Abstract
Code&math에서 LoRA와 full-finetuning의 차이를 비교, 분석
[arXiv](2024/05/15 version v1)
Introduction
- Full-finetuning은 code&math에서 LoRA보다 정확하고 샘플 효율적이다.
- LoRA는 강력한 정규화를 제공하여 source domain을 덜 잊어버린다.
- LoRA는 full-finetuning보다 하이퍼피라미터에 더 민감하다.
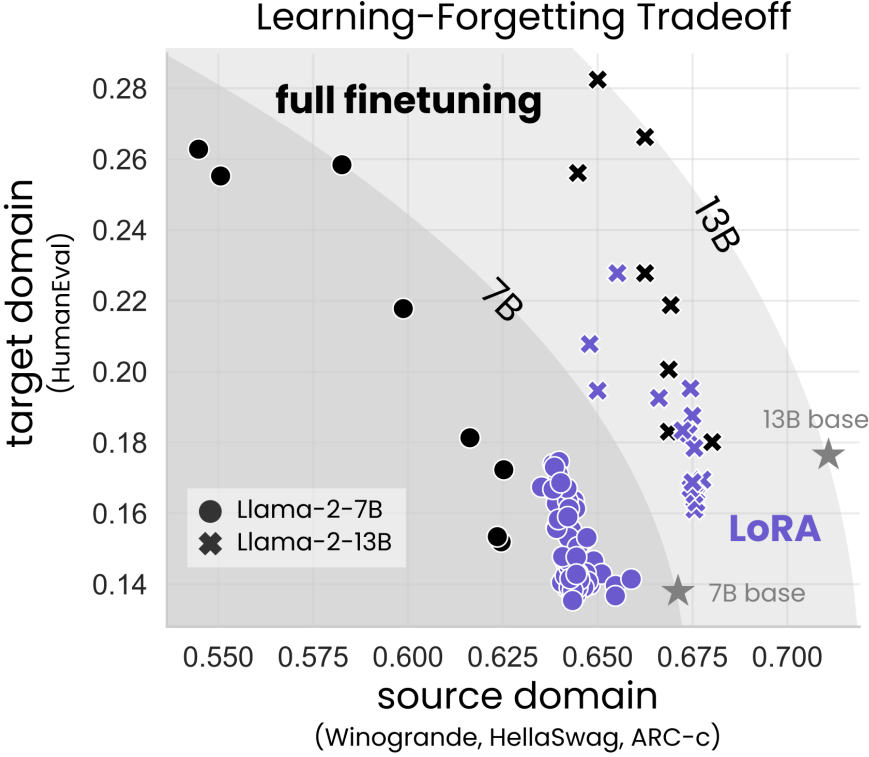
연구진은 결론적으로 IFT에 LoRA를 사용할 것을 추천했다. (All LoRA, 낮은 rank 채택)
IFT의 좋은 성능, 높은 망각 특징을 LoRA가 보완해 줄 수 있기 때문이다.
Results
6개 설정의 LoRA를 훈련한다. (module = [Attention, MLP, All], rank = [16, 256])
또한 IFT (Instruction Fine-Tuning), CPT (Continued Pre-Training) 방법 비교.
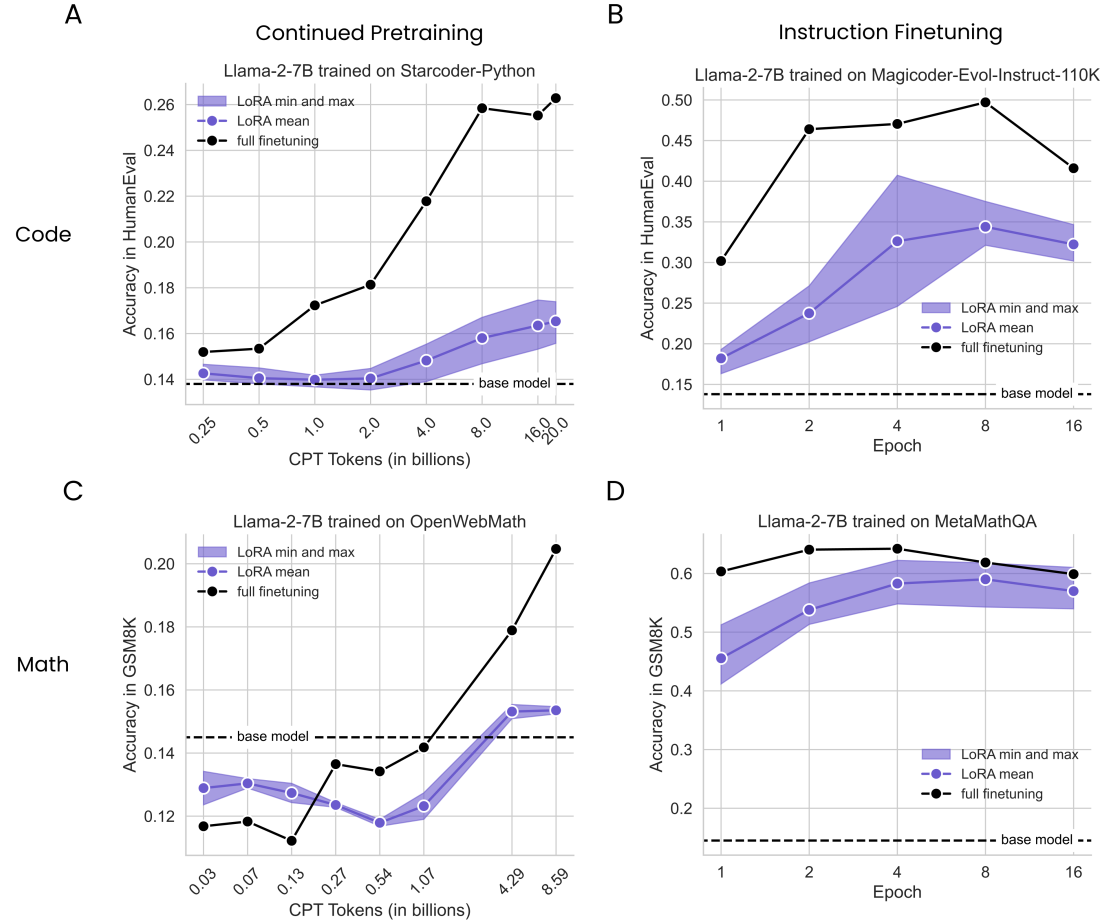
LoRA underperforms full finetuning in programming and math tasks
- 전반적으로 FFT의 성능이 좋음.
- IFT가 평가 문제와 더 비슷하기 때문에 전반적으로 CPT 보다 성능이 좋음.
- Code에서 LoRA와 FFT의 차이가 더 큼.
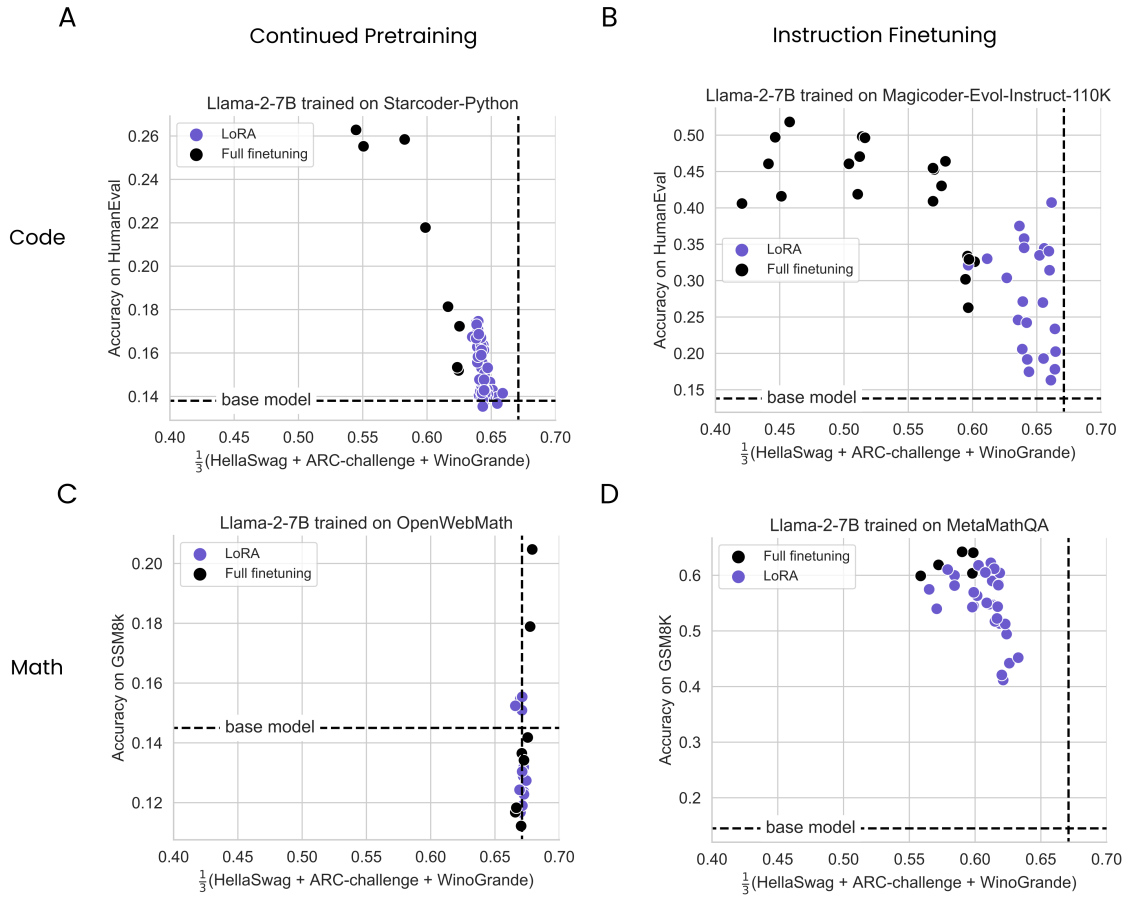
LoRA forgets less than full finetuning
- IFT가 망각을 더 많이 유발한다. (사전 훈련과 데이터 종류가 달라서 그런 듯)
- Code가 망각을 더 많이 유발한다.
- 데이터가 많아질수록 망각이 증가한다.

The Learning-Forgetting Tradeoff
LoRA는 덜 배우고 덜 잊는다.
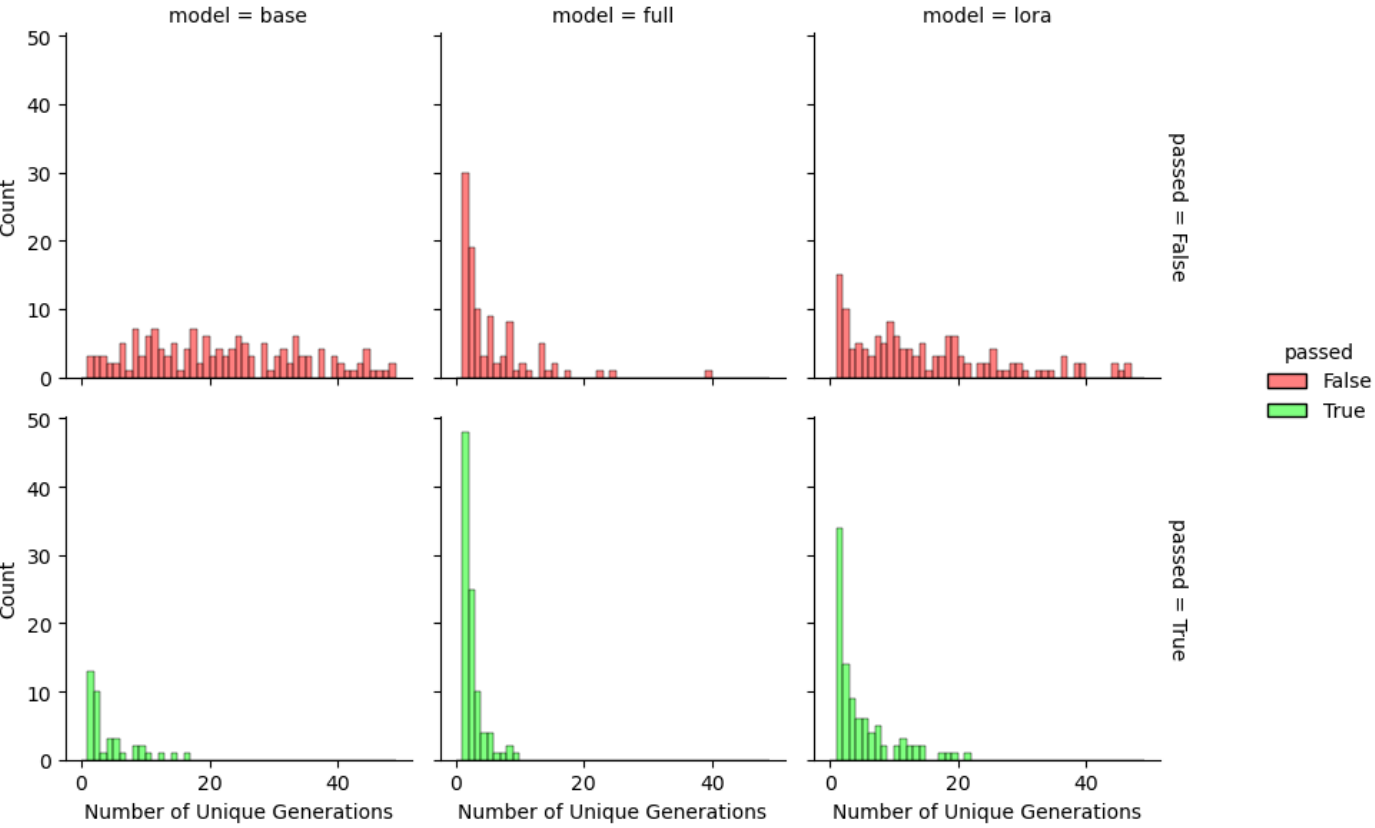
LoRA’s regularization properties
LoRA는 다른 정규화 방법들에 비해 더 강력한 정규화를 제공하며
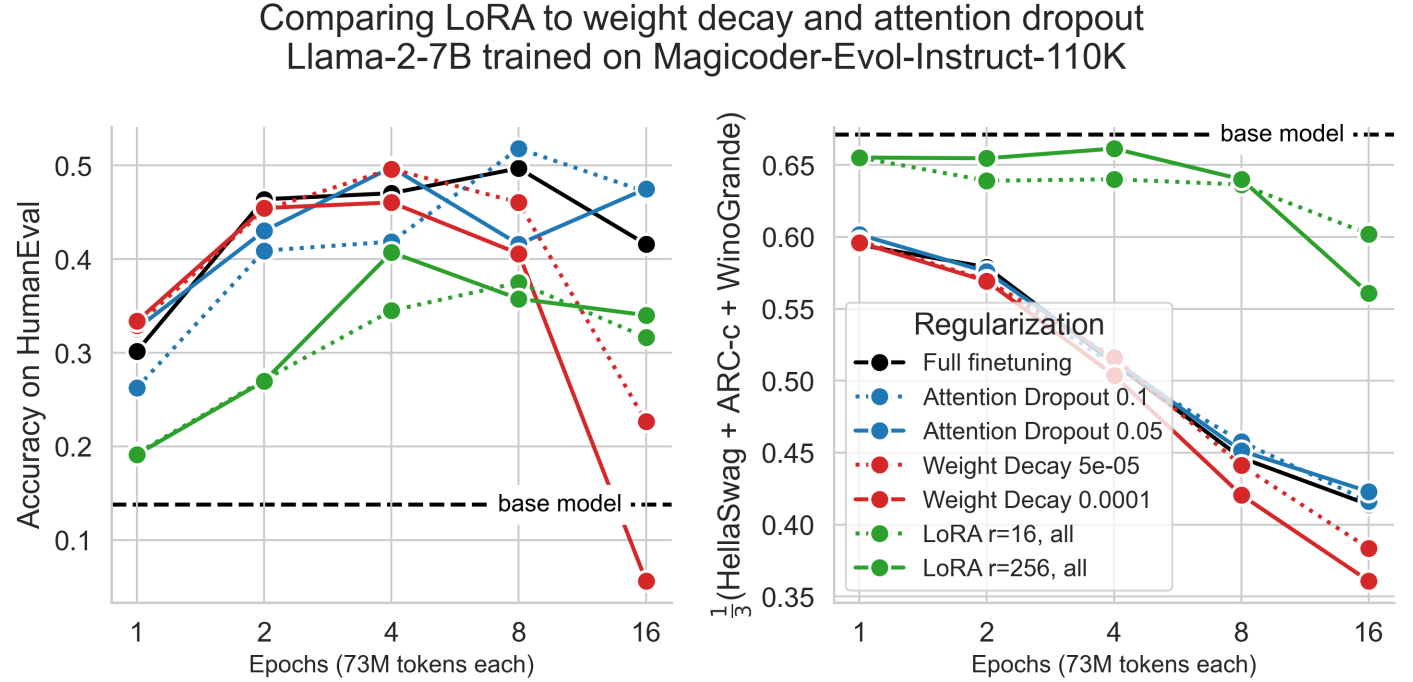
토큰의 다양성을 유지하는 데 도움이 된다.
Full finetuning on code and math does not learn low-rank perturbations
FFT에 대한 SVD를 통해 rank를 분석한다.
- LoRA보다 rank가 훨씬 높다.
- 많은 데이터를 학습할수록 rank가 증가한다.
- MLP가 attention보다 더 높은 rank를 갖는다.
- 처음과 마지막 레이어는 중반 레이어에 비해 낮은 rank를 갖는다.

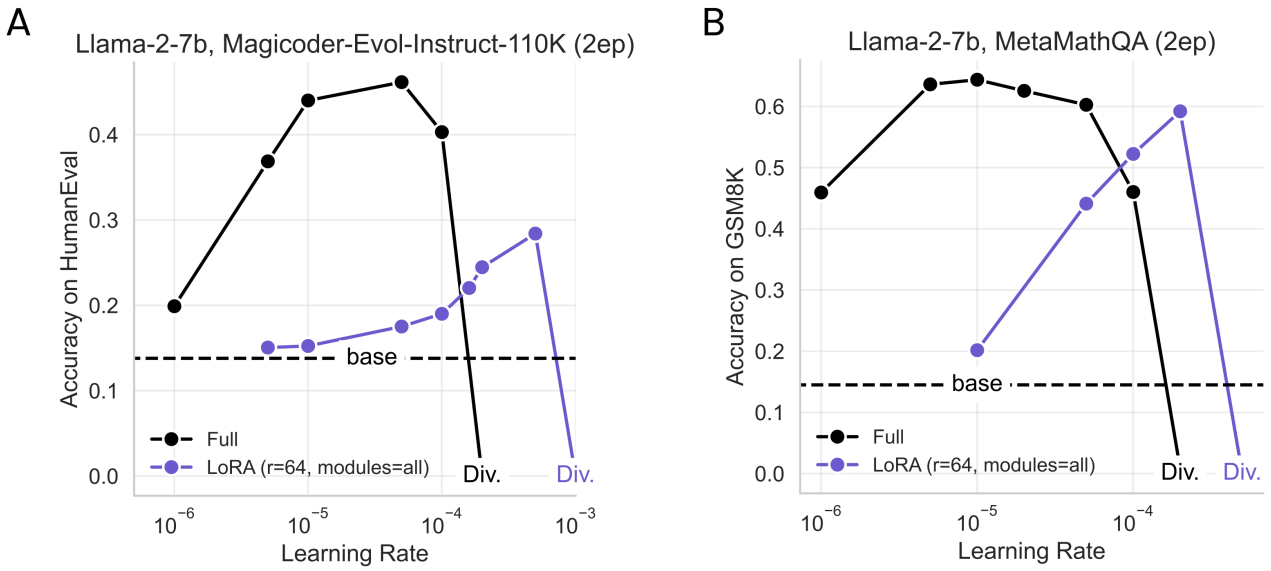
Practical takeaways for optimally configuring LoRA
LoRA는 학습률에 민감하다고 한...다?
(FFT는 상위 4개의 학습률에 대한 성능이 비슷비슷한데 LoRA는 상위 학습률 간 격차가 커서 그런 듯?)
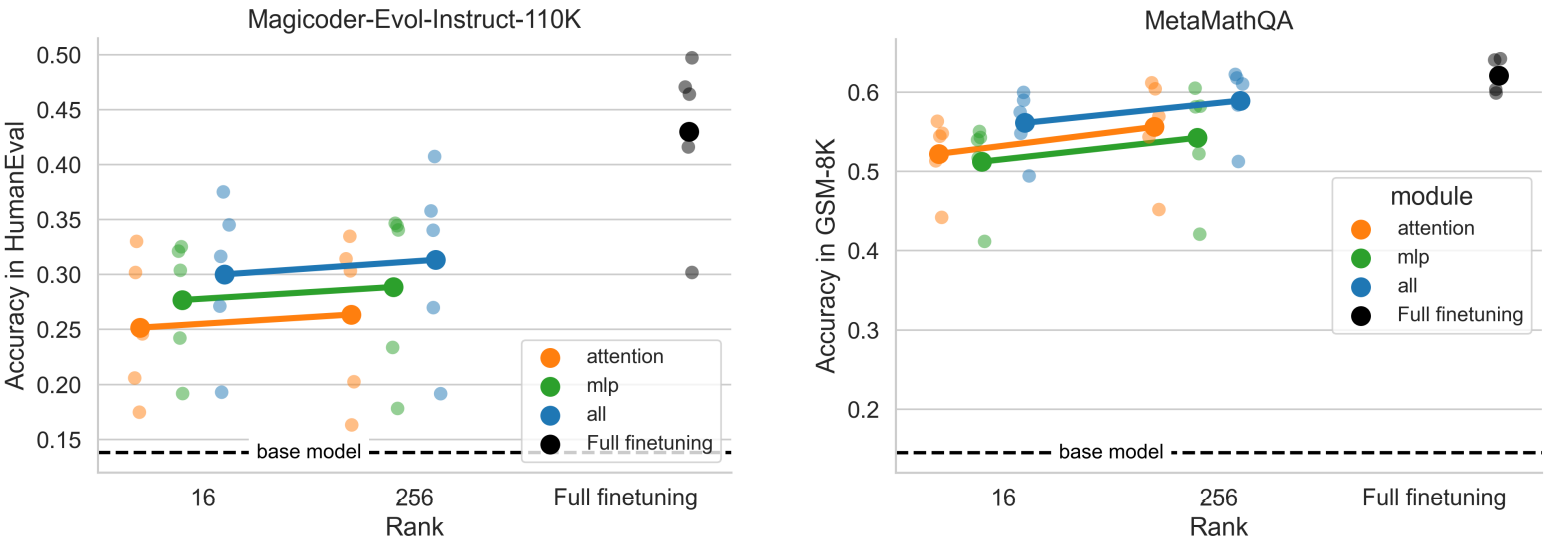
All LoRA의 성능이 좋다.
하지만 rank 간의 차이는 미미해 보여 계산 효율을 고려하면 낮은 rank를 채택하는 것이 좋아 보인다.
'논문 리뷰 > Language Model' 카테고리의 다른 글
| RLHF Workflow: From Reward Modeling to Online RLHF (0) | 2024.05.27 |
|---|---|
| MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning (0) | 2024.05.24 |
| Reducing Transformer Key-Value Cache Size with Cross-Layer Attention (0) | 2024.05.24 |
| Chameleon: Mixed-Modal Early-Fusion Foundation Models (1) | 2024.05.23 |
| Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models (0) | 2024.05.21 |
| xLSTM: Extended Long Short-Term Memory (0) | 2024.05.20 |



