
Abstract
근거 순회 (traversal of rationale)라는 개념을 통해 LLM에 암시적으로 근거를 제공하여 이해 능력을 향상시키는 Meteor (Mamba-based traversal of rationales) 제안
[Github]
[arXiv](2024/05/27 version v2)
Introduction
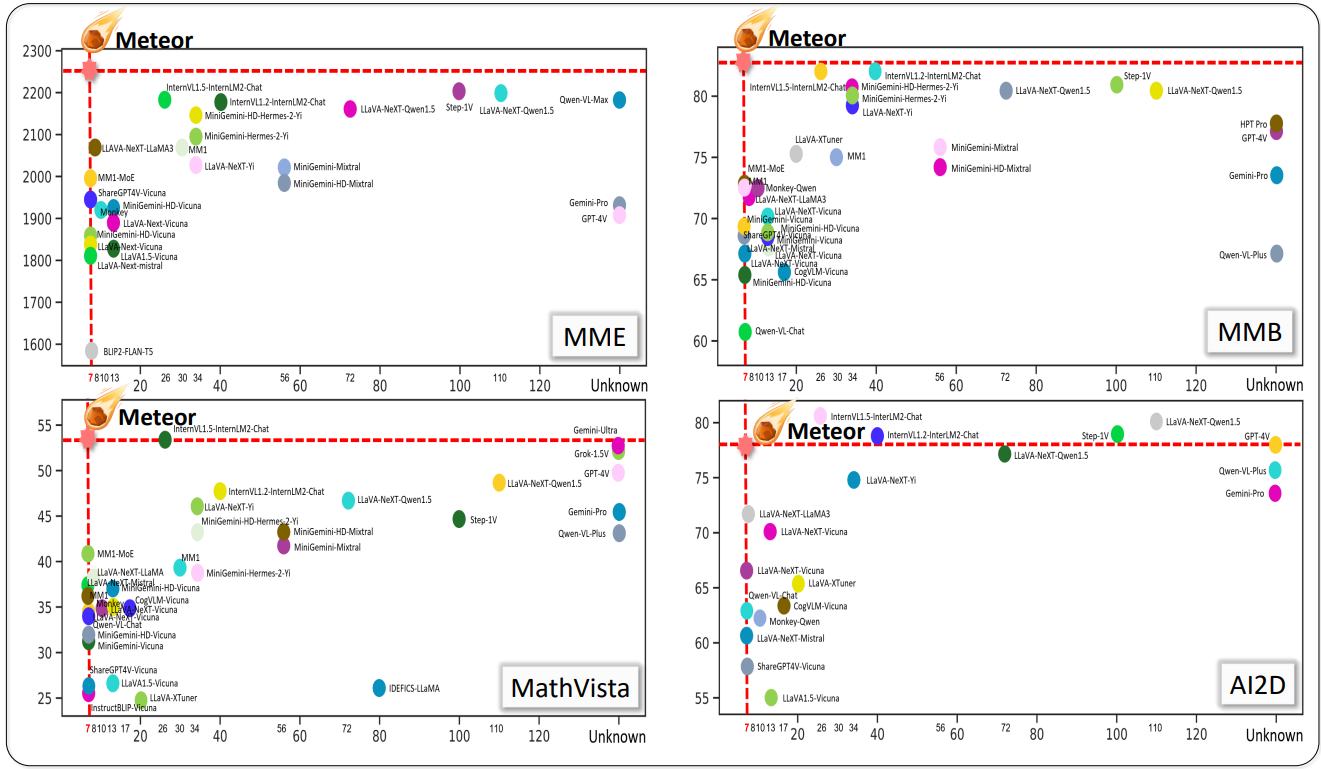
- Meteor는 근거 순회 (traversal of rationale)라는 개념 하에서 긴 순차적 근거를 이해하고 답을 도출할 수 있다.
- 효율적인 모델 크기 (7B)에도 불구하고 다양한 벤치마크에서 상당한 발전을 보여준다.
Meteor: Mamba-based traversal of rationale
Curating Rationale
수집한 2.1M Vision-Instruction QA datasetd에서 Claude가 QA를 바탕으로 근거를 생성하도록 한 뒤 GPT-4V를 통해 근거가 얼마나 잘 설명되었는지 필터링하여 1.1M의 QRA triple을 생성한다.
근거를 통합하여 매우 길어진 시퀀스를 효율적으로 처리하기 위해 Mamba를 채택하였다.
Model architecture
Vision, Tor projector = MLP,
Meteor-Mamba = Mamba 기반 130M architecture,
LLM = InternLM2-7B

Traversal of Rationale
LLM에 근거를 효과적으로 제공하기 위해 근거 순회라는 개념을 도입했다.
특수 토큰인 <tor>을 도입하고 근거 사이에 고정된 수의 <tor>을 균등하게 배치하여 Mamba에 입력한다.
단일 <tor> token은 긴 근거에 대해 제대로 작동하지 않으며 균등하게 분배하지 않으면 나중 토큰이 이전 토큰을 잘 참조하지 못하는 문제가 생긴다.
Training Strategy
1단계에서 Meteor는 <tor> 사이의 근거를 자기회귀적으로 생성하도록 훈련되며,
2단계에서는 QA만 활용하여 명시적인 근거 없이 질문에 대답할 수 있도록 한다.
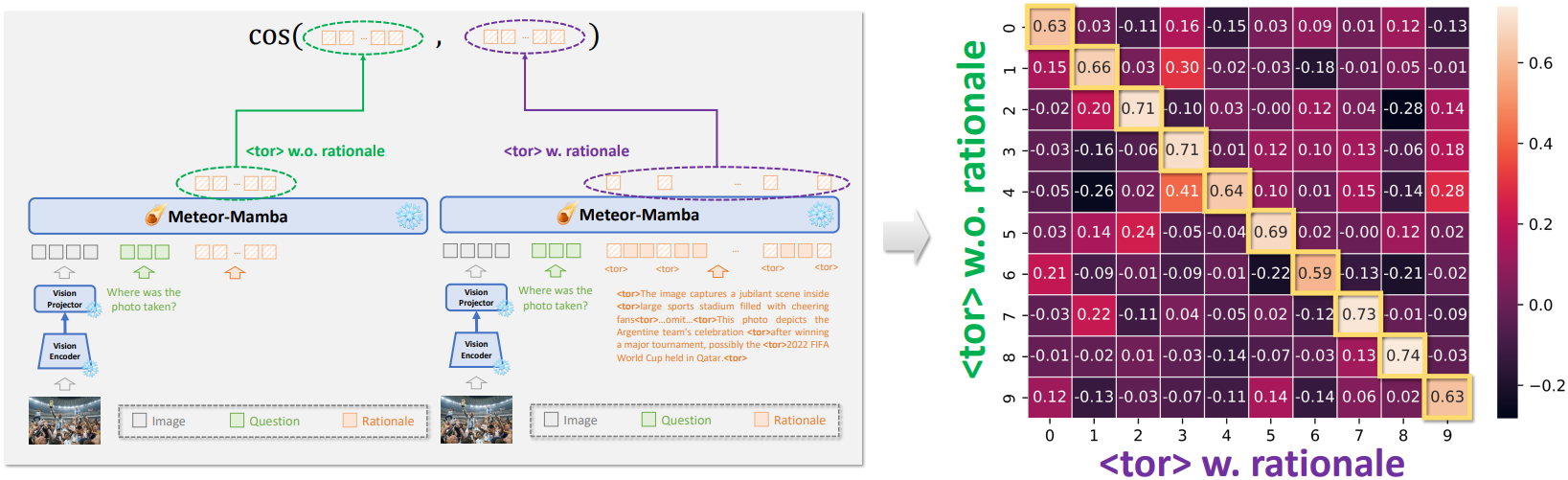
2단계 훈련은 근거를 포함하지 않고 <tor>만 전달하는데도 훈련이 잘 된다고? 라고 할 수 있다. 나도 그렇게 생각했다.
훈련된 Mamba의 <tor>은 근거가 있든 없든 유사도가 비슷하다고 한다.
Experiment
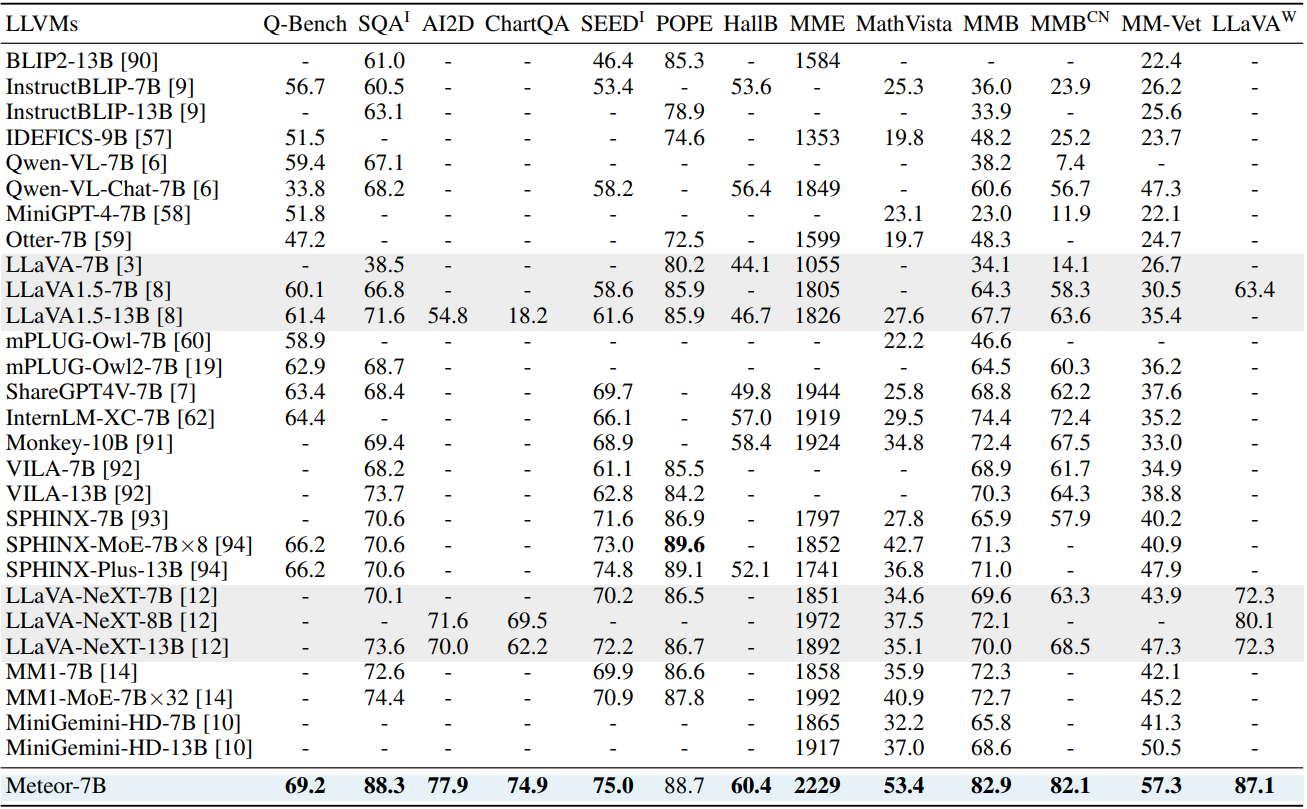
Benchmarks
Ablation




