Abstract
DPO보다 간단하면서도 더 효과적인 SimPO 제안
[Github]
[arXiv](2024/05/23 version v1)
Introduction
SimPO의 장점:
- Simplicity: DPO 및 다른 접근 방식에 비해 가볍고 구현하기 쉬움
- Significant performance advantage: 단순함에도 불구하고 최신 방법들보다 뛰어난 성능을 보여줌
- Minimal length exploitation: 응답 길이를 크게 늘리지 않음. (RLHF는 출력이 길어지는 편향이 있다.)
SimPO: Simple Preference Optimization
DPO는 명시적인 보상 모델을 학습하는 대신 암묵적으로 보상을 reparameterize 하여

다음과 같은 목표를 사용한다.
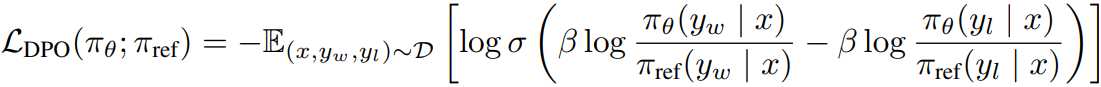
A Simple Reference-Free Reward Aligned with Generation
Discrepancy between reward and generation for DPO
DPO는 다음과 같은 단점이 있다.
- 참조 모델이 필요하여 훈련 중 추가 메모리와 계산이 발생한다.
- 훈련 중 최적화되는 training metric과 추론에 사용되는 generation metric 간에 불일치가 있다.
구체적으로, DPO에서 암묵적인 보상은 어떤 절댓값이 아닌 이전 정책에서 얼마나 벗어났는지에 대해 더 높은 보상을 매기기 때문에 어떤 삼중항 (x, yw, yl)에 대해 다음을 항상 만족하지 않으며

실제로 DPO로 훈련된 세트의 약 50%만이 이를 만족했다.

Length-normalized reward formulation
당연하게도 암묵적 보상의 training, generation metric을 일치시키는 방법이 채택되었고 길이 정규화를 추가하였다.

참조 모델이 필요 없고, 길이 정규화 덕분에 더 길지만 품질이 낮은 시퀀스가 생성되는 경향이 줄어들었다.
The SimPO Objective
추가로 승리 응답과 패배 응답의 차이의 최솟값을 보장하기 위해 마진 항을 도입했다.
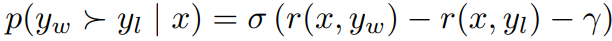
최종 SimPO 목표는 다음과 같다.
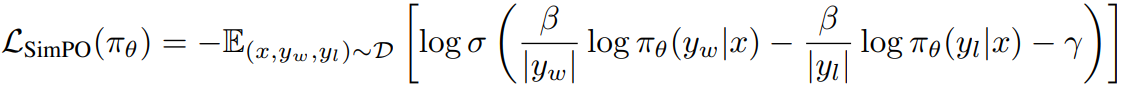
종합 비교:

Experimental Results