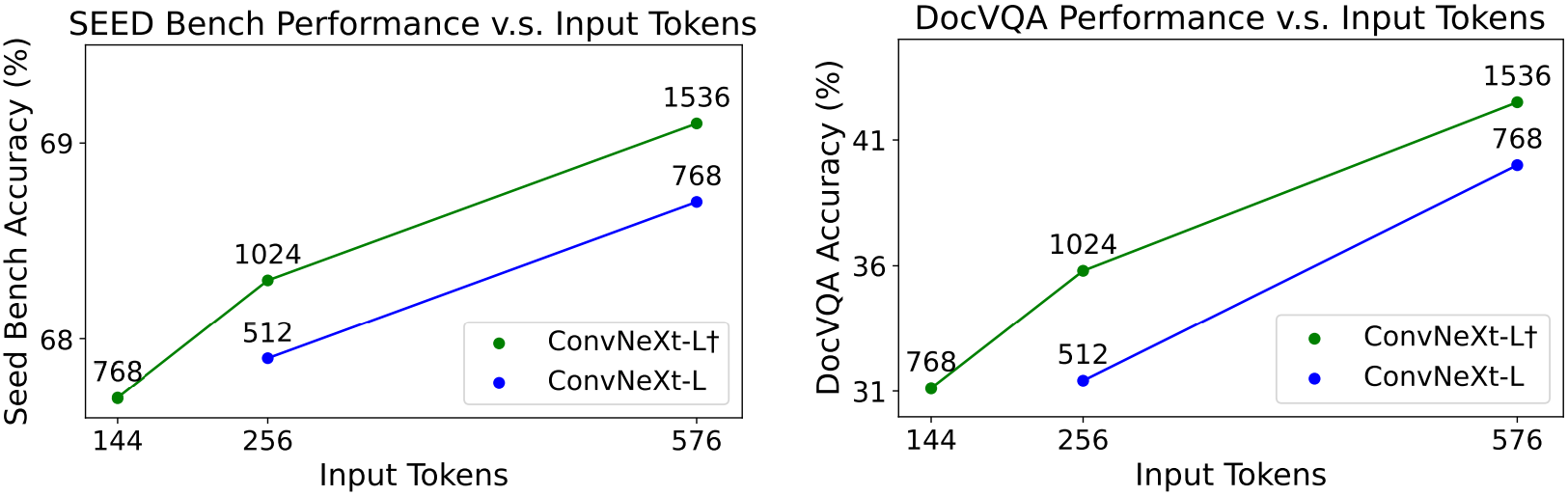
- Visual token의 수가 동일한 경우 고해상도 모델의 성능이 더 좋다.
- Visual token 수의 중요성은 벤치마크마다 다르다. 일반 벤치마크보다 OCR 벤치마크에서 토큰 수로 인한 성능 차이가 크다.
Experiments
훈련은 3단계로 진행.
Projector 초기화 → Vision-Language Pretraining → Visual Instruction Tuning
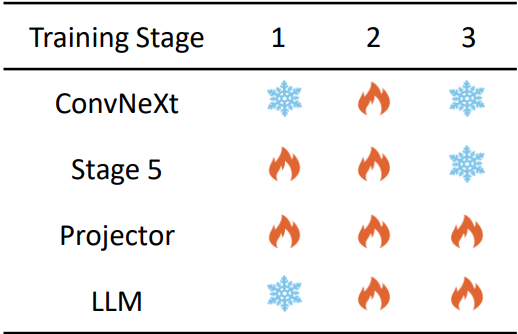
결과: