Abstract
Multi-Query Attention을 한 단계 발전시켜 레이어 간 KV cache를 공유하는 Cross-Layer Attention 제안
[arXiv](2024/05/21 version v1)
Cross-Layer Attention
Background: Multi-Query Attention, Grouped-Query Attention
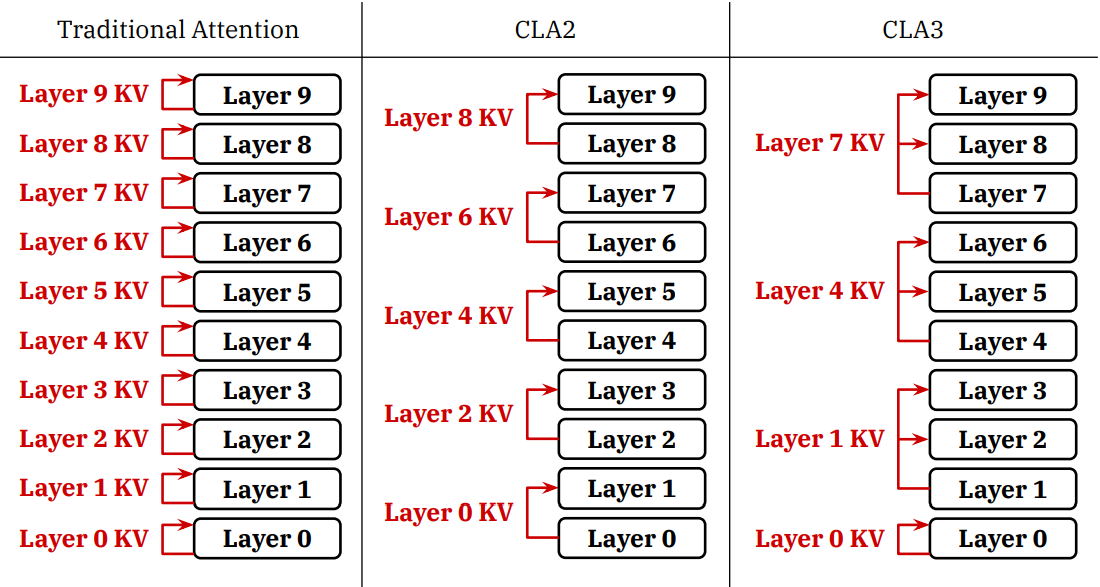
Sharing KV Activations Across Layers
단일 레이어 내에서 KV heads를 공유하는 것처럼, 레이어 간에도 공유할 것을 제안한다.
그러한 아키텍처를 Cross-Layer Attention이라고 명명.
일부 레이어에서만 KV projection를 계산하고 projection이 없는 레이어는 이전 계층의 KV를 재사용한다.

MQA, GQA와 같이 사용할 수 있으며 다음과 같이 조절 가능하다.
Pretraining Experiments
Perplexity, KV cache bytes 둘 다 낮을수록 좋음.

'논문 리뷰 > Language Model' 카테고리의 다른 글
| SimPO: Simple Preference Optimization with a Reference-Free Reward (0) | 2024.05.27 |
|---|---|
| RLHF Workflow: From Reward Modeling to Online RLHF (1) | 2024.05.27 |
| MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning (0) | 2024.05.24 |
| LoRA Learns Less and Forgets Less (0) | 2024.05.24 |
| Chameleon: Mixed-Modal Early-Fusion Foundation Models (1) | 2024.05.23 |
| Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models (0) | 2024.05.21 |



