Abstract
Latent attention layer, contrastive instruction-tuning을 통해 최첨단 성능의 텍스트 임베딩 모델인 NV-Embed 개발
[arXiv](2024/05/27 version v1)
Method
Bidirectional Attention
표현 학습을 향상시키기 위해 대조 학습 중에 causal attention mask를 제거한다.
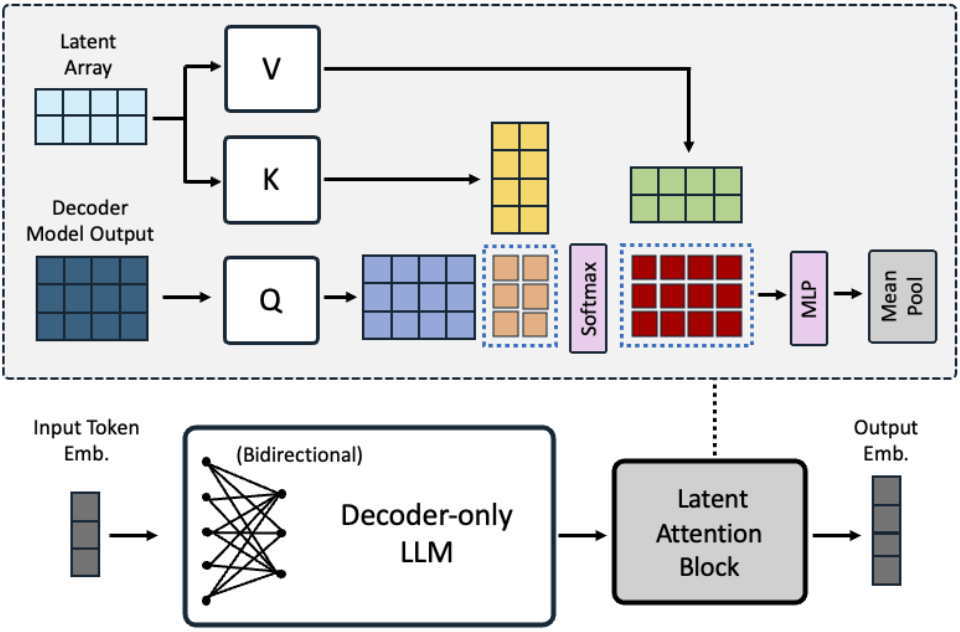
Latent Attention Layer
일반적으로 토큰 시퀀스의 임베딩을 얻는 방법은 2가지가 있다. 시퀀스를 mean pooling 하거나 마지막 <EOS> 토큰의 임베딩을 얻는 것이다. 하지만 평균 풀링은 중요한 정보를 희석할 수 있고, <EOS> 임베딩은 후반 토큰에 의존하는 recency bias가 생길 수 있다.
대안으로 보다 표현적인 풀링을 위해 latent attention layer를 제안한다.
LLM의 출력을 query로 간주하고 trainable latent array와 attention을 수행한 뒤 MLP 이후 평균 풀링을 적용해 임베딩을 얻는다.
Two-stage Instruction-Tuning
검색 및 비검색 작업 (e.g. 분류, 클러스터링)을 적절하게 수행하려면 다양한 작업의 특성을 고려해야 한다.
예를 들어 배치 내의 다른 데이터를 부정 예시로 취급하는 in-batch negatives trick의 경우 비검색 작업에 악영향을 끼칠 수 있다.
따라서 2단계 instruction-tuning을 수행.
- 1-stage: 검색 데이터셋, in-batch negatives trick, 대조 훈련
- 2-stage: 엄선된 hard negatives 예제를 활용하여 각 작업에 대해 contrastive instruction-tuning을 수행
Experiments
Mistral-7B에 LoRA, latent attention layer를 통합하여 fine-tuning 한다.




