Abstract
Long-context의 중간에 필요한 정보를 배치하고 훈련하는 In2 training을 통해 long-context에서의 성능 향상
[Github]
[arXiv](2024/04/26 version v2)
Introduction
연구진은 LLM이 긴 context의 중간에서 길을 잃는 원인이 훈련 데이터의 의도하지 않은 편향에서 비롯된다는 가설을 세웠다.
시스템 메시지는 context의 시작 부분에 표시되며 다음 토큰 예측에 대한 손실은 인근 토큰의 영향을 받을 확률이 크기 때문에 결과적으로 중요한 정보가 항상 context의 시작과 끝에 위치한다는 암시적 위치 편향을 도입할 수 있다.
Information-Intensive Training
Training Data Construction
In2 training의 목표는 context의 모든 위치에 중요한 정보가 존재할 수 있음을 명시적으로 가르치는 것이다.
데이터셋 D = {L, q, a}를 구축한다. 긴 context L과 질문, 답변이 있는 데이터이다.
원본 텍스트 C에서 128 token segment s를 추출하고 임의로 샘플링된 텍스트를 결합하여 긴 context를 만든다.
또한 GPT을 통해 s에 대한 QA를 생성하도록 한다.
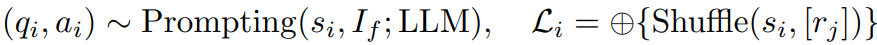
추가적으로 여러 개의 segment에 대한 QA를 생성한다.
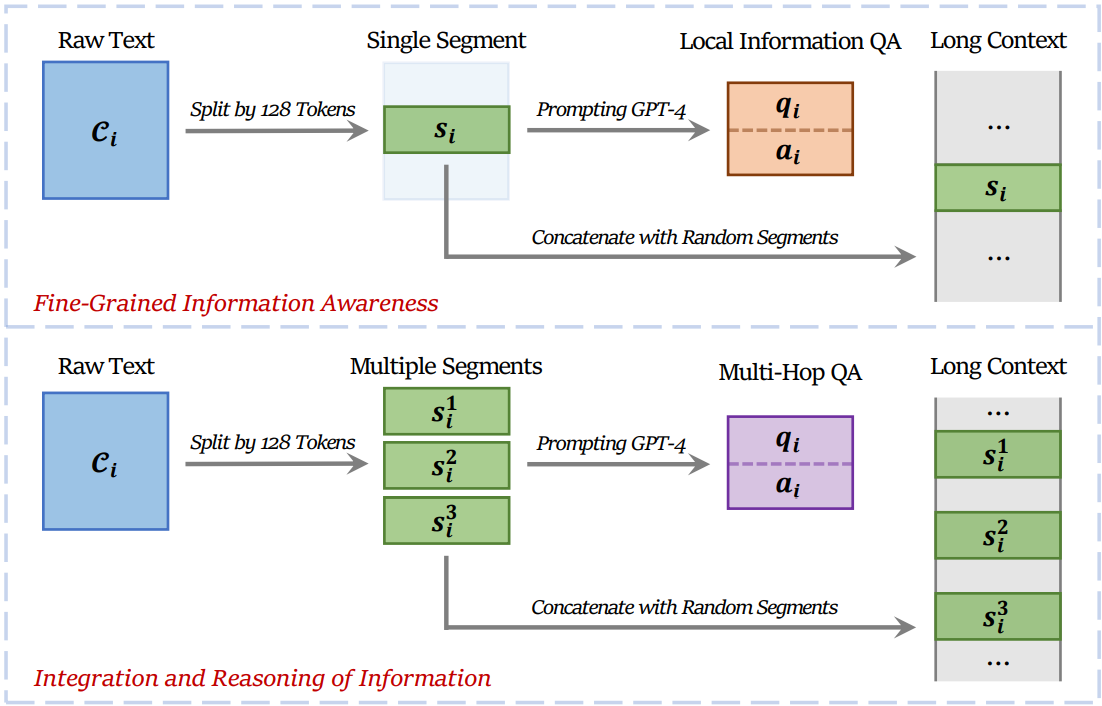
망각을 방지하기 위해 10%의 QA는 긴 context로 변환하지 않았으며 일반적인 instruction tuning 데이터도 추가했다.
Training Details
상기된 데이터셋을 통해 Mistral-7B-Instruct-v0.2 fine-tuning하여 FILM-7B(FILl-in-the-Middle)를 얻었다.
(Instruct-v0.2는 sliding window가 없는 버전이다.)
Long-Context Probing
Needle-in-the-Haystack 무용론을 펼쳤다.
- LLM이 매우 익숙한 doc-style context를 사용한다.
- Needle-in-the-Haystack의 정방향 검색 패턴은 작업의 어려움을 단순화할 수 있다.
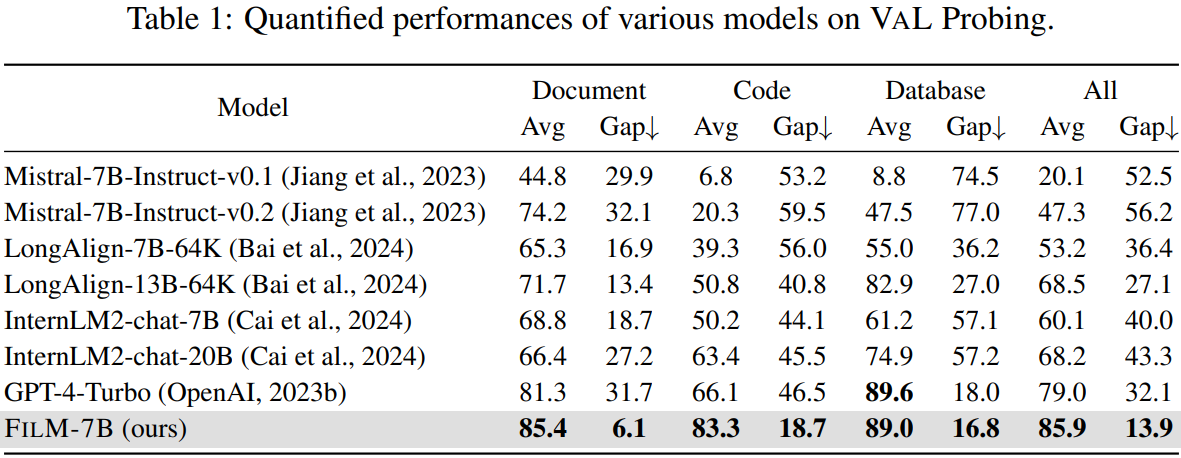
다양한 context style과 search pattern을 포함하는 VaL Probing을 제안한다.
VaL Probing
다양한 검색 패턴이 뭔가요?
예: 코드에서 특정 함수를 찾는 작업의 경우 함수의 이름이 정의보다 항상 앞에 있으므로 역방향 검색이라고 할 수 있다.
Experiments and Analysis
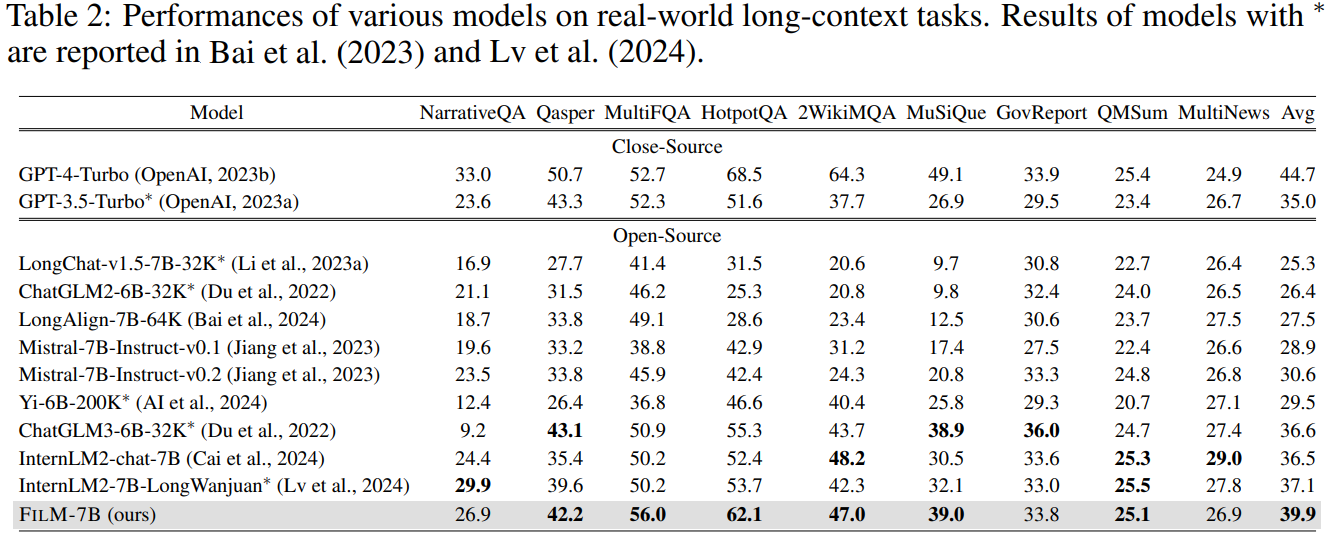
Long context 성능
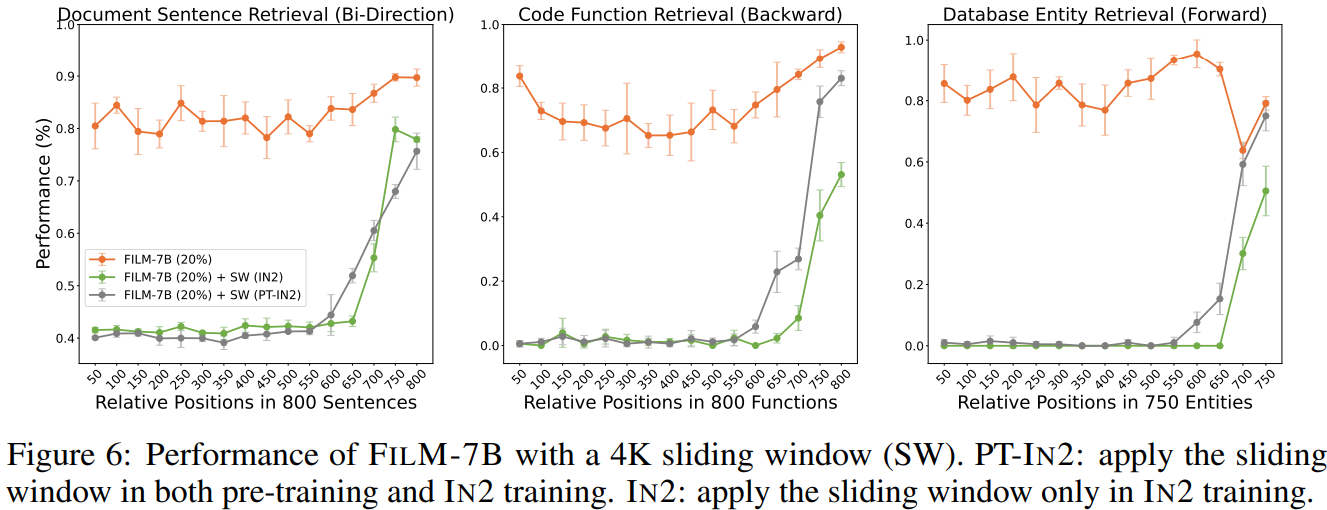
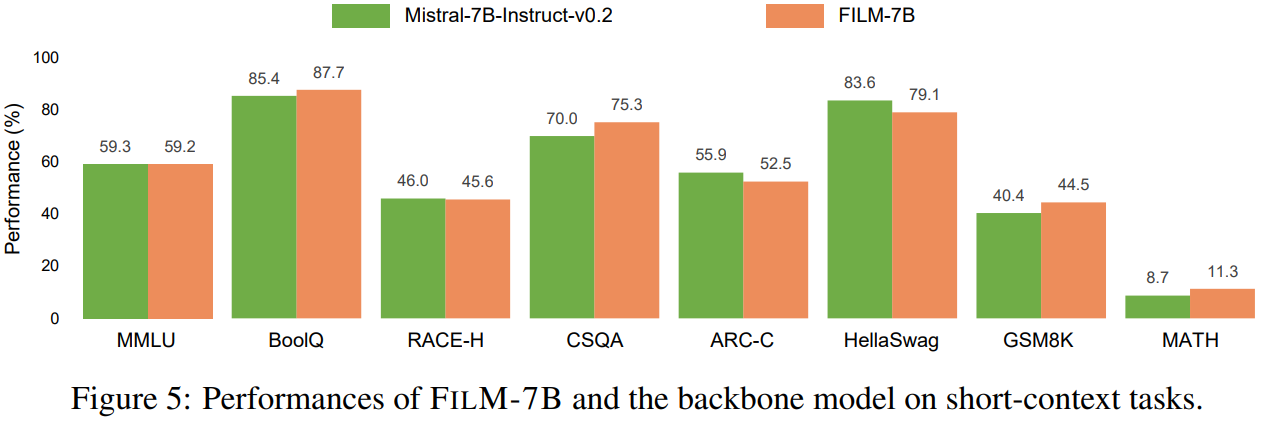
Short context에서도 성능이 뒤처지지 않는다.
Sliding window를 사용하면 long-context 성능이 크게 떨어진다.
또한 위치 인코딩은 RoPE를 사용하는 것이 좋다.