Abstract
선호도 모델을 구성하고, 인간 피드백을 근사하고, online iterative RLHF에 대해 재현하기 쉽고 자세한 레시피를 제공하는 것이 목표
[arXiv](2024/05/13 version v1)
Introduction
강화학습 튜토리얼:
REINFORCE — a policy-gradient based reinforcement Learning algorithm
LLM을 정책 π로 간주하며, prompt x를 받아서 π(·|x)의 분포에서 응답 a를 생성한다.
π0는 정책의 초기 상태를 가리킨다.
RLHF의 핵심 구성요소는 다음과 같은 preference oracle이다.

일반적으로 다음과 같은 KL-regularized target 최적화 문제로 연구되며


Previous RLHF Algorithms and Their Challenges
이전의 RLHF framework는 2가지 범주로 나눌 수 있는데 PPO (Proximal Policy Optimization)를 사용한 Deep RL 기반 접근법, (offline) DPO (Direct Preference Optimization)가 그것이다.
DRL-based framework
먼저 보상 모델 r을 학습하고

PPO와 같은 방법을 적용하여 정규화된 보상을 최대화하도록 정책을 최적화한다.

Direct preference learning
보상 함수를 명시적으로 훈련하지 않고 선호도 데이터셋을 통해 직접 훈련한다.
본문은 이 DPO에 중점을 둔다.
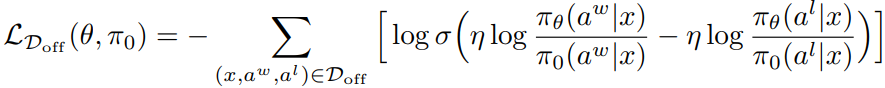
하지만 사전 훈련 데이터셋을 통해 훈련하는 offline RLHF는 최적의 정책을 학습할 수 없을 확률이 높다.
Online Iterative RLHF
학습 도중 현재 정책에서 prompt에 대한 응답을 샘플링하고 이에 대한 인간 선호도를 쿼리하여 훈련 세트에 추가한다.
이러한 방식으로 데이터셋을 꾸준히 업데이트하여 OOD 문제를 완화할 수 있다.
보상 모델이 정책보다 더 잘 일반화되기 때문에 인간 피드백 대신 대리 선호도 보상 모델을 훈련할 수 있다.
Reward Modeling as Human Feedback Approximation
BT model, Preference model을 훈련하는 방법 설명.

Bradley-Terry model construction
SFT 모델에서 마지막 레이어를 스칼라 점수를 예측하는 선형 헤드로 대체하고 훈련한다.

Preference model construction
Preference pair data는 다음과 같이 구성되며

LLM의 다음 토큰 예측 기능을 통해 두 응답 중 인간 선호도가 높은 응답 A을 예측하도록 훈련된다.

Iterative Policy Optimization
LLaMA-3-8B에 SFT를 수행하여 초기 정책을 도출한다.
2가지 agent를 사용하는 비대칭 구조를 특징으로 한다.
- Main agent
- Enhancer: 불확실성 정량화 함수 Γ를 기반으로 main agent와의 거리가 너무 멀지 않으면서 불확실성을 최대화하도록 결정된다. 간단하게 말하면 미개척지를 탐사하며 main agent를 보완하는 역할이다. Main agent의 훈련에는 영향을 끼치지 않고, 데이터 생성에만 이용된다.

Practical Implementation Details
Main agent 훈련에는 그 단순성 때문에 DPO를 채택.
Enhancer 쪽을 보면, 실제로 불확실성을 최대화하는 정책을 찾는 것이 쉽지 않다. 따라서 다른 구현 방법에 대해 논의.
- Adjusting Temperature and Training Steps: 다른 버전의 정책을 사용하거나 샘플링 온도를 조절하는 방법.
- Rejection Sampling: Main agent로 n개의 응답을 샘플링하고 가장 높은 보상/선호도를 얻은 응답을 enhancer의 최종 출력으로 간주한다. 이는 자동적으로 두 정책 간의 KL-divergence에 상한이 생기는 이점이 있다.
실제 구현에는 둘을 혼합한 방법을 사용했다.
Evaluation of the Model
훈련에는 open source data만 사용하였다.




